
Produktneuheiten
Wie die automatische Prompt-Optimierung die Qualität der GenAI Prompt API von ML Kit verbessert
Lesezeit: 3 Minuten
Automatische Prompt-Optimierung (Automated Prompt Optimization, APO)
Damit Sie Ihre Anwendungsfälle für die ML Kit Prompt API noch besser in der Produktion einsetzen können, stellen wir die automatische Prompt-Optimierung (Automated Prompt Optimization, APO) für On-Device-Modelle in Vertex AI vor. Mit der automatischen Prompt-Optimierung können Sie automatisch den optimalen Prompt für Ihre Anwendungsfälle finden.
Die Ära der On-Device-KI ist keine Zukunftsmusik mehr, sondern Realität. Mit der Veröffentlichung von Gemini Nano v3 stellen wir Nutzern beispiellose Funktionen für das Sprachverständnis und multimodale Funktionen direkt zur Verfügung. Die Modelle der Gemini Nano-Familie decken eine Vielzahl unterstützter Geräte im Android-Ökosystem ab. Für Entwickler, die die nächste Generation intelligenter Apps entwickeln, ist der Zugriff auf ein leistungsstarkes Modell jedoch nur der erste Schritt. Die eigentliche Herausforderung liegt in der Anpassung: Wie können Sie ein Foundation Model so anpassen, dass es für Ihren spezifischen Anwendungsfall eine Leistung auf Expertenniveau bietet, ohne die Einschränkungen der mobilen Hardware zu überschreiten?
In der serverseitigen Welt sind die größeren LLMs in der Regel sehr leistungsstark und erfordern weniger Anpassung an den jeweiligen Bereich. Auch wenn Anpassungen erforderlich sind, können erweiterte Optionen wie das LoRA-Feintuning (Low-Rank Adaptation) eine praktikable Lösung sein. Die einzigartige Architektur von Android AICore priorisiert jedoch ein gemeinsames, speichereffizientes Systemmodell. Das bedeutet, dass die Bereitstellung benutzerdefinierter LoRA-Adapter für jede einzelne App bei diesen gemeinsamen Systemdiensten mit Herausforderungen verbunden ist.
Es gibt jedoch eine alternative Methode, die ebenso effektiv sein kann. Durch die Nutzung der automatischen Prompt-Optimierung (Automated Prompt Optimization, APO) in Vertex AI können Entwickler eine Qualität erreichen, die dem Feintuning nahekommt, und gleichzeitig nahtlos in der nativen Android-Ausführungsumgebung arbeiten. Durch die Konzentration auf eine überlegene Systemanweisung ermöglicht APO Entwicklern, das Modellverhalten robuster und skalierbarer anzupassen als mit herkömmlichen Feintuning-Lösungen.
Hinweis: Gemini Nano V3 ist eine qualitätsoptimierte Version des hochgelobten Gemma 3N-Modells. Alle Prompt-Optimierungen, die am Open-Source-Modell Gemma 3N vorgenommen werden, gelten auch für Gemini Nano V3. Auf unterstützten Geräten nutzen die ML Kit GenAI APIs das Modell nano-v3, um die Qualität für Android-Entwickler zu maximieren.
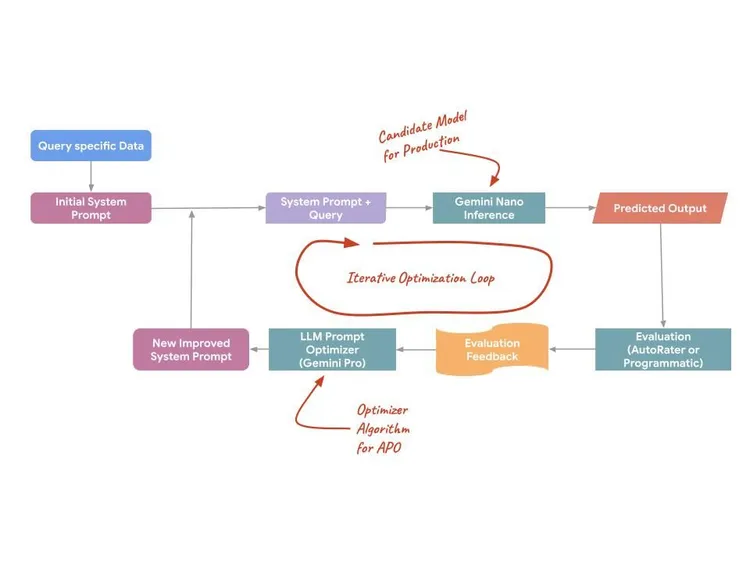
Bei der automatischen Prompt-Optimierung wird der Prompt nicht als statischer Text, sondern als programmierbare Oberfläche behandelt, die optimiert werden kann. Dabei werden serverseitige Modelle wie Gemini Pro und Flash verwendet, um Prompts vorzuschlagen, Variationen zu bewerten und den optimalen Prompt für Ihre spezifische Aufgabe zu finden. Dieser Prozess nutzt drei spezifische technische Mechanismen, um die Leistung zu maximieren:
- Automatische Fehleranalyse:Die automatische Prompt-Optimierung analysiert Fehlermuster aus Trainingsdaten, um automatisch spezifische Schwachstellen im ursprünglichen Prompt zu identifizieren.
- Semantische Anweisungsdestillation:Dabei werden umfangreiche Trainingsbeispiele analysiert, um die „wahre Absicht“ einer Aufgabe zu ermitteln. So werden Anweisungen erstellt, die die tatsächliche Datenverteilung genauer widerspiegeln.
- Paralleles Testen von Kandidaten:Anstatt jeweils nur eine Idee zu testen, werden mit der automatischen Prompt-Optimierung mehrere Prompt-Kandidaten parallel generiert und getestet, um das globale Maximum für die Qualität zu ermitteln.
Warum die automatische Prompt-Optimierung die Qualität des Feintunings erreichen kann
Es ist ein weit verbreiteter Irrtum, dass Feintuning immer eine bessere Qualität als Prompting liefert. Bei modernen Foundation Models wie Gemini Nano v3 kann Prompt Engineering allein schon sehr effektiv sein:
- Allgemeine Funktionen beibehalten:Beim Feintuning ( PEFT/LoRA) werden die Gewichte eines Modells so angepasst, dass sie eine bestimmte Datenverteilung überbetonen. Das führt oft zu „katastrophalem Vergessen“, bei dem das Modell zwar besser bei Ihrer spezifischen Syntax wird, aber schlechter bei allgemeiner Logik und Sicherheit. Bei der automatischen Prompt-Optimierung bleiben die Gewichte unverändert, sodass die Funktionen des Basismodells erhalten bleiben.
- Anweisungen befolgen und Strategien finden:Gemini Nano v3 wurde intensiv darauf trainiert, komplexe Systemanweisungen zu befolgen. Die automatische Prompt-Optimierung nutzt dies, indem sie die genaue Anweisungsstruktur findet, die die latenten Fähigkeiten des Modells freisetzt. Dabei werden oft Strategien entdeckt, die für menschliche Entwickler schwer zu finden wären.
Um diesen Ansatz zu validieren, haben wir die automatische Prompt-Optimierung für verschiedene Produktionsarbeitslasten bewertet. Unsere Validierung hat in verschiedenen Anwendungsfällen konsistente Genauigkeitssteigerungen von 5 bis 8% gezeigt.Bei mehreren bereitgestellten On-Device-Funktionen hat die automatische Prompt-Optimierung die Qualität deutlich verbessert.
| Anwendungsfall | Aufgabentyp | Aufgabenbeschreibung | Messwert | Verbesserung durch automatische Prompt-Optimierung |
| Themenklassifizierung | Textklassifizierung | Einen Nachrichtenartikel in Themen wie Finanzen oder Sport klassifizieren | Genauigkeit | +5% |
| Absichtsklassifizierung | Textklassifizierung | Eine Kundenserviceanfrage nach Absichten klassifizieren | Genauigkeit | +8,0% |
| Webseitenübersetzung | Textübersetzung | Eine Webseite vom Englischen in eine Landessprache übersetzen | BLEU | +8,57% |
Nahtloser End-to-End-Workflow für Entwickler
Es ist ein weit verbreiteter Irrtum, dass Feintuning immer eine bessere Qualität als Prompting liefert. Bei modernen Foundation Models wie Gemini Nano v3 kann Prompt Engineering allein schon sehr effektiv sein:
- Allgemeine Funktionen beibehalten:Beim Feintuning ( PEFT/LoRA) werden die Gewichte eines Modells so angepasst, dass sie eine bestimmte Datenverteilung überbetonen. Das führt oft zu „katastrophalem Vergessen“, bei dem das Modell zwar besser bei Ihrer spezifischen Syntax wird, aber schlechter bei allgemeiner Logik und Sicherheit. Bei der automatischen Prompt-Optimierung bleiben die Gewichte unverändert, sodass die Funktionen des Basismodells erhalten bleiben.
- Anweisungen befolgen und Strategien finden:Gemini Nano v3 wurde intensiv darauf trainiert, komplexe Systemanweisungen zu befolgen. Die automatische Prompt-Optimierung nutzt dies, indem sie die genaue Anweisungsstruktur findet, die die latenten Fähigkeiten des Modells freisetzt. Dabei werden oft Strategien entdeckt, die für menschliche Entwickler schwer zu finden wären.
Um diesen Ansatz zu validieren, haben wir die automatische Prompt-Optimierung für verschiedene Produktionsarbeitslasten bewertet. Unsere Validierung hat in verschiedenen Anwendungsfällen konsistente Genauigkeitssteigerungen von 5 bis 8% gezeigt.Bei mehreren bereitgestellten On-Device-Funktionen hat die automatische Prompt-Optimierung die Qualität deutlich verbessert.
Fazit
Die Veröffentlichung der automatischen Prompt-Optimierung (Automated Prompt Optimization, APO) markiert einen Wendepunkt für generative KI auf Geräten. Indem wir die Lücke zwischen Foundation Models und Leistung auf Expertenniveau schließen, geben wir Entwicklern die Tools an die Hand, um robustere mobile Anwendungen zu entwickeln. Ob Sie gerade erst mit der Zero-Shot-Optimierung beginnen oder mit der datengestützten Optimierung auf die Produktion skalieren – der Weg zu hochwertiger On-Device-Intelligenz ist jetzt klarer. Starten Sie noch heute Ihre On-Device-Anwendungsfälle mit der Prompt API von ML Kit und der automatischen Prompt-Optimierung von Vertex AI.
Relevante Links:
Verfasst von:



Weiterlesen
-



Produktneuheiten
Wir bei Google möchten die leistungsstärksten KI-Modelle direkt auf Android-Geräten verfügbar machen. Heute freuen wir uns, die Veröffentlichung unseres neuesten hochmodernen Open-Source-Modells anzukündigen: Gemma 4.
Caren Chang, David Chou • Lesezeit: 3 Minuten
-

Produktneuheiten
Mit KI können Sie einfacher personalisierte App-Erlebnisse erstellen, bei denen Inhalte in das richtige Format für Nutzer umgewandelt werden. Wir haben Entwicklern bereits die Möglichkeit gegeben, Gemini Nano über ML Kit GenAI APIs zu integrieren, die auf bestimmte Anwendungsfälle wie Zusammenfassungen und Bildbeschreibungen zugeschnitten sind.
Caren Chang, Chengji Yan, Penny Li • Lesezeit: 2 Minuten
-



Produktneuheiten
Das Android XR-Ökosystem wächst rasant – von Augmented-Reality-Overlays bis hin zu vollständig immersiven Umgebungen. Das Samsung Galaxy XR ist bereits verfügbar.
Stevan Silva, Vinny DaSilva • Lesezeit: 3 Minuten
Auf dem Laufenden bleiben
Lassen Sie sich Woche für Woche die neuesten Informationen zur Android-Entwicklung zusenden.
