
Novedades de productos
Cómo la optimización automática de las peticiones desbloquea mejoras de calidad en la API GenAI Prompt de ML Kit
Lectura de 3 minutos
Optimización automática de peticiones (APO)
Para ayudarte a llevar a producción tus casos prácticos de la API Prompt de ML Kit, nos complace anunciar la optimización automática de peticiones (APO) para modelos On-Device en Vertex AI. Optimización automática de peticiones es una herramienta que te ayuda a encontrar automáticamente la petición óptima para tus casos prácticos.
La era de la IA en el dispositivo ya no es una promesa, sino una realidad. Con el lanzamiento de Gemini Nano v3, ponemos en manos de los usuarios capacidades multimodales y de comprensión del lenguaje sin precedentes. Gracias a la familia de modelos Gemini Nano, tenemos una amplia cobertura de dispositivos compatibles en todo el ecosistema Android. Sin embargo, para los desarrolladores que están creando la próxima generación de aplicaciones inteligentes, acceder a un modelo potente es solo el primer paso. El verdadero reto reside en la personalización: ¿cómo se adapta un modelo fundacional para que alcance un rendimiento de nivel experto en un caso de uso específico sin incumplir las limitaciones del hardware móvil?
En el mundo del lado del servidor, los LLMs más grandes suelen ser muy eficaces y requieren menos adaptación al dominio. Incluso cuando sea necesario, se pueden usar opciones más avanzadas, como el ajuste fino de LoRA (adaptación de bajo rango). Sin embargo, la arquitectura única de Android AICore prioriza un modelo de sistema compartido y eficiente en cuanto a memoria. Esto significa que implementar adaptadores LoRA personalizados para cada aplicación individual conlleva problemas en estos servicios del sistema compartidos.
Sin embargo, hay otra vía que puede tener el mismo impacto. Al aprovechar la optimización automática de peticiones (APO) en Vertex AI, los desarrolladores pueden conseguir una calidad similar a la del ajuste fino, todo ello mientras trabajan sin problemas en el entorno de ejecución nativo de Android. Al centrarse en instrucciones de sistema superiores, APO permite a los desarrolladores adaptar el comportamiento del modelo con mayor solidez y escalabilidad que las soluciones de ajuste fino tradicionales.
Nota: Gemini Nano V3 es una versión optimizada en cuanto a calidad del aclamado modelo Gemma 3N. Las optimizaciones de las peticiones que se hagan en el modelo de código abierto Gemma 3N también se aplicarán a Gemini Nano V3. En los dispositivos compatibles, las APIs de IA generativa de ML Kit aprovechan el modelo nano-v3 para maximizar la calidad para los desarrolladores de Android.
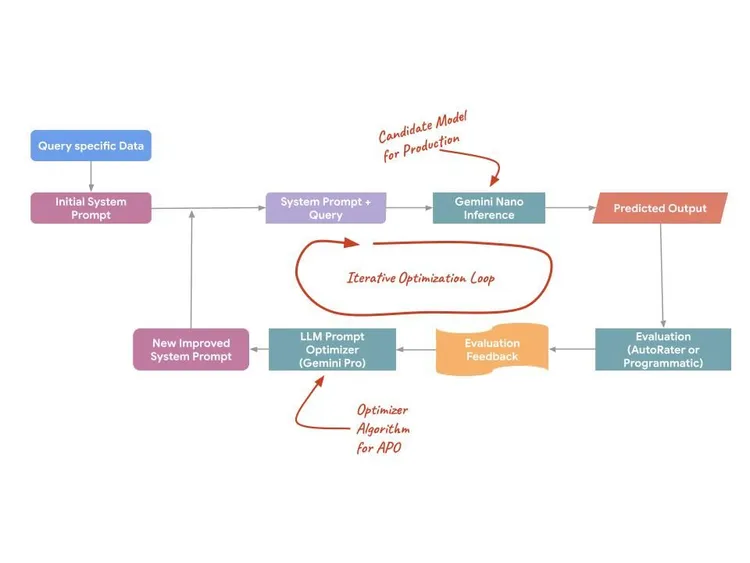
APO trata la petición no como un texto estático, sino como una superficie programable que se puede optimizar. Aprovecha los modelos del lado del servidor (como Gemini Pro y Flash) para proponer peticiones, evaluar variaciones y encontrar la óptima para tu tarea específica. Este proceso emplea tres mecanismos técnicos específicos para maximizar el rendimiento:
- Análisis de errores automatizado: APO analiza los patrones de errores de los datos de entrenamiento para identificar automáticamente los puntos débiles específicos de la petición inicial.
- Destilación de instrucciones semánticas: analiza ejemplos de entrenamiento masivos para destilar la "verdadera intención" de una tarea, creando instrucciones que reflejan con mayor precisión la distribución de datos real.
- Pruebas paralelas de candidatos: en lugar de probar una idea a la vez, APO genera y prueba numerosos candidatos de peticiones en paralelo para identificar el máximo global de calidad.
Por qué APO puede abordar la calidad de ajuste preciso
Es un error común pensar que el ajuste fino siempre da mejores resultados que las peticiones. En el caso de los modelos fundacionales modernos, como Gemini Nano v3, la ingeniería de peticiones puede ser eficaz por sí sola:
- Conservar las funciones generales: el ajuste fino ( PEFT o LoRA) obliga a los pesos de un modelo a centrarse en una distribución de datos específica. Esto suele provocar un "olvido catastrófico", que se produce cuando el modelo mejora en tu sintaxis específica, pero empeora en la lógica general y la seguridad. APO no modifica las ponderaciones, por lo que se conservan las funciones del modelo base.
- Seguimiento de instrucciones y descubrimiento de estrategias: Gemini Nano v3 se ha entrenado rigurosamente para seguir instrucciones complejas del sistema. APO aprovecha esta situación buscando la estructura de instrucciones exacta que desbloquea las funciones latentes del modelo. De esta forma, a menudo descubre estrategias que a los ingenieros humanos les resultaría difícil encontrar.
Para validar este enfoque, evaluamos APO en diversas cargas de trabajo de producción. Nuestra validación ha mostrado mejoras de precisión constantes del 5 al 8% en varios casos prácticos.En varias funciones implementadas en el dispositivo, APO ha proporcionado mejoras significativas en la calidad.
| Caso práctico | Tipo de tarea | Descripción de la tarea | Métrica | Mejora de APO |
| Clasificación por tema | Clasificación de textos | Clasifica un artículo de noticias en temas como finanzas, deportes, etc. | Precisión | +5% |
| Clasificación de la intención | Clasificación de textos | Clasificar una consulta de atención al cliente en intenciones | Precisión | +8,0% |
| Traducción de páginas web | Traducción de texto | Traducir una página web del inglés a un idioma local | BLEU | +8,57% |
Un flujo de trabajo de desarrollo integral y fluido
Es un error común pensar que el ajuste fino siempre da mejores resultados que las peticiones. En el caso de los modelos fundacionales modernos, como Gemini Nano v3, la ingeniería de peticiones puede ser eficaz por sí sola:
- Conservar las funciones generales: el ajuste fino ( PEFT o LoRA) obliga a los pesos de un modelo a centrarse en una distribución de datos específica. Esto suele provocar un "olvido catastrófico", que se produce cuando el modelo mejora en tu sintaxis específica, pero empeora en la lógica general y la seguridad. APO no modifica las ponderaciones, por lo que se conservan las funciones del modelo base.
- Seguimiento de instrucciones y descubrimiento de estrategias: Gemini Nano v3 se ha entrenado rigurosamente para seguir instrucciones complejas del sistema. APO aprovecha esta situación buscando la estructura de instrucciones exacta que desbloquea las funciones latentes del modelo. De esta forma, a menudo descubre estrategias que a los ingenieros humanos les resultaría difícil encontrar.
Para validar este enfoque, evaluamos APO en diversas cargas de trabajo de producción. Nuestra validación ha mostrado mejoras de precisión constantes del 5 al 8% en varios casos prácticos.En varias funciones implementadas en el dispositivo, APO ha proporcionado mejoras significativas en la calidad.
Conclusión
El lanzamiento de Optimización automática de peticiones (APO) marca un punto de inflexión para la IA generativa en el dispositivo. Al acortar la distancia entre los modelos fundacionales y el rendimiento de nivel experto, ofrecemos a los desarrolladores las herramientas necesarias para crear aplicaciones móviles más sólidas. Tanto si acabas de empezar a usar la optimización sin ejemplos como si quieres ampliar la producción con el ajuste basado en datos, ahora es más fácil conseguir una inteligencia de alta calidad en el dispositivo. Lanza hoy mismo tus casos prácticos en el dispositivo a producción con la API Prompt de ML Kit y la optimización automática de peticiones de Vertex AI.
Enlaces relevantes:
Escrito por:




Seguir leyendo
-

Noticias sobre productos
La IA facilita la creación de experiencias de aplicación personalizadas que transforman el contenido al formato adecuado para los usuarios. Anteriormente, permitimos que los desarrolladores se integraran con Gemini Nano a través de las APIs GenAI de ML Kit, diseñadas para casos prácticos específicos, como la creación de resúmenes y la descripción de imágenes.
Caren Chang, Chengji Yan, Penny Li • Tiempo de lectura: 2 min
-


Noticias sobre productos
Nos complace anunciar importantes actualizaciones de nuestros recursos de diseño, que te ofrecen la guía completa que necesitas para crear aplicaciones Android adaptables y de alta calidad en todos los factores de forma. Ahora tenemos una guía sobre la experiencia de escritorio y una galería de diseño de Android renovada.
Ivy Knight • Tiempo de lectura: 2 min
-


Noticias sobre productos
Se ha lanzado la primera versión alfa de Room 3.0. Room 3.0 es una versión principal de la biblioteca que introduce cambios importantes y se centra en Kotlin Multiplatform (KMP). Además, añade compatibilidad con JavaScript y WebAssembly (WASM) a la compatibilidad con Android, iOS y JVM para ordenadores.
Daniel Santiago Rivera • Tiempo de lectura: 4 min
Mantente al día
Recibe cada semana en tu bandeja de entrada las últimas novedades sobre el desarrollo para Android.
