

在 Android 17 中,以 SDK 37 或更高版本为目标平台的应用将收到 MessageQueue 的新实现,该实现是无锁的。新实现可提升性能并减少丢帧,但可能会导致反映 MessageQueue 私有字段和方法的客户端出现问题。如需详细了解此行为变更以及如何减轻影响,请参阅 MessageQueue 行为变更文档。这篇技术博文概述了 MessageQueue 的重新架构,并介绍了如何使用 Perfetto 分析锁争用问题。
Looper 会驱动每个 Android 应用的界面线程。它从 MessageQueue 中拉取工作,将其分派给 Handler,然后重复此过程。二十年来,MessageQueue 一直使用单个监控器锁定(即 synchronized 代码块)来保护其状态。
Android 17 对此组件进行了重大更新:引入了名为 DeliQueue 的无锁实现。
本文介绍了锁如何影响界面性能、如何使用 Perfetto 分析这些问题,以及用于改进 Android 主线程的具体算法和优化。
问题:锁争用和优先级反转
旧版 MessageQueue 充当受单个锁保护的优先级队列。如果后台线程在主线程执行队列维护时发布消息,则后台线程会阻塞主线程。
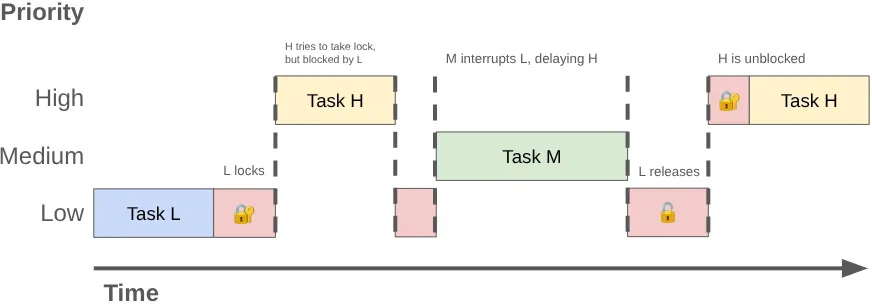
当两个或多个线程争夺同一锁的独占使用权时,这种情况称为锁争用。这种争用可能会导致优先级反转,从而导致界面卡顿和其他性能问题。
当高优先级线程(如界面线程)被迫等待低优先级线程时,可能会发生优先级倒置。考虑以下序列:
- 一个低优先级的后台线程获取
MessageQueue锁,以发布其所做工作的成果。 - 一个中等优先级的线程变为可运行状态,内核的调度程序为其分配 CPU 时间,抢占低优先级线程。
- 高优先级界面线程完成当前任务并尝试从队列中读取数据,但由于低优先级线程持有锁,因此被阻塞。
低优先级线程会阻塞界面线程,而中优先级工作会进一步延迟界面线程。
使用 Perfetto 分析资源争用
您可以使用 Perfetto 诊断这些问题。在标准轨迹中,线程在监视器锁上被阻塞时会进入休眠状态,Perfetto 会显示一个切片来指示锁的所有者。
查询轨迹数据时,请查找名为“monitor contention with …”的切片,后跟拥有锁的线程的名称和获取锁的代码位置。
案例研究:启动器卡顿
为了便于说明,我们来分析一个轨迹,其中用户在 Pixel 手机上使用相机应用拍照后立即在主屏幕上导航时遇到了卡顿。下面我们看到的是 Perfetto 的屏幕截图,其中显示了导致丢帧的事件:
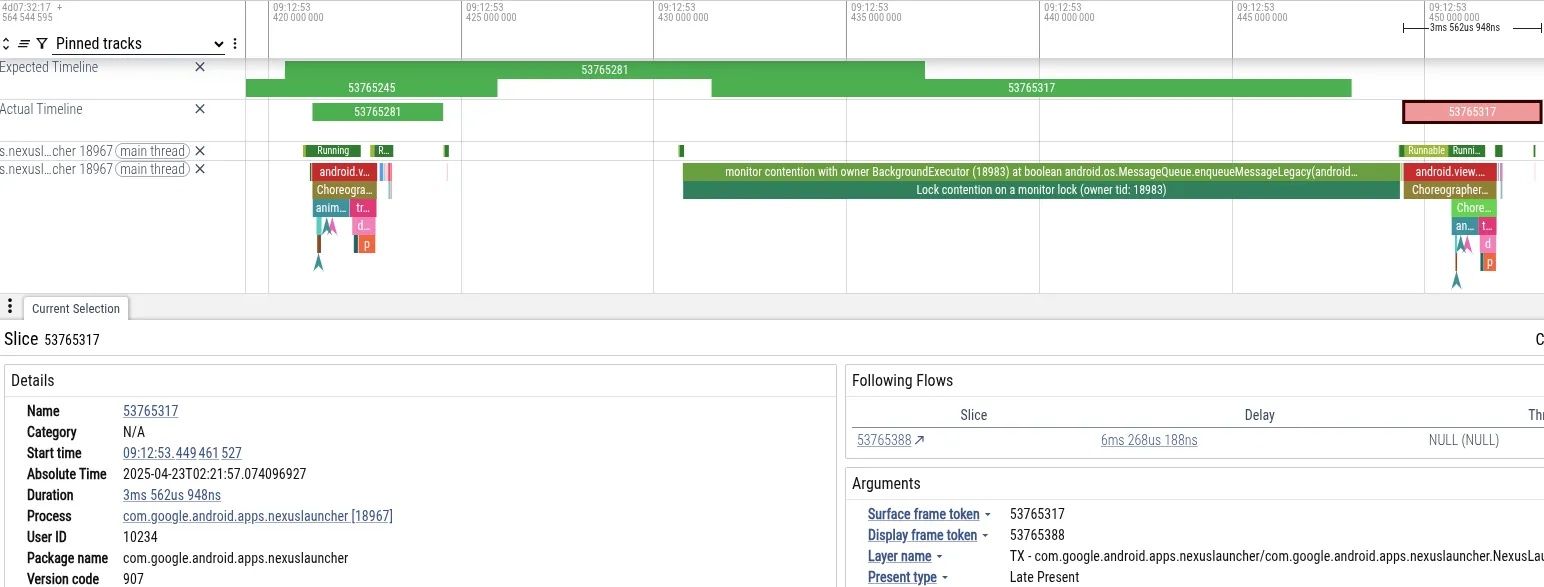
- 症状:启动器主线程错过了其帧截止时间。它阻塞了 18 毫秒,超过了 60Hz 渲染所需的 16 毫秒截止期限。
- 诊断:Perfetto 显示主线程被
MessageQueue锁阻塞。“BackgroundExecutor”线程拥有该锁。 - 根本原因:BackgroundExecutor 以 Process.THREAD_PRIORITY_BACKGROUND(极低优先级)运行。它执行了一项非紧急任务(检查应用使用时限)。与此同时,中优先级的线程正在使用 CPU 时间来处理来自摄像头的数据。操作系统调度程序抢占了 BackgroundExecutor 线程来运行相机线程。
此序列导致启动器的界面线程(高优先级)被相机工作器线程(中优先级)间接阻塞,而相机工作器线程又阻止启动器的后台线程(低优先级)释放锁。
使用 PerfettoSQL 查询轨迹
您可以使用 PerfettoSQL 查询轨迹数据中的特定模式。如果您有大量来自用户设备或测试的轨迹,并且正在搜索显示问题的特定轨迹,那么此功能非常有用。
例如,以下查询可查找与丢帧(卡顿)同时发生的 MessageQueue 争用:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
在这个更复杂的示例中,我们将联接跨多个表的轨迹数据,以识别应用启动期间的 MessageQueue 争用:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
您可以使用自己喜欢的 LLM 编写 PerfettoSQL 查询,以查找其他模式。
在 Google,我们使用 BigTrace 在数百万个轨迹中运行 PerfettoSQL 查询。通过这样做,我们确认了我们之前看到的零星问题实际上是系统性问题。数据表明,MessageQueue锁定争用会影响整个生态系统中的用户,证实了需要进行根本性的架构更改。
解决方案:无锁并发
我们通过实现无锁数据结构解决了 MessageQueue 争用问题,该结构使用原子内存操作而非排他锁来同步对共享状态的访问。如果至少有一个线程始终可以取得进展,而不管其他线程的调度行为如何,则数据结构或算法是无锁的。此属性通常很难实现,并且对于大多数代码来说,通常不值得追求。
原子基元
无锁软件通常依赖于硬件提供的原子读取-修改-写入原语。
在旧版 ARM64 CPU 上,原子操作使用 Load-Link/Store-Conditional (LL/SC) 循环。CPU 加载一个值并标记相应地址。如果另一个线程写入该地址,则存储失败,并且循环会重试。由于线程可以不断尝试并成功,而无需等待另一个线程,因此此操作是无锁的。
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr较新的 ARM 架构 (ARMv8.1) 支持大型系统扩展 (LSE),其中包括比较并交换 (CAS) 或加载并添加(如下所示)形式的指令。在 Android 17 中,我们为 Android 运行时 (ART) 编译器添加了支持,以检测何时支持 LSE 并发出优化后的指令:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.在我们的基准比较中,使用 CAS 的高争用代码比 LL/SC 变体快约 3 倍。
Java 编程语言通过 java.util.concurrent.atomic 提供依赖于这些和其他专用 CPU 指令的原子原语。
数据结构:DeliQueue
为了消除 MessageQueue 中的锁争用,我们的工程师设计了一种名为 DeliQueue 的新型数据结构。DeliQueue 将 Message 插入与 Message 处理分开:
Messages(Treiber 堆栈)的列表:无锁堆栈。任何线程都可以在此处推送新的Messages,而不会发生争用。- 优先级队列(最小堆):一个待处理的
Messages堆,由 Looper 线程独占(因此无需同步或锁定即可访问)。
入队:推送到 Treiber 堆栈
Messages 的列表保存在 Treiber 堆栈 [1] 中,这是一个使用 CAS 循环更新头指针的无锁堆栈。
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}基于《Java 并发编程实战》[2] 的源代码可在线获取,并已发布到公共领域
任何生产者都可以随时将新的 Message 推送到堆栈。这就像在熟食柜台取号一样 - 您的号码取决于您到达的时间,但您拿到食物的顺序不一定与号码一致。由于这是一个关联堆栈,因此每个 Message 都是一个子堆栈 - 您可以通过跟踪头部并向前迭代来查看任何时间点的 Message 队列,即使在遍历期间添加了新的 Message,您也不会看到任何新的 Message 被推送到顶部。
出队:批量转移到最小堆
为了找到要处理的下一个 Message,Looper 会从 Treiber 堆栈中处理新的 Message,方法是从顶部开始遍历堆栈,并进行迭代,直到找到之前处理的最后一个 Message。当 Looper 向下遍历堆栈时,它会将 Message 插入到按截止时间排序的最小堆中。由于 Looper 独占堆,因此它无需使用锁或原子操作即可对 Message 进行排序和处理。

在遍历堆栈时,Looper还会创建从堆叠的 Message到其前身的链接,从而形成一个双向链表。创建关联列表是安全的,因为指向堆栈下方的链接是通过使用 CAS 的 Treiber 堆栈算法添加的,而指向堆栈上方的链接仅由 Looper 线程读取和修改。然后,这些反向链接用于在 O(1) 时间内从堆栈中的任意点移除 Message。
此设计为生产者(将工作发布到队列的线程)提供 O(1) 插入,并为消费者(Looper)提供摊销的 O(log N) 处理。
使用最小堆来对 Message 进行排序还解决了旧版 MessageQueue 中的一个基本缺陷,即 Message 保存在以顶部为根的单向链表中。在旧版实现中,从头部移除的复杂度为 O(1),但插入的复杂度最差为 O(N),对于过载的队列,这种扩展性很差!相反,插入和移除最小堆的时间复杂度为对数级,可提供极具竞争力的平均性能,但在尾部延迟方面表现出色。
旧版(已锁定)MessageQueue | DeliQueue | |
| 插入 | O(N) | O(1)(对于调用线程) 对于 |
| 从头部移除 | O(1) | O(logN) |
在旧版队列实现中,生产者和消费者使用锁来协调对底层单向链表的独占访问。在 DeliQueue 中,Treiber 堆栈处理并发访问,单个消费者处理其工作队列的排序。
移除:通过标记删除的一致性
DeliQueue 是一种混合数据结构,它将无锁 Treiber 堆栈与单线程最小堆相结合。在没有全局锁的情况下保持这两个结构同步是一项独特的挑战:消息可能实际存在于堆栈中,但已从队列中逻辑移除。
为了解决这个问题,DeliQueue 使用了一种称为“墓碑化”的技术。每个 Message 都会通过后向和前向指针、在堆数组中的索引以及一个布尔值标志来跟踪其在堆栈中的位置,该标志用于指示该 Message 是否已被移除。当 Message 准备好运行时,Looper 线程将 CAS 其移除标志,然后将其从堆栈中移除。
当另一个线程需要移除 Message 时,它不会立即从数据结构中提取该 Message。而是会执行以下步骤:
- 逻辑移除:线程使用 CAS 将
Message的移除标志从 false 原子性地设置为 true。Message会保留在数据结构中,作为其待移除的证据,即所谓的“墓碑”。一旦某个Message被标记为待移除,DeliQueue 就会在每次找到它时将其视为不再存在于队列中。 - 延迟清理:从数据结构中实际移除由
Looper线程负责,并延迟到稍后进行。移除器线程不会修改堆栈或堆,而是将Message添加到另一个无锁空闲列表堆栈。 - 结构性移除:只有
Looper可以与堆互动或从堆栈中移除元素。当它唤醒时,会清除空闲列表并处理其中包含的Message。然后,每个Message都会从堆栈中解除关联并从堆中移除。
此方法可确保堆的所有管理操作都以单线程方式进行。它可最大限度地减少所需的并发操作和内存屏障数量,从而使关键路径更快、更简单。
遍历:良性 Java 内存模型数据竞争
大多数并发 API(例如 Java 标准库中的 Future 或 Kotlin 的 Job 和 Deferred)都包含一种在工作完成之前取消工作的机制。这些类中的一个类的实例与一个底层工作单元一一对应,并且对对象调用 cancel 会取消与其关联的特定操作。
如今的 Android 设备具有多核 CPU 和并发的代际垃圾收集功能。但在 Android 刚开发出来时,为每个工作单元分配一个对象过于昂贵。因此,Android 的 Handler 支持通过 removeMessages 的多种重载来取消 - 而不是移除特定的 Message,它会移除符合指定条件的所有 Message。在实践中,这需要遍历在调用 removeMessages 之前插入的所有 Message,并移除匹配的 Message。
向前迭代时,线程只需要一个有序的原子操作来读取堆栈的当前头部。之后,系统会使用普通字段读取来查找下一个 Message。如果 Looper 线程在移除 Message 时修改 next 字段,则 Looper 的写入和另一线程的读取会不同步,这属于数据竞争。通常,数据竞态是一种严重的 bug,可能会导致应用出现严重问题,例如内存泄漏、无限循环、崩溃、冻结等。不过,在某些狭窄的条件下,数据竞争在 Java 内存模型中可能是良性的。假设我们从以下堆栈开始:

我们对头执行原子读取,并看到 A。A 的下一个指针指向 B。在处理 B 的同时,循环器可能会移除 B 和 C,方法是将 A 更新为指向 C,然后再指向 D。
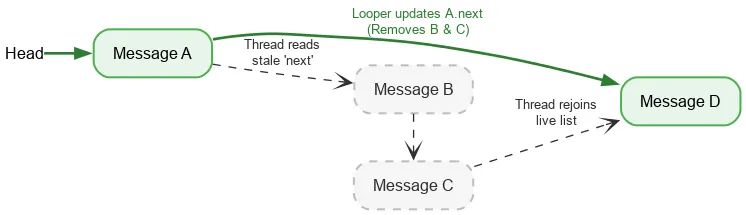
即使 B 和 C 在逻辑上被移除,B 仍保留指向 C 的下一个指针,而 C 保留指向 D 的下一个指针。读取线程继续遍历已分离的已移除节点,最终在 D 处重新加入实时堆栈。
通过设计 DeliQueue 来处理遍历和移除之间的竞争,我们实现了安全的无锁迭代。
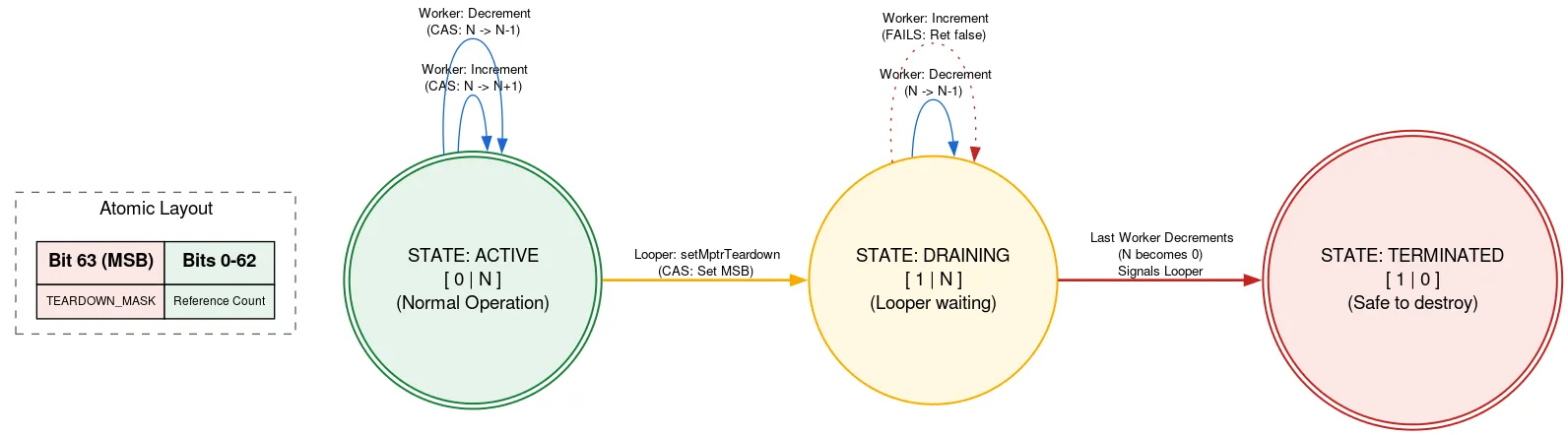
退出:原生引用计数
Looper 由原生分配提供支持,一旦 Looper 退出,必须手动释放。如果某个其他线程在 Looper 退出时添加 Message,则该线程可能会在 Message 释放后使用其原生分配,从而导致内存安全违规。我们使用标记的引用计数来防止这种情况,其中原子的一个位用于指示 Looper 是否正在退出。
在使用原生分配之前,线程会读取 refcount 原子。如果设置了退出位,则返回 Looper 正在退出,并且不得使用原生分配。如果不是,则尝试使用原生分配通过 CAS 递增活跃线程数。在完成所需操作后,它会递减计数。如果退出位是在递增之后但在递减之前设置的,并且计数现在为零,则唤醒 Looper 线程。
当 Looper 线程准备退出时,它会使用 CAS 在原子中设置退出位。如果引用计数为 0,则可以继续释放其原生分配。否则,它会自行停放,因为知道当原生分配的最后一个用户递减引用计数时,它会被唤醒。这种方法确实意味着 Looper 线程会等待其他线程的进度,但仅在退出时才会等待。这种情况只会发生一次,对性能要求不高,并且可以使使用原生分配的其他代码完全无锁。
实现中还有许多其他技巧和复杂性。您可以查看源代码,详细了解 DeliQueue。
优化:无分支编程
在开发和测试 DeliQueue 的过程中,该团队运行了许多基准测试,并仔细分析了新代码。使用 simpleperf 工具发现的一个问题是,由 Message 比较器代码导致的流水线刷新。
标准比较器使用条件跳转,用于决定哪个 Message 先出现的条件简化如下:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}此代码会编译为条件跳转(b.le 和 cbnz 指令)。当 CPU 遇到条件分支时,在计算出条件之前,它无法知道是否会采用该分支,因此不知道接下来要读取哪条指令,必须使用一种称为分支预测的技术进行猜测。在二分搜索等情况下,分支方向在每个步骤中都会以不可预测的方式发生变化,因此很可能有一半的预测是错误的。在搜索和排序算法(例如最小堆中使用的算法)中,分支预测通常无效,因为猜错的代价大于猜对带来的改进。如果分支预测器猜错,就必须舍弃在假设预测值后所做的工作,并从实际采用的路径重新开始,这称为流水线刷新。
为了找到此问题,我们使用 branch-misses 性能计数器对基准进行了分析,该计数器会记录分支预测器猜测错误时的堆栈轨迹。然后,我们使用 Google pprof 将结果可视化,如下所示:
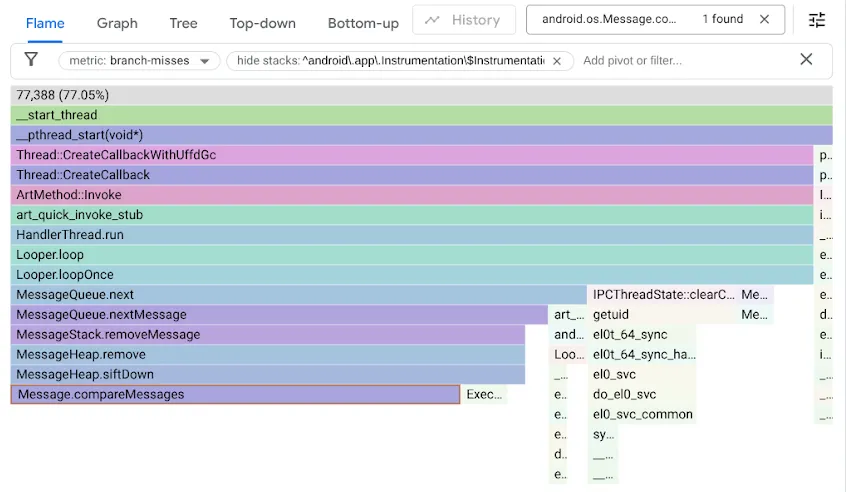
请注意,原始 MessageQueue 代码使用单向链表来实现有序队列。插入操作会按排序顺序遍历列表,以线性搜索方式在第一个超出插入点的元素处停止,并将新的 Message 链接到该元素之前。从头部移除只需解除头部关联。DeliQueue 使用的是最小堆,其中突变需要以对数复杂度在平衡的数据结构中重新排序一些元素(向上或向下过滤),其中任何比较都有相同的机会将遍历定向到左子级或右子级。新算法在渐近线上更快,但由于搜索代码在分支未命中时有一半的时间处于停滞状态,因此会暴露新的瓶颈。
我们意识到分支未命中会减慢堆代码的运行速度,因此使用无分支编程优化了代码:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}为了解优化,请在 Compiler Explorer 中反汇编这两个示例,并使用 LLVM-MCA(一种可生成估计 CPU 周期时间轴的 CPU 模拟器)。
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
请注意,有一个条件分支 b.le,如果通过比较 when 字段已经知道结果,则可以避免比较 insertSeq 字段。
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
在此示例中,无分支实现所用的周期数和指令数甚至比分支代码中的最短路径还要少,因此在所有情况下都更胜一筹。更快的实现速度加上消除了错误预测的分支,使我们在某些基准测试中获得了 5 倍的性能提升!
不过,此技术并非总是适用。无分支方法通常需要执行会被舍弃的工作,如果分支在大多数情况下是可预测的,那么浪费的工作会减慢代码的运行速度。此外,移除分支通常会引入数据依赖项。现代 CPU 在每个周期内执行多项操作,但只有在上一条指令的输入准备就绪后,才能执行下一条指令。相比之下,CPU 可以对分支中的数据进行推测,如果分支预测正确,则可以提前工作。
测试和验证
验证无锁算法的正确性非常困难!
除了在开发过程中进行持续验证的标准单元测试之外,我们还编写了严格的压力测试,以验证队列不变量,并尝试诱发可能存在的数据竞争。在我们的测试实验室中,我们可以在模拟设备和真实硬件上运行数百万个测试实例。
借助 Java ThreadSanitizer (JTSan) 插桩,我们还可以使用相同的测试来检测代码中的一些数据竞态条件。JTSan 未在 DeliQueue 中发现任何有问题的竞态条件,但令人惊讶的是,它实际上在 Robolectric 框架中检测到了两个并发 Bug,我们立即修复了这些 Bug。
为了提升调试能力,我们构建了新的分析工具。以下示例展示了 Android 平台代码中的一个问题,其中一个线程通过 Message 使另一个线程过载,从而导致大量积压,这得益于我们添加的 MessageQueue 插桩功能,可在 Perfetto 中看到此问题。
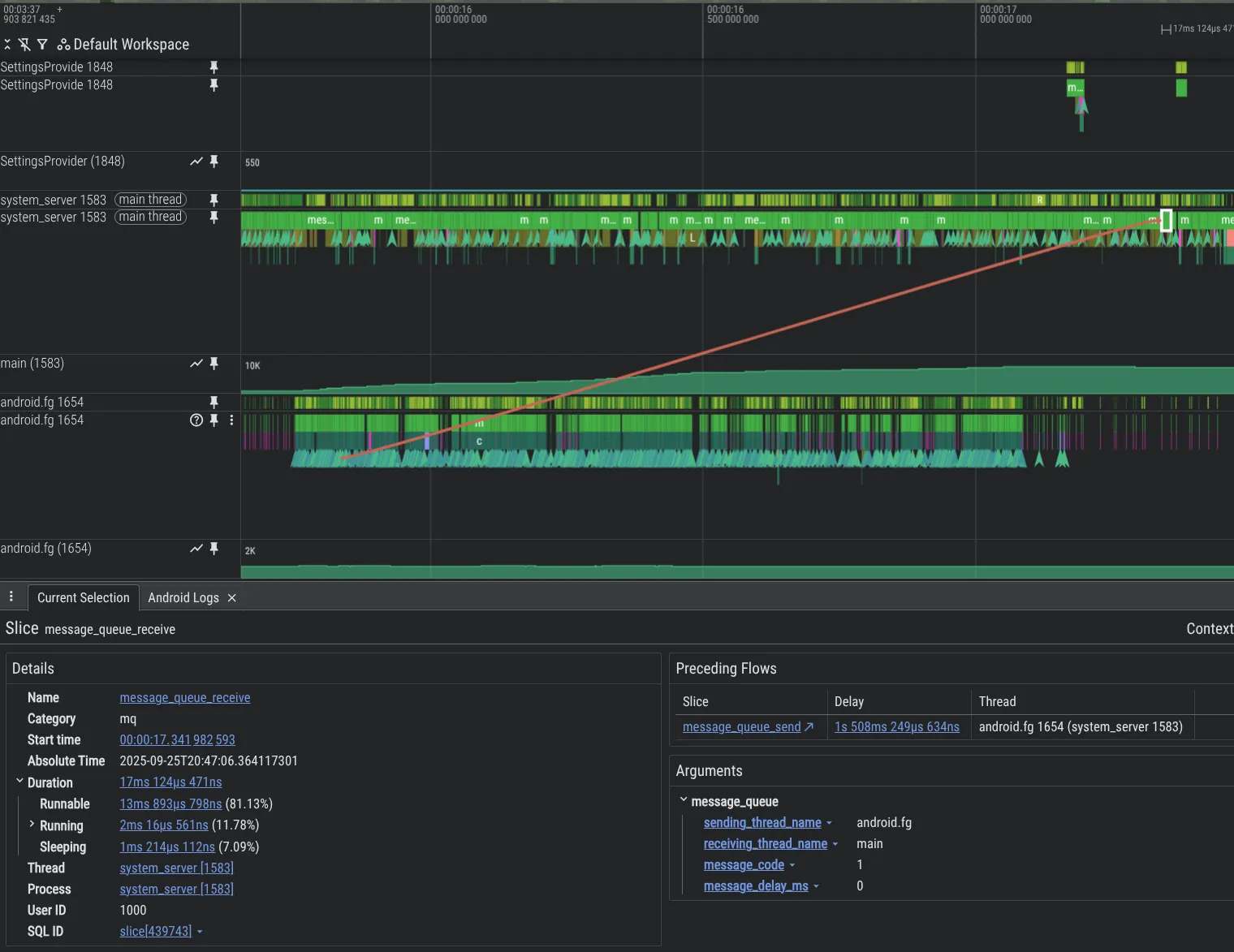
如需在 system_server 进程中启用 MessageQueue 轨迹记录,请在 Perfetto 配置中添加以下内容:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}影响
DeliQueue 通过消除 MessageQueue 中的锁来提高系统和应用性能。
- 合成基准测试:由于改进了并发性(Treiber 堆栈)和插入速度(最小堆),多线程插入到繁忙队列的速度比旧版
MessageQueue快了多达 5,000 倍。 - 在从内部 Beta 版测试人员处获得的 Perfetto 轨迹中,我们发现应用主线程在锁争用中花费的时间减少了 15%。
- 在相同的测试设备上,减少锁争用可显著改善用户体验,例如:
- 应用中的丢帧数减少了 4%。
- 系统界面和启动器互动中的丢帧数减少了 7.7%。
- 从应用启动到绘制第一帧的时间缩短了 9.1%(第 95 百分位)。
后续步骤
DeliQueue 正在面向 Android 17 中的应用推出。应用开发者应查看 Android 开发者博客上有关准备应用以使用新的无锁 MessageQueue 的文章,了解如何测试其应用。
参考编号
[1] Treiber, R.K.,1986 年。系统编程:应对并行性。International Business Machines Incorporated,Thomas J. Watson Research Center。
[2] Goetz, B.,Peierls, T.、Bloch, J.、Bowbeer, J.,Holmes, D.、& Lea, D. (2006)。《Java 并发编程实战》。Addison-Wesley Professional。
-

 产品资讯
产品资讯早在 3 月,我们就推出了 Android Bench,这是我们的大语言模型排行榜,用于评估其在实际 Android 开发任务中的表现。此后,我们根据您的反馈意见对基准进行了增强,包括评估开放权重模型,以及在排行榜中添加费用和效率维度。
Zoe Lopez-Latorre • 阅读用时:3 分钟 -

 产品资讯
产品资讯在 Google Play,我们致力于为用户打造卓越的体验,同时确保开发者拥有取得成功所需的工具和灵活的应变空间。
Paul Feng • 阅读用时:3 分钟 -

 产品资讯
产品资讯去年,我们推出了 Android 开发者验证功能,以加强生态系统安全性,并阻止恶意方隐藏在匿名身份背后发布有害应用。
Matthew Forsythe • 阅读用时:2 分钟
每周通过电子邮件接收最新的 Android 开发洞见。
