
Nouveautés concernant les produits
Améliorer le développement Android assisté par l'IA et les LLM avec Android Bench
Temps de lecture : 2 min


Nous voulons vous aider à créer des applications Android de haute qualité plus rapidement et plus facilement. Pour cela, nous mettons l'IA à votre disposition. Nous savons que vous souhaitez une IA qui comprenne réellement les nuances de la plate-forme Android. C'est pourquoi nous mesurons les performances des LLM pour les tâches de développement Android. Aujourd'hui, nous avons publié la première version de Android Bench, notre classement officiel des LLM pour le développement Android.
Notre objectif est de fournir aux créateurs de modèles un benchmark pour évaluer les capacités des LLM pour le développement Android. En établissant une base de référence claire et fiable pour le développement Android de haute qualité, nous aidons les créateurs de modèles à identifier les lacunes et à accélérer les améliorations. Les développeurs peuvent ainsi travailler plus efficacement avec un plus large éventail de modèles utiles pour l'assistance par IA. Cela se traduira à terme par des applications de meilleure qualité dans l'écosystème Android.
Conçu pour les tâches de développement Android réelles
Nous avons créé le benchmark en organisant un ensemble de tâches dans différents domaines de développement Android courants. Il est composé de défis réels de difficulté variable, provenant de dépôts GitHub Android publics. Les scénarios incluent la résolution de modifications majeures dans les versions Android, des tâches spécifiques à un domaine comme la mise en réseau sur les appareils connectés et la migration vers la dernière version de Jetpack Compose, pour n'en citer que quelques-uns.
Chaque évaluation tente de faire en sorte qu'un LLM corrige le problème signalé dans la tâche, que nous vérifions ensuite à l'aide de tests unitaires ou d'instrumentation. Cette approche indépendante du modèle nous permet de mesurer la capacité d'un modèle à naviguer dans des bases de code complexes, à comprendre les dépendances et à résoudre les types de problèmes que vous rencontrez tous les jours.
Nous avons validé cette méthodologie auprès de plusieurs fabricants de LLM, dont JetBrains.
“Mesurer l'impact de l'IA sur Android est un défi de taille. C'est donc formidable de voir un framework aussi solide et réaliste. Nous nous comparons activement à d'autres, mais Android Bench est un ajout unique et bienvenu. Cette méthodologie est exactement le type d'évaluation rigoureuse dont les développeurs Android ont besoin en ce moment.”
- Kirill Smelov, responsable des intégrations d'IA chez JetBrains.
Les premiers résultats d'Android Bench
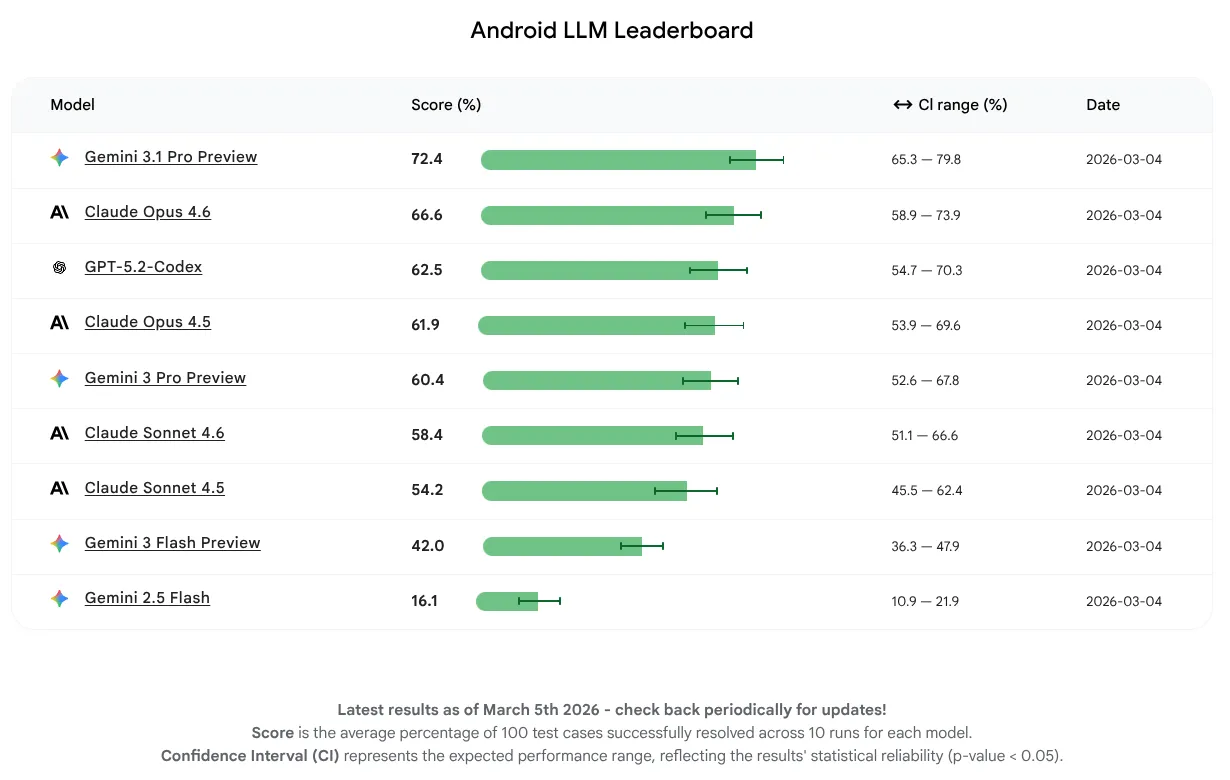
Pour cette première version, nous voulions mesurer uniquement les performances du modèle et ne pas nous concentrer sur l'utilisation d'agents ou d'outils. Les modèles ont réussi à effectuer 16 à 72% des tâches. Cette large plage montre que certains LLM disposent déjà d'une base solide de connaissances Android, tandis que d'autres ont plus de marge de progression. Quel que soit l'état actuel des modèles, nous prévoyons une amélioration continue, car nous encourageons les fabricants de LLM à améliorer leurs modèles pour le développement Android.
Le LLM ayant obtenu le score moyen le plus élevé pour cette première version est Gemini 3.1 Pro, suivi de près par Claude Opus 4.6. Vous pouvez essayer tous les modèles que nous avons évalués pour l'assistance par IA pour vos projets Android à l'aide de clés API dans la dernière version stable de Android Studio.
Offrir aux développeurs et aux fabricants de LLM une transparence totale
Nous accordons de l'importance à une approche ouverte et transparente. C'est pourquoi nous avons mis notre méthodologie, notre ensemble de données et notre test harness à la disposition du public sur GitHub.
L'un des défis de tout benchmark public est le risque de contamination des données, où les modèles peuvent avoir vu des tâches d'évaluation au cours de leur processus d'entraînement. Nous avons pris des mesures pour nous assurer que nos résultats reflètent un raisonnement authentique plutôt qu'une mémorisation ou une devinette, y compris un examen manuel approfondi des trajectoires des agents ou l'intégration d'une chaîne canary pour décourager l'entraînement.
À l'avenir, nous continuerons à faire évoluer notre méthodologie pour préserver l'intégrité de l'ensemble de données, tout en apportant des améliorations aux futures versions du benchmark, par exemple en augmentant la quantité et la complexité des tâches.
Nous sommes impatients de voir comment Android Bench peut améliorer l'assistance par IA à long terme. Notre vision est de combler le fossé entre le concept et le code de qualité. Nous préparons l'avenir pour que, quoi que vous imaginiez, vous puissiez le créer sur Android.
Écrit par :
Lire la suite
-

Nouveautés concernant les produits
Annoncé aujourd'hui lors de The Android Show, Android passe d'un système d'exploitation à un système d'intelligence, ce qui crée davantage d'opportunités d'interaction avec vos applications.
Matthew McCullough • Temps de lecture : 4 min
-

Nouveautés concernant les produits
Aujourd'hui, nous améliorons le développement Android avec Gemma 4, notre dernier modèle ouvert de pointe conçu avec des capacités de raisonnement complexes et d'appel d'outils autonomes.
Matthew McCullough • Temps de lecture : 2 min
-

Nouveautés concernant les produits
Android 17 a officiellement atteint la stabilité de la plate-forme aujourd'hui avec la version bêta 3. Cela signifie que la surface de l'API est verrouillée. Vous pouvez effectuer les tests de compatibilité finaux et envoyer vos applications ciblant Android 17 sur le Play Store.
Matthew McCullough • Temps de lecture : 5 min
Restez informé
Recevez chaque semaine les dernières informations sur le développement Android dans votre boîte de réception.
