
ข่าวสารผลิตภัณฑ์
ยกระดับการพัฒนา Android ที่มี AI ช่วยและปรับปรุง LLM ด้วย Android Bench
ใช้เวลาอ่าน 2 นาที


เราต้องการช่วยให้คุณสร้างแอป Android คุณภาพสูงได้เร็วขึ้นและง่ายขึ้น และวิธีหนึ่งที่เราใช้เพื่อช่วยให้คุณมีประสิทธิภาพการทำงานมากขึ้นคือการนำ AI มาไว้ที่ปลายนิ้วของคุณ เราทราบว่าคุณต้องการ AI ที่เข้าใจความแตกต่างของแพลตฟอร์ม Android อย่างแท้จริง เราจึงวัดประสิทธิภาพของ LLM ในการทำงานด้านการพัฒนา Android วันนี้เราได้เปิดตัว Android Bench เวอร์ชันแรก ซึ่งเป็นตารางจัดอันดับอย่างเป็นทางการของ LLM สำหรับการพัฒนา Android
เป้าหมายของเราคือการให้เกณฑ์มาตรฐานแก่ผู้สร้างโมเดลเพื่อประเมินความสามารถของ LLM สำหรับการพัฒนา Android การกำหนดเกณฑ์พื้นฐานที่ชัดเจนและเชื่อถือได้สำหรับลักษณะของการพัฒนา Android คุณภาพสูงจะช่วยให้ผู้สร้างโมเดลระบุช่องว่างและเร่งการปรับปรุงได้ ซึ่งจะช่วยให้นักพัฒนาแอปทำงานได้อย่างมีประสิทธิภาพมากขึ้นด้วยโมเดลที่เป็นประโยชน์ที่หลากหลายมากขึ้นเพื่อเลือกใช้รับความช่วยเหลือจาก AI ซึ่งท้ายที่สุดจะนำไปสู่แอปที่มีคุณภาพสูงขึ้นในระบบนิเวศของ Android
ออกแบบมาสำหรับงานพัฒนา Android ในโลกแห่งความเป็นจริง
เราสร้างการเปรียบเทียบโดยการดูแลชุดงานที่เกี่ยวข้องกับพื้นที่การพัฒนา Android ทั่วไป โดยประกอบด้วยโจทย์จริงที่มีความยากแตกต่างกัน ซึ่งมาจากที่เก็บ Android ของ GitHub แบบสาธารณะ สถานการณ์ต่างๆ ได้แก่ การแก้ไขการเปลี่ยนแปลงที่ทำให้เกิดข้อขัดข้องใน Android แต่ละรุ่น งานเฉพาะโดเมน เช่น การเชื่อมต่อเครือข่ายในอุปกรณ์ที่สวมใส่ได้ และการย้ายข้อมูลไปยัง Jetpack Compose เวอร์ชันล่าสุด เป็นต้น
การประเมินแต่ละครั้งจะพยายามให้ LLM แก้ไขปัญหาที่รายงานในงาน จากนั้นเราจะยืนยันโดยใช้การทดสอบหน่วยหรือการทดสอบเครื่องมือ แนวทางที่ไม่ขึ้นอยู่กับโมเดลนี้ช่วยให้เราวัดความสามารถของโมเดลในการไปยังฐานของโค้ดที่ซับซ้อน ทำความเข้าใจทรัพยากร Dependency และแก้ปัญหาที่คุณพบเจอทุกวันได้
เราได้ตรวจสอบความถูกต้องของวิธีการนี้กับผู้สร้าง LLM หลายราย รวมถึง JetBrains
การวัดผลกระทบของ AI ใน Android เป็นความท้าทายที่ยิ่งใหญ่ ดังนั้นจึงเป็นเรื่องน่ายินดีที่ได้เห็นเฟรมเวิร์กที่สมเหตุสมผลและสมจริงเช่นนี้ แม้ว่าเราจะเปรียบเทียบตัวเองอย่างต่อเนื่อง แต่ Android Bench ก็เป็นเครื่องมือที่พิเศษและเป็นที่น่ายินดี วิธีการนี้เป็นการประเมินอย่างเข้มงวดที่นักพัฒนาแอป Android ต้องการในตอนนี้"
- Kirill Smelov หัวหน้าฝ่ายการผสานรวม AI ที่ JetBrains
ผลการทดสอบ Android Bench ครั้งแรก
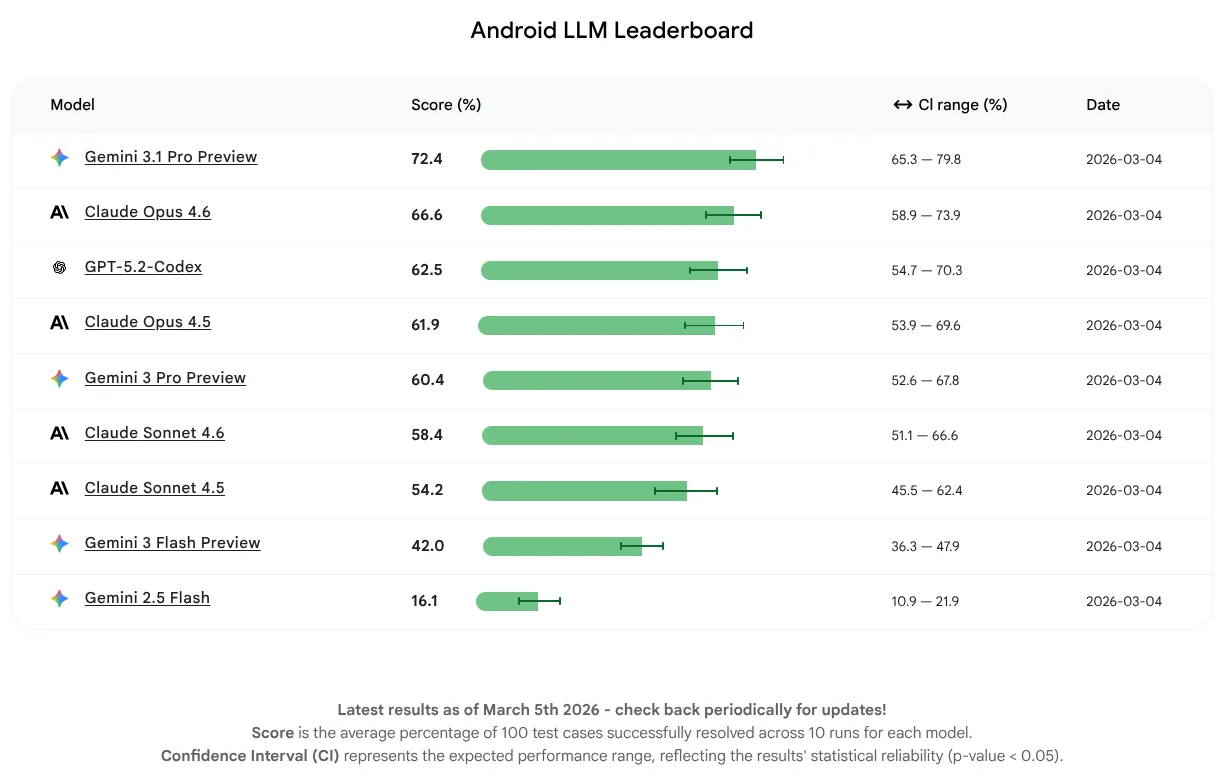
สำหรับการเปิดตัวครั้งแรกนี้ เราต้องการวัดประสิทธิภาพของโมเดลอย่างแท้จริง และไม่ได้มุ่งเน้นที่การใช้เอเจนต์หรือเครื่องมือ โมเดลสามารถทำงานให้เสร็จสมบูรณ์ได้ 16-72% ช่วงนี้เป็นช่วงกว้างที่แสดงให้เห็นว่า LLM บางรุ่นมีพื้นฐานความรู้เกี่ยวกับ Android ที่แข็งแกร่งอยู่แล้ว ในขณะที่รุ่นอื่นๆ ยังมีโอกาสปรับปรุงได้อีก ไม่ว่าโมเดลจะอยู่ที่ใดในตอนนี้ เราคาดหวังว่าจะมีการปรับปรุงอย่างต่อเนื่องในขณะที่เราสนับสนุนให้ผู้สร้าง LLM ปรับปรุงโมเดลของตนสำหรับการพัฒนา Android
LLM ที่มีคะแนนเฉลี่ยสูงสุดสำหรับการเปิดตัวครั้งแรกนี้คือ Gemini 3.1 Pro ตามมาด้วย Claude Opus 4.6 คุณลองใช้โมเดลทั้งหมดที่เราประเมินเพื่อรับความช่วยเหลือจาก AI สำหรับโปรเจ็กต์ Android ได้โดยใช้คีย์ API ใน Android Studio เวอร์ชันเสถียรล่าสุด
การให้ความโปร่งใสแก่นักพัฒนาแอปและผู้สร้าง LLM
เราให้ความสำคัญกับแนวทางที่เปิดกว้างและโปร่งใส จึงได้เผยแพร่ระเบียบวิธี ชุดข้อมูล และชุดทดสอบต่อสาธารณะใน GitHub
ความท้าทายอย่างหนึ่งของเกณฑ์มาตรฐานสาธารณะคือความเสี่ยงของการปนเปื้อนของข้อมูล ซึ่งโมเดลอาจเห็นงานประเมินในระหว่างกระบวนการฝึก เราได้ใช้มาตรการเพื่อให้มั่นใจว่าผลลัพธ์ของเราแสดงถึงการให้เหตุผลที่แท้จริง ไม่ใช่การจดจำหรือการคาดเดา ซึ่งรวมถึงการตรวจสอบเส้นทางการทำงานของเอเจนต์อย่างละเอียดด้วยตนเอง หรือการผสานรวมสตริง Canary เพื่อไม่ให้มีการฝึก
ในอนาคต เราจะยังคงพัฒนาวิธีการของเราต่อไปเพื่อรักษาความสมบูรณ์ของชุดข้อมูล พร้อมทั้งปรับปรุงการเผยแพร่เกณฑ์มาตรฐานในอนาคต เช่น การเพิ่มปริมาณและความซับซ้อนของงาน
เราหวังว่า Android Bench จะช่วยปรับปรุงการช่วยเหลือของ AI ในระยะยาวได้ วิสัยทัศน์ของเราคือการปิดช่องว่างระหว่างแนวคิดกับโค้ดคุณภาพ เรากำลังวางรากฐานสำหรับอนาคตที่ให้คุณสร้างสรรค์ทุกสิ่งที่จินตนาการได้บน Android
เขียนโดย
อ่านต่อ
-

ข่าวสารผลิตภัณฑ์
Google I/O '26 มีการประกาศสำคัญ 17 รายการสำหรับนักพัฒนาแอป Android โดยมุ่งเน้นที่ประสิทธิภาพการทำงานที่นำโดยเอเจนต์, Compose First เป็นมาตรฐาน UI และสื่อประสิทธิภาพสูงและการพัฒนาแบบปรับเปลี่ยนได้สำหรับระบบนิเวศที่ขยายตัว
Matthew McCullough • ใช้เวลาอ่าน 8 นาที
-

ข่าวสารผลิตภัณฑ์
Android กำลังเปลี่ยนจากระบบปฏิบัติการไปเป็นระบบอัจฉริยะ ซึ่งจะสร้างโอกาสในการมีส่วนร่วมกับแอปของคุณมากขึ้น โดยเราได้ประกาศเรื่องนี้ใน The Android Show วันนี้
Matthew McCullough • ใช้เวลาอ่าน 4 นาที
-

ข่าวสารผลิตภัณฑ์
วันนี้เราจะยกระดับการพัฒนา Android ด้วย Gemma 4 ซึ่งเป็นโมเดลโอเพนซอร์สที่ล้ำสมัยที่สุดของเราที่ออกแบบมาพร้อมความสามารถในการให้เหตุผลที่ซับซ้อนและการเรียกใช้เครื่องมือแบบอัตโนมัติ
Matthew McCullough • ใช้เวลาอ่าน 2 นาที
รับข่าวสาร
รับข้อมูลเชิงลึกด้านการพัฒนาแอป Android ล่าสุดส่งตรงถึงกล่องจดหมายของคุณทุกสัปดาห์
