
Actualités des produits
Comment l'optimisation automatique des requêtes permet d'améliorer la qualité de l'API GenAI Prompt de ML Kit
Temps de lecture : 3 min
Optimisation automatisée des requêtes (OAR)
Pour vous aider à déployer vos cas d'utilisation de l'API ML Kit Prompt en production, nous sommes heureux d'annoncer l'optimisation automatique des requêtes (APO, Automated Prompt Optimization) ciblant les modèles sur l'appareil dans Vertex AI. L'optimisation automatique des prompts est un outil qui vous aide à trouver automatiquement le prompt optimal pour vos cas d'utilisation.
L'ère de l'IA sur l'appareil n'est plus une promesse, mais une réalité de production. Avec la sortie de Gemini Nano v3, nous mettons des capacités de compréhension du langage et des fonctionnalités multimodales sans précédent directement entre les mains des utilisateurs. Grâce à la famille de modèles Gemini Nano, nous couvrons un large éventail d'appareils compatibles dans l'écosystème Android. Mais pour les développeurs qui créent la prochaine génération d'applications intelligentes, l'accès à un modèle puissant n'est que la première étape. Le véritable défi réside dans la personnalisation : comment adapter un modèle de fondation pour obtenir des performances de niveau expert pour votre cas d'utilisation spécifique sans enfreindre les contraintes du matériel mobile ?
Dans le monde côté serveur, les LLM les plus grands ont tendance à être très performants et nécessitent moins d'adaptation au domaine. Même lorsque cela est nécessaire, des options plus avancées telles que le réglage fin LoRA (adaptation à faible rang) peuvent être envisageables. Toutefois, l'architecture unique d'Android AICore privilégie un modèle système partagé et économe en mémoire. Cela signifie que le déploiement d'adaptateurs LoRA personnalisés pour chaque application individuelle pose des problèmes sur ces services système partagés.
Mais il existe une autre voie qui peut avoir un impact tout aussi important. En tirant parti de l'optimisation automatique des prompts (APO) sur Vertex AI, les développeurs peuvent obtenir une qualité proche du fine-tuning, tout en travaillant de manière fluide dans l'environnement d'exécution Android natif. En se concentrant sur des instructions système de qualité supérieure, l'APO permet aux développeurs d'adapter le comportement des modèles avec une robustesse et une évolutivité supérieures à celles des solutions de réglage fin traditionnelles.
Remarque : Gemini Nano V3 est une version optimisée en termes de qualité du modèle Gemma 3N, qui a été très bien accueilli. Toutes les optimisations d'invites effectuées sur le modèle Gemma 3N Open Source s'appliqueront également à Gemini Nano V3. Sur les appareils compatibles, les API ML Kit GenAI exploitent le modèle nano-v3 pour maximiser la qualité pour les développeurs Android.
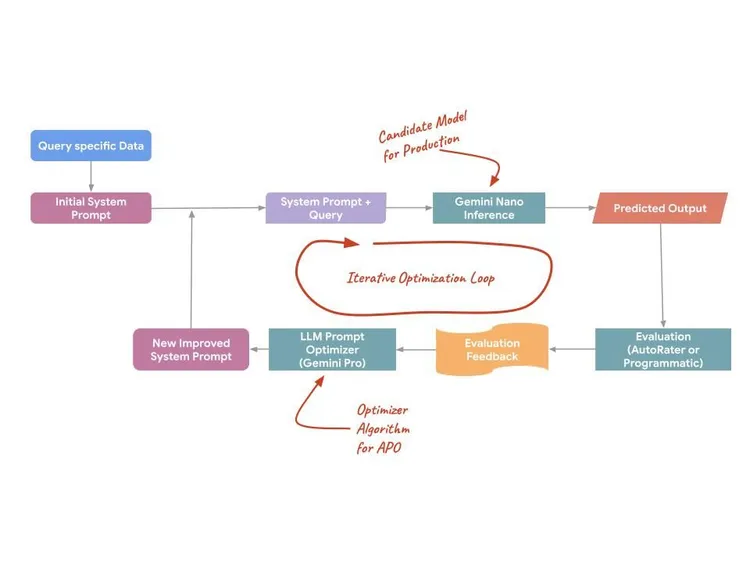
L'APO traite la requête non pas comme un texte statique, mais comme une surface programmable qui peut être optimisée. Il s'appuie sur des modèles côté serveur (comme Gemini Pro et Flash) pour proposer des requêtes, évaluer des variantes et trouver celle qui est optimale pour votre tâche spécifique. Ce processus utilise trois mécanismes techniques spécifiques pour maximiser les performances :
- Analyse automatisée des erreurs : APO analyse les schémas d'erreur à partir des données d'entraînement pour identifier automatiquement les faiblesses spécifiques de la requête initiale.
- Distillation d'instructions sémantiques : elle analyse de nombreux exemples d'entraînement pour extraire la "véritable intention" d'une tâche, en créant des instructions qui reflètent plus précisément la distribution réelle des données.
- Test parallèle des candidats : au lieu de tester une idée à la fois, APO génère et teste de nombreux candidats de requête en parallèle pour identifier le maximum global de qualité.
Pourquoi APO peut approcher la qualité du réglage précis
On croit souvent à tort que le fine-tuning permet toujours d'obtenir une meilleure qualité que le prompting. Pour les modèles de fondation modernes comme Gemini Nano v3, le prompt engineering peut avoir un impact en soi :
- Préservation des capacités générales : le fine-tuning ( PEFT/LoRA) force les pondérations d'un modèle à surindexer une distribution de données spécifique. Cela conduit souvent à un "oubli catastrophique", où le modèle s'améliore dans votre syntaxe spécifique, mais se détériore en termes de logique générale et de sécurité. L'APO ne modifie pas les pondérations, ce qui préserve les capacités du modèle de base.
- Suivi des instructions et découverte de stratégies : Gemini Nano v3 a été rigoureusement entraîné pour suivre des instructions système complexes. L'APO exploite cela en trouvant la structure d'instruction exacte qui libère les capacités latentes du modèle, en découvrant souvent des stratégies que les ingénieurs humains pourraient avoir du mal à trouver.
Pour valider cette approche, nous avons évalué APO sur diverses charges de travail de production. Notre validation a montré des gains de précision constants de 5 à 8% dans différents cas d'utilisation.APO a permis d'améliorer considérablement la qualité de plusieurs fonctionnalités déployées sur l'appareil.
| Use Case | Type de tâche | Description de la tâche | Métrique | Amélioration de l'APO |
| Classification des thèmes | Classification de texte | Classer un article d'actualité dans des thèmes tels que la finance, le sport, etc. | Précision | +5% |
| Classification des intentions | Classification de texte | Classer une demande de service client dans des intentions | Précision | +8,0% |
| Traduction de pages Web | Traduction de texte | Traduire une page Web de l'anglais vers une langue locale | BLEU | +8,57% |
Un workflow de développement de bout en bout fluide
On croit souvent à tort que le fine-tuning permet toujours d'obtenir une meilleure qualité que le prompting. Pour les modèles de fondation modernes comme Gemini Nano v3, le prompt engineering peut avoir un impact en soi :
- Préservation des capacités générales : le fine-tuning ( PEFT/LoRA) force les pondérations d'un modèle à surindexer une distribution de données spécifique. Cela conduit souvent à un "oubli catastrophique", où le modèle s'améliore dans votre syntaxe spécifique, mais se détériore en termes de logique générale et de sécurité. L'APO ne modifie pas les pondérations, ce qui préserve les capacités du modèle de base.
- Suivi des instructions et découverte de stratégies : Gemini Nano v3 a été rigoureusement entraîné pour suivre des instructions système complexes. L'APO exploite cela en trouvant la structure d'instruction exacte qui libère les capacités latentes du modèle, en découvrant souvent des stratégies que les ingénieurs humains pourraient avoir du mal à trouver.
Pour valider cette approche, nous avons évalué APO sur diverses charges de travail de production. Notre validation a montré des gains de précision constants de 5 à 8% dans différents cas d'utilisation.APO a permis d'améliorer considérablement la qualité de plusieurs fonctionnalités déployées sur l'appareil.
Conclusion
La sortie de l'optimisation automatique des requêtes (APO, Automated Prompt Optimization) marque un tournant pour l'IA générative sur l'appareil. En comblant le fossé entre les modèles de fondation et les performances de niveau expert, nous donnons aux développeurs les outils nécessaires pour créer des applications mobiles plus robustes. Que vous débutiez avec l'optimisation zero-shot ou que vous passiez à l'échelle en production avec le raffinement axé sur les données, le chemin vers une intelligence sur l'appareil de haute qualité est désormais plus clair. Lancez dès aujourd'hui vos cas d'utilisation sur l'appareil en production grâce à l'API Prompt de ML Kit et à l'optimisation automatisée des requêtes de Vertex AI.
Liens associés :
Écrit par :



Lire la suite
-



Actualités des produits
Chez Google, nous nous engageons à intégrer les modèles d'IA les plus performants directement dans les appareils Android que vous avez dans votre poche. Aujourd'hui, nous sommes ravis d'annoncer la sortie de notre dernier modèle ouvert de pointe : Gemma 4.
Caren Chang, David Chou • Temps de lecture : 3 min
-

Actualités des produits
L'IA permet de créer plus facilement des expériences d'application personnalisées qui transforment le contenu au format adapté aux utilisateurs. Nous avons précédemment permis aux développeurs d'intégrer Gemini Nano via les API ML Kit GenAI adaptées à des cas d'utilisation spécifiques, comme la synthèse et la description d'images.
Caren Chang, Chengji Yan, Penny Li • Temps de lecture : 2 min
-


Actualités des produits
Annoncé aujourd'hui lors de The Android Show, Android passe d'un système d'exploitation à un système intelligent, ce qui crée davantage d'opportunités d'engagement avec vos applications.
Matthew McCullough • Temps de lecture : 4 min
Restez informé
Recevez chaque semaine les dernières informations sur le développement Android directement dans votre boîte de réception.
