



El equipo de Android Runtime (ART) ha reducido el tiempo de compilación en un 18% sin comprometer el código compilado ni ninguna regresión de memoria máxima. Esta mejora formaba parte de nuestra iniciativa del 2025 para reducir el tiempo de compilación sin sacrificar el uso de memoria ni la calidad del código compilado.
Optimizar la velocidad de compilación es fundamental para ART. Por ejemplo, cuando la compilación justo a tiempo (JIT) afecta directamente a la eficiencia de las aplicaciones y al rendimiento general del dispositivo. Las compilaciones más rápidas reducen el tiempo que transcurre antes de que se activen las optimizaciones, lo que se traduce en una experiencia de usuario más fluida y con mayor capacidad de respuesta. Además, tanto en la compilación JIT como en la AOT, las mejoras en la velocidad de compilación se traducen en un menor consumo de recursos durante el proceso de compilación, lo que beneficia a la duración de la batería y a la temperatura del dispositivo, especialmente en los dispositivos de gama baja.
Algunas de estas mejoras de velocidad en tiempo de compilación se lanzaron en la versión de Android de junio del 2025, y el resto estará disponible en la versión de Android de finales de año. Además, todos los usuarios de Android con versiones 12 y posteriores pueden recibir estas mejoras mediante actualizaciones de Mainline.
Optimizar el compilador de optimización
Optimizar un compilador siempre es un juego de concesiones. No puedes conseguir velocidad sin coste económico, tienes que renunciar a algo. Nos propusimos un objetivo muy claro y ambicioso: hacer que el compilador fuera más rápido, pero sin introducir regresiones de memoria y, lo que es más importante, sin reducir la calidad del código que produce. Si el compilador es más rápido, pero las aplicaciones se ejecutan más lentamente, no habremos conseguido nuestro objetivo.
El único recurso que estábamos dispuestos a invertir era nuestro propio tiempo de desarrollo para investigar en profundidad y encontrar soluciones inteligentes que cumplieran estos estrictos criterios. Vamos a analizar más detenidamente cómo trabajamos para identificar áreas de mejora y encontrar las soluciones adecuadas a los distintos problemas.
Encontrar posibles optimizaciones que merezcan la pena
Antes de empezar a optimizar una métrica, debe poder medirla. De lo contrario, nunca podrás saber si has mejorado o no. Por suerte, la velocidad de tiempo de compilación es bastante constante siempre que tomes algunas precauciones, como usar el mismo dispositivo que usas para medir antes y después de un cambio, y asegurarte de que tu dispositivo no se acelere térmicamente. Además, también tenemos mediciones deterministas, como las estadísticas del compilador, que nos ayudan a entender lo que ocurre.
Como el recurso que estábamos sacrificando para llevar a cabo estas mejoras era nuestro tiempo de desarrollo, queríamos poder iterar lo más rápido posible. Esto significaba que teníamos que elegir un puñado de aplicaciones representativas (una mezcla de aplicaciones propias, aplicaciones de terceros y el propio sistema operativo Android) para crear prototipos de soluciones. Más adelante, verificamos que la implementación final merecía la pena mediante pruebas manuales y automatizadas de forma generalizada.
Con ese conjunto de APKs seleccionados, activamos una compilación manual de forma local, obtenemos un perfil de la compilación y usamos pprof para visualizar en qué estamos invirtiendo nuestro tiempo.
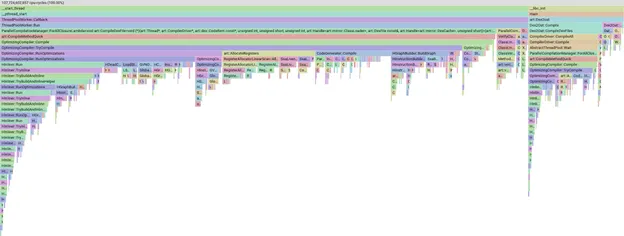
Ejemplo de un gráfico tipo llamas de un perfil en pprof
La herramienta pprof es muy potente y nos permite segmentar, filtrar y ordenar los datos para ver, por ejemplo, qué fases o métodos del compilador ocupan la mayor parte del tiempo. No vamos a entrar en detalles sobre pprof, pero debes saber que, si la barra es más grande, significa que ha llevado más tiempo compilar.
Una de estas vistas es la "de abajo arriba", en la que puedes ver qué métodos ocupan la mayor parte del tiempo. En la imagen de abajo podemos ver un método llamado Kill, que representa más del 1% del tiempo de compilación. También hablaremos de otros métodos principales más adelante en la entrada del blog.
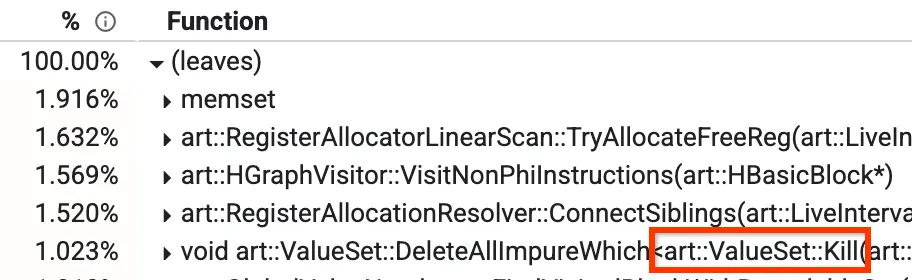
Vista desde abajo de un perfil
En nuestro compilador de optimización, hay una fase llamada Numeración Global de Valores (GVN). No tienes que preocuparte por lo que hace en su conjunto, pero lo importante es saber que tiene un método llamado `Kill` que eliminará algunos nodos según un filtro. Esto lleva mucho tiempo, ya que tiene que iterar en todos los nodos y comprobarlos uno a uno. Hemos observado que hay algunos casos en los que sabemos de antemano que la comprobación será falsa, independientemente de los nodos que tengamos activos en ese momento. En estos casos, podemos saltarnos la iteración por completo, lo que reduce el porcentaje del 1,023% a aproximadamente el 0,3% y mejora el tiempo de ejecución de GVN en torno al 15%.
Implementar optimizaciones que merezcan la pena
Hemos visto cómo medir y detectar dónde se invierte el tiempo, pero esto es solo el principio. El siguiente paso es optimizar el tiempo de compilación.
Normalmente, en un caso como el de `Kill` de arriba, analizaríamos cómo iteramos a través de los nodos y lo haríamos más rápido, por ejemplo, haciendo las cosas en paralelo o mejorando el propio algoritmo. De hecho, eso es lo que intentamos al principio, y solo cuando no encontramos nada que hacer, tuvimos un momento de reflexión y nos dimos cuenta de que la solución era (en algunos casos) no iterar. Cuando se realizan este tipo de optimizaciones, es fácil no ver el bosque por los árboles.
En otros casos, hemos utilizado varias técnicas, entre las que se incluyen las siguientes:
- Usar heurísticas para decidir si una optimización no va a producir resultados que merezcan la pena y, por lo tanto, se puede omitir.
- usando estructuras de datos adicionales para almacenar en caché los datos calculados
- cambiar las estructuras de datos actuales para aumentar la velocidad
- Calcula los resultados de forma diferida para evitar ciclos en algunos casos.
- Usa la abstracción adecuada: las funciones innecesarias pueden ralentizar el código.
- Evitar que un puntero que se usa con frecuencia se persiga a través de muchas cargas
¿Cómo sabemos si merece la pena aplicar las optimizaciones?
Esa es la parte buena, que no tienes que hacerlo. Después de detectar que un área consume mucho tiempo de compilación y de dedicar tiempo de desarrollo a intentar mejorarla, a veces no se encuentra una solución. Puede que no haya nada que hacer, que se tarde demasiado en implementar, que se produzca un retroceso significativo en otra métrica, que aumente la complejidad de la base de código, etc. Por cada optimización que se haya llevado a cabo con éxito y que puedas ver en esta entrada de blog, ten en cuenta que hay muchas otras que no han dado sus frutos.
Si te encuentras en una situación similar, intenta estimar cuánto vas a mejorar la métrica haciendo el mínimo trabajo posible. Esto significa, por orden:
- Hacer una estimación con las métricas que ya ha recogido o simplemente con su intuición
- Hacer estimaciones con un prototipo rápido y sencillo
- Implementa una solución.
No olvides estimar los inconvenientes de tu solución. Por ejemplo, si vas a usar estructuras de datos adicionales, ¿cuánta memoria estás dispuesto a usar?
En profundidad
Sin más preámbulos, veamos algunos de los cambios que hemos implementado.
Hemos implementado un cambio para optimizar un método llamado FindReferenceInfoOf. Este método realizaba una búsqueda lineal de un vector para encontrar una entrada. Hemos actualizado esa estructura de datos para que se indexe por el ID de la instrucción, de modo que FindReferenceInfoOf sea O(1) en lugar de O(n). Además, hemos preasignado el vector para evitar que se cambie su tamaño. Hemos aumentado ligeramente la memoria, ya que hemos tenido que añadir un campo adicional que contabilizaba cuántas entradas insertábamos en el vector, pero ha sido un pequeño sacrificio, ya que la memoria máxima no ha aumentado. Esto ha acelerado nuestra fase LoadStoreAnalysis entre un 34 y un 66 %, lo que a su vez supone una mejora del tiempo de compilación de entre un 0,5 y un 1,8 %.
Tenemos una implementación personalizada de HashSet que usamos en varios sitios. Crear esta estructura de datos nos llevaba mucho tiempo y descubrimos por qué. Hace muchos años, esta estructura de datos solo se usaba en unos pocos lugares que utilizaban conjuntos de hash muy grandes, y se modificó para optimizarla. Sin embargo, hoy en día se usa en la dirección opuesta, con solo unas pocas entradas y una vida útil corta. Esto significaba que estábamos desperdiciando ciclos al crear este enorme HashSet, pero solo lo usábamos para unas pocas entradas antes de descartarlo. Con este cambio, hemos mejorado el tiempo de compilación en torno al 1,3-2 %. Además, el uso de memoria se redujo entre un 0,5 y un 1% aproximadamente, ya que no usábamos estructuras de datos tan grandes como antes.
Hemos mejorado el tiempo de compilación en un 0,5-1% pasando estructuras de datos por referencia a la lambda para evitar copiarlas. Se nos pasó por alto en la revisión original y ha estado en nuestra base de código durante años. Gracias a los perfiles de pprof, nos dimos cuenta de que estos métodos creaban y destruían muchas estructuras de datos, lo que nos llevó a investigarlos y optimizarlos.
Hemos acelerado la fase que escribe el resultado compilado almacenando en caché los valores calculados, lo que se ha traducido en una mejora de entre el 1,3 y el 2,8% del tiempo total de compilación. Lamentablemente, la contabilidad adicional era excesiva y nuestras pruebas automatizadas nos alertaron de la regresión de la memoria. Más adelante, volvimos a analizar el mismo código e implementamos una nueva versión que no solo solucionó el problema de regresión de memoria, sino que también mejoró el tiempo de compilación en un 0,5-1,8 % más. En este segundo cambio, tuvimos que refactorizar y replantearnos cómo debía funcionar esta fase para eliminar una de las dos estructuras de datos.
Tenemos una fase en nuestro compilador de optimización que inserta llamadas a funciones para mejorar el rendimiento. Para elegir qué métodos vamos a insertar, usamos tanto heurísticas antes de hacer ningún cálculo como comprobaciones finales después de hacer el trabajo, pero justo antes de finalizar la inserción. Si alguno de ellos detecta que no merece la pena insertar el código (por ejemplo, si se añadieran demasiadas instrucciones nuevas), no insertaremos el código de la llamada al método.
Hemos movido dos comprobaciones de la categoría "Comprobaciones finales" a la categoría "Heurística" para estimar si una inserción se realizará correctamente o no antes de llevar a cabo cualquier cálculo que requiera mucho tiempo. Como se trata de una estimación, no es perfecta, pero hemos verificado que nuestras nuevas heurísticas cubren el 99,9% de lo que se insertaba antes sin afectar al rendimiento. Una de estas nuevas heurísticas se refería a los registros DEX necesarios (una mejora de entre el 0,2 % y el 1,3 %), y la otra, al número de instrucciones (una mejora del 2 %).
Tenemos una implementación personalizada de BitVector que usamos en varios sitios. Hemos sustituido la clase BitVector redimensionable por una clase BitVectorView más sencilla para determinados vectores de bits de tamaño fijo. De esta forma, se eliminan algunas indirecciones y comprobaciones de intervalos en tiempo de ejecución, y se acelera la creación de los objetos de vector de bits.
Además, la clase BitVectorView se ha convertido en una plantilla del tipo de almacenamiento subyacente (en lugar de usar siempre uint32_t como el antiguo BitVector). Esto permite que algunas operaciones, como Union(), procesen el doble de bits a la vez en plataformas de 64 bits. Las muestras de las funciones afectadas se redujeron en más de un 1% en total al compilar el SO Android. Esto se ha hecho en varios cambios [1, 2, 3, 4, 5, 6]
Si habláramos en detalle de todas las optimizaciones, estaríamos aquí todo el día. Si te interesan otras optimizaciones, echa un vistazo a otros cambios que hemos implementado:
- Añade la contabilidad para mejorar los tiempos de compilación en un 0,6-1,6%.
- Calcula los datos de forma diferida para evitar ciclos, si es posible.
- Refactorizar el código para omitir el trabajo de precomputación cuando no se vaya a usar.
- Evita algunas cadenas de carga dependientes cuando el asignador se pueda obtener fácilmente de otros lugares.
- Otro caso de añadir una comprobación para evitar trabajo innecesario.
- Evita la ramificación frecuente en el tipo de registro (principal o FP) en el asignador de registros.
- Asegúrate de que algunas matrices se inicialicen en tiempo de compilación. No confíes en clang para hacerlo.
- Limpia algunos bucles. Usa bucles de intervalo que Clang pueda optimizar mejor, ya que no necesita volver a cargar los punteros internos del contenedor debido a los efectos secundarios del bucle. Evita llamar a la función virtual `HInstruction::GetInputRecords()` en el bucle a través de `InputAt(.)` insertado para cada entrada.
- Evita las funciones Accept() para el patrón de visitante aprovechando una optimización del compilador.
Conclusión
Nuestra dedicación a mejorar la velocidad de compilación de ART ha dado lugar a mejoras significativas, lo que ha hecho que Android sea más fluido y eficiente, además de contribuir a que la batería dure más y a que los dispositivos no se calienten tanto. Al identificar e implementar optimizaciones de forma diligente, hemos demostrado que se pueden conseguir mejoras sustanciales en el tiempo de compilación sin sacrificar el uso de memoria ni la calidad del código.
En nuestro proceso, hemos usado herramientas de creación de perfiles como pprof, hemos estado dispuestos a repetir el proceso y, en ocasiones, hemos abandonado las vías menos fructíferas. El esfuerzo colectivo del equipo de ART no solo ha reducido el tiempo de compilación en un porcentaje considerable, sino que también ha sentado las bases para futuros avances.
Todas estas mejoras están disponibles en la actualización de Android de finales del 2025 y en Android 12 y versiones posteriores a través de las actualizaciones de Mainline. Esperamos que este análisis detallado de nuestro proceso de optimización te proporcione información valiosa sobre las complejidades y las ventajas de la ingeniería de compiladores.
Escrito por:
Seguir leyendo
-


Noticias sobre productos
Nos complace anunciar importantes actualizaciones de nuestros recursos de diseño, que te ofrecen la guía completa que necesitas para crear aplicaciones Android adaptables y de alta calidad en todos los factores de forma. Ahora tenemos una guía sobre la experiencia de escritorio y una galería de diseño de Android renovada.
Ivy Knight • Tiempo de lectura: 2 min
-


Noticias sobre productos
Se ha lanzado la primera versión alfa de Room 3.0. Room 3.0 es una versión principal de la biblioteca que introduce cambios importantes y se centra en Kotlin Multiplatform (KMP). Además, añade compatibilidad con JavaScript y WebAssembly (WASM) a la compatibilidad con Android, iOS y JVM para ordenadores.
Daniel Santiago Rivera • Tiempo de lectura: 4 min
-


Noticias sobre productos
Hoy nos complace compartir cómo estamos incorporando la optimización automática dirigida por comentarios (AutoFDO) al kernel de Android para ofrecer a los usuarios mejoras significativas en el rendimiento.
Yabin Cui • Tiempo de lectura: 4 min
Mantente al día
Recibe cada semana en tu bandeja de entrada las últimas novedades sobre el desarrollo para Android.
