


In Android 17 erhalten Apps, die auf SDK 37 oder höher ausgerichtet sind, eine neue Implementierung von MessageQueue, die sperrenfrei ist. Die neue Implementierung verbessert die Leistung und reduziert fehlende Frames, kann aber Clients, die private Felder und Methoden von MessageQueue reflektieren, zum Absturz bringen. Weitere Informationen zur Verhaltensänderung und dazu, wie Sie die Auswirkungen minimieren können In diesem technischen Blogpost finden Sie einen Überblick über die Re-Architektur von MessageQueue und Informationen dazu, wie Sie Konflikte bei der Sperrung mit Perfetto analysieren können.
Der Looper steuert den UI-Thread jeder Android-App. Er ruft Aufgaben aus einer MessageQueue ab, leitet sie an einen Handler weiter und wiederholt den Vorgang. Seit zwei Jahrzehnten verwendet MessageQueue eine einzelne Monitorsperre (d.h. einen synchronized-Codeblock), um den Zustand zu schützen.
Mit Android 17 wird diese Komponente grundlegend aktualisiert: Es wird eine sperrenfreie Implementierung namens DeliQueue eingeführt.
In diesem Beitrag wird erläutert, wie sich Sperren auf die UI-Leistung auswirken, wie Sie diese Probleme mit Perfetto analysieren und welche spezifischen Algorithmen und Optimierungen verwendet werden, um den Android-Hauptthread zu verbessern.
Das Problem: Lock Contention und Priority Inversion
Die alte MessageQueue-Funktion war eine Prioritätswarteschlange, die durch eine einzelne Sperre geschützt wurde. Wenn ein Hintergrundthread eine Nachricht postet, während der Hauptthread die Warteschlange verwaltet, blockiert der Hintergrundthread den Hauptthread.
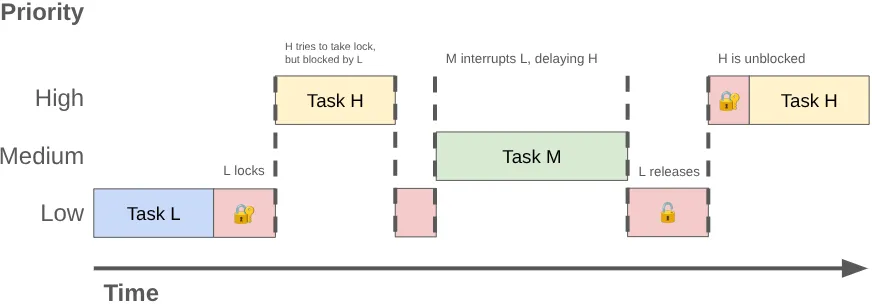
Wenn zwei oder mehr Threads um die exklusive Verwendung derselben Sperre konkurrieren, spricht man von Sperrenkonflikt. Diese Konflikte können zu einer Prioritätsumkehr führen, die wiederum Ruckeln der Benutzeroberfläche und andere Leistungsprobleme zur Folge hat.
Eine Prioritätsumkehr kann auftreten, wenn ein Thread mit hoher Priorität (z. B. der UI-Thread) auf einen Thread mit niedriger Priorität warten muss. Stellen Sie sich folgende Sequenz vor:
- Ein Hintergrundthread mit niedriger Priorität ruft die
MessageQueue-Sperre ab, um das Ergebnis seiner Arbeit zu posten. - Ein Thread mit mittlerer Priorität wird ausführbar und der Scheduler des Kernels weist ihm CPU-Zeit zu, wodurch der Thread mit niedriger Priorität unterbrochen wird.
- Der UI-Thread mit hoher Priorität beendet seine aktuelle Aufgabe und versucht, aus der Warteschlange zu lesen. Er wird jedoch blockiert, da der Thread mit niedriger Priorität die Sperre hält.
Der Thread mit niedriger Priorität blockiert den UI-Thread und die Arbeit mit mittlerer Priorität verzögert ihn zusätzlich.
Konflikte mit Perfetto analysieren
Sie können diese Probleme mit Perfetto diagnostizieren. In einem Standard-Trace wechselt ein Thread, der durch eine Monitor-Sperre blockiert wird, in den Ruhezustand. Perfetto zeigt einen Bereich an, der den Sperreninhaber angibt.
Wenn Sie Trace-Daten abfragen, suchen Sie nach Abschnitten mit dem Namen „monitor contention with …“, gefolgt vom Namen des Threads, der das Lock besitzt, und der Codestelle, an der das Lock erworben wurde.
Fallstudie: Launcher-Ruckeln
Zur Veranschaulichung analysieren wir einen Trace, in dem ein Nutzer auf einem Pixel Smartphone beim Navigieren nach Hause direkt nach dem Aufnehmen eines Fotos in der Kamera-App Ruckeln erlebt hat. Unten sehen wir einen Screenshot von Perfetto mit den Ereignissen, die zum verpassten Frame geführt haben:
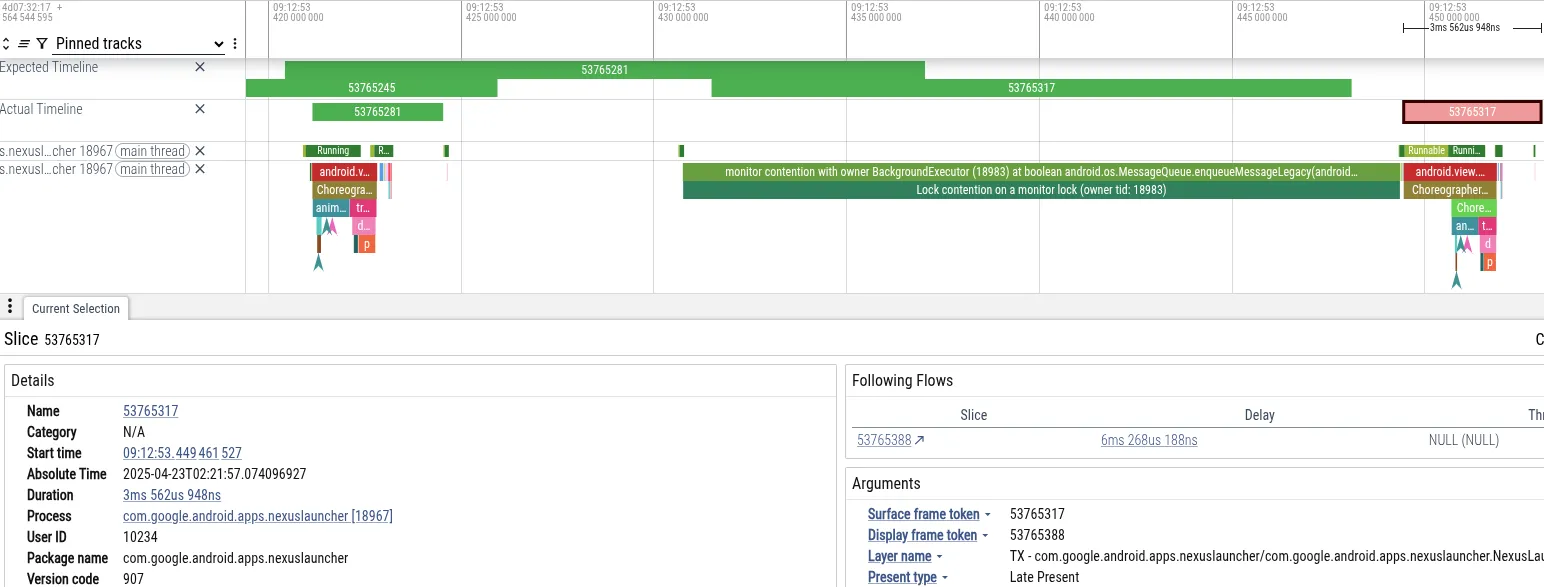
- Symptom:Der Hauptthread des Launchers hat die Frame-Deadline verpasst. Es wurde 18 ms lang blockiert, was das für das Rendern mit 60 Hz erforderliche Zeitlimit von 16 ms überschreitet.
- Diagnose:Perfetto hat gezeigt, dass der Hauptthread durch die
MessageQueue-Sperre blockiert wurde. Ein „BackgroundExecutor“-Thread hatte die Sperre. - Ursache:Der BackgroundExecutor wird mit Process.THREAD_PRIORITY_BACKGROUND (sehr niedrige Priorität) ausgeführt. Es wurde eine nicht dringende Aufgabe ausgeführt (Prüfen der App-Nutzungslimits). Gleichzeitig haben Threads mit mittlerer Priorität CPU-Zeit zum Verarbeiten von Daten von der Kamera verwendet. Der Betriebssystem-Scheduler hat den BackgroundExecutor-Thread unterbrochen, um die Kamerathreads auszuführen.
Durch diese Abfolge wurde der UI-Thread des Launchers (hohe Priorität) indirekt durch den Kamera-Arbeitsthread (mittlere Priorität) blockiert, wodurch der Hintergrund-Thread des Launchers (niedrige Priorität) die Sperre nicht freigeben konnte.
Traces mit PerfettoSQL abfragen
Mit PerfettoSQL können Sie Tracedaten nach bestimmten Mustern abfragen. Das ist nützlich, wenn Sie eine große Anzahl von Traces von Nutzergeräten oder Tests haben und nach bestimmten Traces suchen, die ein Problem aufzeigen.
Mit dieser Abfrage wird beispielsweise nach MessageQueue-Konflikten gesucht, die mit Frame-Drops (Ruckeln) zusammenfallen:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
In diesem komplexeren Beispiel werden Tracedaten aus mehreren Tabellen zusammengeführt, um Konflikte in MessageQueue während des App-Starts zu ermitteln:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Sie können Ihr bevorzugtes LLM verwenden, um PerfettoSQL-Abfragen zu schreiben, mit denen Sie andere Muster finden.
Bei Google verwenden wir BigTrace, um PerfettoSQL-Abfragen für Millionen von Traces auszuführen. Dabei haben wir bestätigt, dass es sich bei dem, was wir anekdotisch beobachtet haben, tatsächlich um ein systemisches Problem handelt. Die Daten haben gezeigt, dass MessageQueue-Konflikte Nutzer im gesamten Ökosystem betreffen, was die Notwendigkeit einer grundlegenden Architekturänderung untermauert.
Lösung: Sperrfreie Parallelität
Wir haben das Problem der MessageQueue-Konkurrenz behoben, indem wir eine sperrfreie Datenstruktur implementiert haben, die atomare Speicheroperationen anstelle von exklusiven Sperren verwendet, um den Zugriff auf den freigegebenen Status zu synchronisieren. Eine Datenstruktur oder ein Algorithmus ist sperrfrei, wenn mindestens ein Thread unabhängig vom Scheduling-Verhalten der anderen Threads immer Fortschritte machen kann. Diese Eigenschaft ist im Allgemeinen schwer zu erreichen und für den meisten Code in der Regel nicht lohnenswert.
Die atomaren Primitiven
Sperrfreie Software basiert häufig auf atomaren Read-Modify-Write-Primitiven, die von der Hardware bereitgestellt werden.
Bei älteren ARM64-CPUs wurde für Atomics eine Load-Link/Store-Conditional-Schleife (LL/SC) verwendet. Die CPU lädt einen Wert und markiert die Adresse. Wenn ein anderer Thread in diese Adresse schreibt, schlägt der Speichervorgang fehl und die Schleife wird wiederholt. Da die Threads immer wieder versuchen können, ohne auf einen anderen Thread zu warten, ist dieser Vorgang sperrenfrei.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr(Im Compiler Explorer ansehen)
Neuere ARM-Architekturen (ARMv8.1) unterstützen Large System Extensions (LSE), die Anweisungen in Form von Compare-And-Swap (CAS) oder Load-And-Add (siehe unten) enthalten. In Android 17 haben wir dem ART-Compiler (Android Runtime) Unterstützung hinzugefügt, um zu erkennen, wann LSE unterstützt wird, und optimierte Anweisungen auszugeben:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.In unseren Benchmarks wird bei Code mit hoher Konfliktdichte, der CAS verwendet, eine etwa dreifache Beschleunigung gegenüber der LL/SC-Variante erreicht.
Die Programmiersprache Java bietet atomare Primitiven über java.util.concurrent.atomic, die auf diesen und anderen speziellen CPU-Befehlen basieren.
Die Datenstruktur: DeliQueue
Um die Sperrkonflikte in MessageQueue zu beseitigen, haben unsere Entwickler eine neuartige Datenstruktur namens DeliQueue entwickelt. Bei DeliQueue wird das Einfügen von Message von der Verarbeitung von Message getrennt:
- Die Liste der
Messages(Treiber-Stack): Ein sperrfreier Stack. Jeder Thread kann hier ohne Konflikte neueMessageseinfügen. - Prioritätswarteschlange (Min-Heap): Ein Heap mit
Messages, der ausschließlich vom Looper-Thread verwaltet wird. Daher sind für den Zugriff keine Synchronisierung oder Sperren erforderlich.
Enqueue: Pushing to a Treiber stack
Die Liste der Messages wird in einem Treiber-Stack [1] gespeichert, einem sperrfreien Stack, in dem der Head-Pointer mit einer CAS-Schleife aktualisiert wird.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Quellcode basierend auf Java Concurrency in Practice [2], online verfügbar und in der Public Domain veröffentlicht
Jeder Producer kann jederzeit neue Messages in den Stack einfügen. Das ist so, als würden Sie an einer Theke eine Nummer ziehen. Ihre Nummer wird dadurch bestimmt, wann Sie angekommen sind, aber die Reihenfolge, in der Sie Ihr Essen erhalten, muss nicht damit übereinstimmen. Da es sich um einen verknüpften Stapel handelt, ist jedes Message ein Unterstapel. Sie können jederzeit sehen, wie die Message-Warteschlange aussah, indem Sie den Anfang verfolgen und vorwärts iterieren. Es werden keine neuen Messages oben hinzugefügt, auch wenn sie während des Durchlaufs hinzugefügt werden.
Aus der Warteschlange entfernen: Bulk-Übertragung in einen Min-Heap
Um das nächste zu verarbeitende Message zu finden, verarbeitet der Looper neue Messages aus dem Treiber-Stack, indem er den Stack von oben nach unten durchläuft und so lange iteriert, bis er das letzte Message findet, das er zuvor verarbeitet hat. Während der Looper den Stack durchläuft, fügt er Messages in den nach Frist geordneten Min-Heap ein. Da der Looper ausschließlich den Heap besitzt, ordnet und verarbeitet er Messages ohne Sperren oder Atomics.

Beim Durchlaufen des Stapels werden durch das Looper auch Links von gestapelten Messages zurück zu ihren Vorgängern erstellt, wodurch eine doppelt verkettete Liste entsteht. Das Erstellen der verknüpften Liste ist sicher, da Links, die im Stapel nach unten zeigen, über den Treiberstapelalgorithmus mit CAS hinzugefügt werden und Links, die im Stapel nach oben zeigen, nur vom Looper-Thread gelesen und geändert werden. Diese Backlinks werden dann verwendet, um Messages in O(1) Zeit von beliebigen Stellen im Stack zu entfernen.
Dieses Design bietet eine Einfügung von O(1) für Ersteller (Threads, die Arbeit in die Warteschlange stellen) und eine amortisierte Verarbeitung von O(log N) für den Consumer (die Looper).
Die Verwendung eines Min-Heaps zum Sortieren von Messages behebt auch einen grundlegenden Fehler im alten MessageQueue, bei dem Messages in einer einfach verketteten Liste (mit dem Stamm oben) gespeichert wurden. In der alten Implementierung war das Entfernen aus dem Head O(1), das Einfügen hatte jedoch einen Worst-Case-Wert von O(N) – was bei überlasteten Warteschlangen zu einer schlechten Skalierung führte. Das Einfügen in und Entfernen aus dem Min-Heap skaliert logarithmisch. Das führt zu einer wettbewerbsfähigen durchschnittlichen Leistung, aber vor allem zu einer hervorragenden Leistung bei Tail-Latenzen.
Legacy (gesperrt) MessageQueue | DeliQueue | |
| Einfügen | O(N) | O(1) für den aufrufenden Thread O(logN) für |
| Vom Kopf entfernen | O(1) | O(logN) |
In der alten Warteschlangenimplementierung verwendeten Producer und Consumer ein Lock, um den exklusiven Zugriff auf die zugrunde liegende einfach verkettete Liste zu koordinieren. In DeliQueue wird der gleichzeitige Zugriff vom Treiber-Stack verwaltet und der einzelne Consumer kümmert sich um die Reihenfolge seiner Arbeitswarteschlange.
Entfernung: Konsistenz durch Tombstones
DeliQueue ist eine hybride Datenstruktur, die einen sperrenfreien Treiber-Stack mit einem Single-Thread-Min-Heap kombiniert. Diese beiden Strukturen ohne globale Sperre zu synchronisieren, ist eine besondere Herausforderung: Eine Nachricht kann physisch im Stack vorhanden, aber logisch aus der Warteschlange entfernt sein.
Um dieses Problem zu lösen, verwendet DeliQueue eine Technik namens „Tombstoning“. Jedes Message verfolgt seine Position im Stapel über die Rückwärts- und Vorwärtszeiger, seinen Index im Array des Heaps und ein boolesches Flag, das angibt, ob es entfernt wurde. Wenn ein Message bereit ist, ausgeführt zu werden, wird das Flag „removed“ des Looper-Threads per CAS gesetzt. Anschließend wird das Message aus dem Heap und dem Stack entfernt.
Wenn ein anderer Thread ein Message entfernen muss, wird es nicht sofort aus der Datenstruktur extrahiert. Stattdessen werden die folgenden Schritte ausgeführt:
- Logisches Entfernen: Der Thread verwendet CAS, um das Entfernungsflag von
Messageatomar von „false“ auf „true“ zu setzen. DieMessagebleibt als Nachweis für die anstehende Entfernung in der Datenstruktur, ein sogenannter „Tombstone“. Sobald eineMessagezur Entfernung gekennzeichnet ist, behandelt DeliQueue sie so, als ob sie nicht mehr in der Warteschlange vorhanden wäre. - Verzögerte Bereinigung: Das tatsächliche Entfernen aus der Datenstruktur liegt in der Verantwortung des
Looper-Threads und wird auf später verschoben. Anstatt den Stack oder Heap zu ändern, fügt der Entfernungs-Thread dasMessageeinem anderen sperrfreien Freelist-Stack hinzu. - Strukturelles Entfernen: Nur die
Looperkann mit dem Heap interagieren oder Elemente aus dem Stapel entfernen. Wenn sie aktiviert wird, leert sie die Freelist und verarbeitet die darin enthaltenenMessages. JedeMessagewird dann vom Stapel entkoppelt und aus dem Heap entfernt.
Bei diesem Ansatz wird die gesamte Verwaltung des Heaps in einem einzigen Thread ausgeführt. Dadurch wird die Anzahl der erforderlichen gleichzeitigen Vorgänge und Memory Barriers minimiert, was den kritischen Pfad schneller und einfacher macht.
Traversal: benigne Java-Speichermodell-Data-Races
Die meisten APIs für die Parallelverarbeitung, z. B. Future in der Java-Standardbibliothek oder Job und Deferred in Kotlin, enthalten einen Mechanismus zum Abbrechen von Vorgängen, bevor sie abgeschlossen sind. Eine Instanz einer dieser Klassen entspricht 1:1 einer Einheit der zugrunde liegenden Arbeit. Wenn Sie cancel für ein Objekt aufrufen, werden die zugehörigen Vorgänge abgebrochen.
Moderne Android-Geräte haben Multi-Core-CPUs und eine gleichzeitige, generationenübergreifende automatische Speicherbereinigung. Als Android entwickelt wurde, war es jedoch zu teuer, für jede Arbeitseinheit ein Objekt zuzuweisen. Daher unterstützt Handler in Android die Kündigung über zahlreiche Überladungen von removeMessages. Anstatt ein bestimmtes Message zu entfernen, werden alle Messages entfernt, die den angegebenen Kriterien entsprechen. In der Praxis bedeutet das, dass alle Messages durchlaufen werden müssen, die vor dem Aufruf von removeMessages eingefügt wurden, und die übereinstimmenden entfernt werden müssen.
Beim Vorwärtsiterieren ist für einen Thread nur ein geordneter atomarer Vorgang erforderlich, um den aktuellen Anfang des Stapels zu lesen. Danach werden normale Feldlesevorgänge verwendet, um das nächste Message zu finden. Wenn der Looper-Thread die next-Felder ändert, während Messages entfernt werden, sind der Schreibvorgang von Looper und der Lesevorgang eines anderen Threads nicht synchronisiert. Dies ist ein Data Race. Normalerweise ist ein Data Race ein schwerwiegender Fehler, der in Ihrer App zu großen Problemen führen kann, z. B. zu Lecks, Endlosschleifen, Abstürzen und Einfrieren. Unter bestimmten engen Bedingungen können Data Races jedoch im Java-Speichermodell harmlos sein. Angenommen, wir beginnen mit einem Stapel mit folgenden Elementen:

Wir führen einen atomaren Lesevorgang des Head-Elements durch und sehen A. Der Next-Pointer von A verweist auf B. Während wir B verarbeiten, entfernt der Looper möglicherweise B und C, indem er A so aktualisiert, dass es auf C und dann auf D verweist.
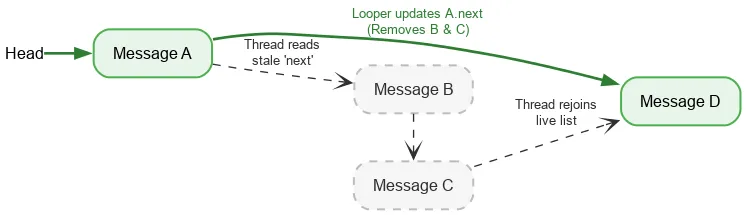
Obwohl B und C logisch entfernt werden, behält B seinen Next-Zeiger auf C und C auf D bei. Der Lesethread durchläuft weiterhin die getrennten entfernten Knoten und wird schließlich bei D wieder in den Live-Stack eingefügt.
Da DeliQueue so konzipiert ist, dass es Race Conditions zwischen dem Durchlaufen und dem Entfernen verarbeitet, ist eine sichere, sperrenfreie Iteration möglich.
Beenden: Native refcount
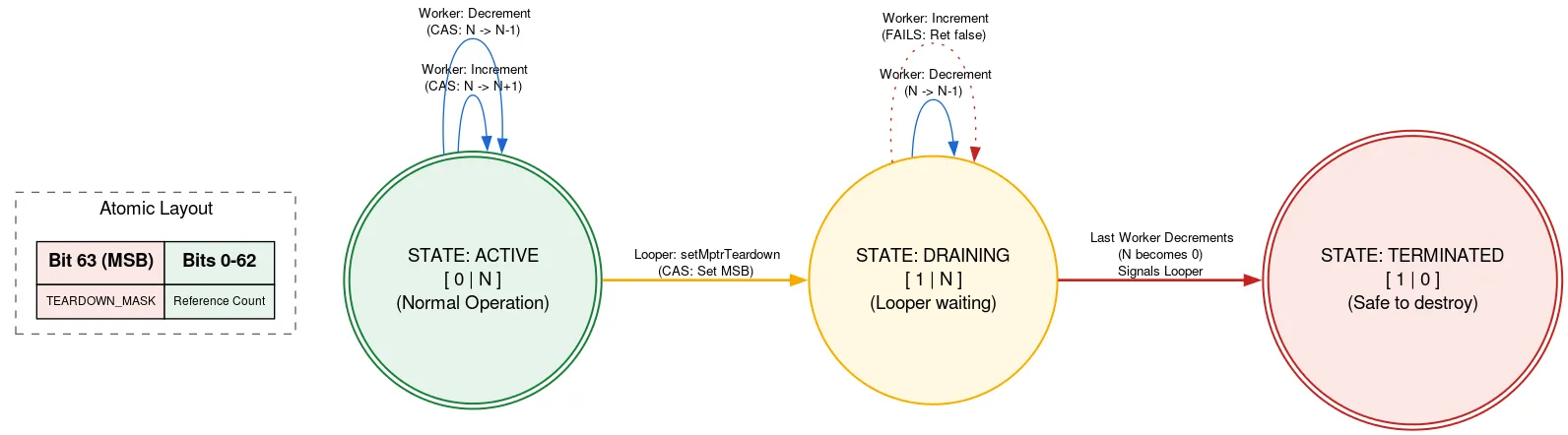
Looper wird durch eine native Zuweisung unterstützt, die manuell freigegeben werden muss, sobald Looper beendet wurde. Wenn ein anderer Thread Messages hinzufügt, während Looper beendet wird, kann er die native Zuweisung nach dem Freigeben verwenden, was einen Verstoß gegen die Speichersicherheit darstellt. Wir verhindern dies mithilfe eines getaggten Referenzzählers, bei dem ein Bit des Atomars verwendet wird, um anzugeben, ob Looper beendet wird.
Bevor die native Zuweisung verwendet wird, liest ein Thread den atomaren Referenzzähler. Wenn das Beendigungsbit gesetzt ist, wird zurückgegeben, dass Looper beendet wird und die native Zuweisung nicht verwendet werden darf. Andernfalls wird versucht, die Anzahl der aktiven Threads mit der nativen Zuweisung zu erhöhen. Nachdem der Thread seine Aufgabe erledigt hat, wird die Anzahl verringert. Wenn das Beendigungsbit nach der Erhöhung, aber vor der Verringerung gesetzt wurde und die Anzahl jetzt null ist, wird der Looper-Thread reaktiviert.
Wenn der Looper-Thread bereit ist, beendet er sich mithilfe von CAS und legt das Beendigungsbit im Atom fest. Wenn der Referenzzähler 0 war, kann die native Zuweisung freigegeben werden. Andernfalls wird sie in den Ruhezustand versetzt, da sie weiß, dass sie reaktiviert wird, wenn der letzte Nutzer der nativen Zuweisung den Referenzzähler dekrementiert. Bei diesem Ansatz wartet der Looper-Thread auf den Fortschritt anderer Threads, aber nur, wenn er beendet wird. Das passiert nur einmal und ist nicht leistungsabhängig. Der andere Code für die Verwendung der nativen Zuweisung bleibt vollständig sperrfrei.
Die Implementierung ist noch viel komplexer. Weitere Informationen zu DeliQueue finden Sie im Quellcode.
Optimierung: Programmierung ohne Verzweigungen
Bei der Entwicklung und beim Testen von DeliQueue hat das Team viele Benchmarks ausgeführt und den neuen Code sorgfältig analysiert. Ein Problem, das mit dem simpleperf-Tool identifiziert wurde, waren Pipeline-Flushes, die durch den Message-Vergleichscode verursacht wurden.
Ein Standardvergleich nutzt bedingte Sprünge. Die Bedingung, mit der entschieden wird, welche Message zuerst kommt, wird unten vereinfacht dargestellt:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Dieser Code wird in bedingte Sprünge (b.le- und cbnz-Befehle) kompiliert. Wenn die CPU auf eine bedingte Verzweigung trifft, kann sie erst dann feststellen, ob die Verzweigung erfolgt, wenn die Bedingung berechnet wurde. Sie weiß also nicht, welche Anweisung als Nächstes gelesen werden soll, und muss raten. Dazu wird eine Technik namens Sprungvorhersage verwendet. Bei einer binären Suche ändert sich die Richtung des Zweigs in jedem Schritt unvorhersehbar. Daher ist es wahrscheinlich, dass die Hälfte der Vorhersagen falsch ist. Die Zweigvorhersage ist bei Such- und Sortieralgorithmen (z. B. bei einem Min-Heap) oft ineffektiv, da die Kosten für eine falsche Vermutung höher sind als die Verbesserung durch eine richtige Vermutung. Wenn der Branch-Predictor falsch rät, muss er die Arbeit verwerfen, die er nach der Annahme des vorhergesagten Werts geleistet hat, und noch einmal mit dem tatsächlich eingeschlagenen Pfad beginnen. Dies wird als Pipeline-Flush bezeichnet.
Um dieses Problem zu finden, haben wir unsere Benchmarks mit dem Leistungszähler branch-misses profiliert, der Stacktraces aufzeichnet, in denen die Zweigvorhersage falsch ist. Anschließend haben wir die Ergebnisse mit Google pprof visualisiert, wie unten dargestellt:
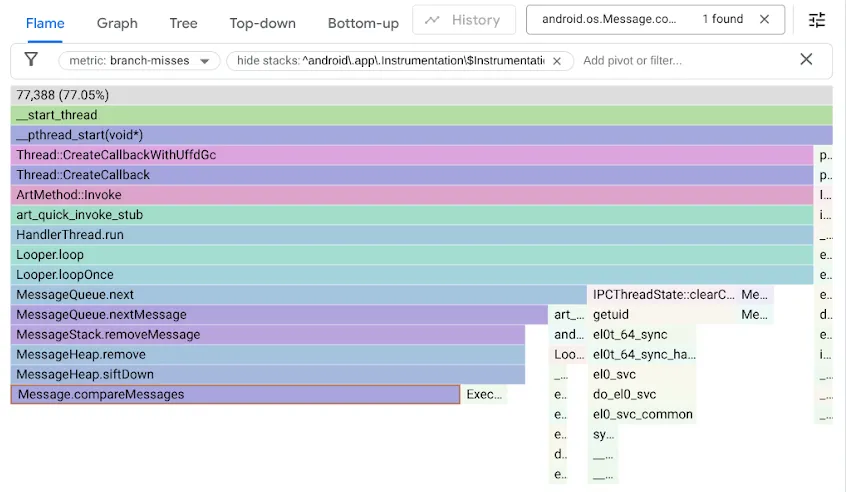
Der ursprüngliche MessageQueue-Code verwendete eine einfach verkettete Liste für die geordnete Warteschlange. Beim Einfügen würde die Liste in sortierter Reihenfolge als lineare Suche durchlaufen. Die Suche würde beim ersten Element beendet, das nach der Einfügestelle liegt, und das neue Message würde davor verknüpft. Zum Entfernen des Head musste lediglich die Verknüpfung aufgehoben werden. DeliQueue verwendet einen Min-Heap, bei dem Mutationen das Umsortieren einiger Elemente (Sifting up oder down) mit logarithmischer Komplexität in einer ausgeglichenen Datenstruktur erfordern, in der jede Vergleichsoperation eine gleichmäßige Wahrscheinlichkeit hat, die Traversierung zu einem linken oder rechten untergeordneten Element zu lenken. Der neue Algorithmus ist asymptotisch schneller, aber es gibt einen neuen Engpass, da der Suchcode die Hälfte der Zeit bei Branch-Misses hängen bleibt.
Da wir festgestellt haben, dass sich die Branch-Fehler auf unseren Heap-Code auswirkten, haben wir den Code mit Branch-Free Programming optimiert:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Um die Optimierung nachzuvollziehen, zerlegen Sie die beiden Beispiele im Compiler Explorer und verwenden Sie LLVM-MCA, einen CPU-Simulator, der eine geschätzte Zeitachse der CPU-Zyklen generieren kann.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Beachten Sie den bedingten Zweig b.le, mit dem der Vergleich der Felder insertSeq vermieden wird, wenn das Ergebnis bereits durch den Vergleich der Felder when bekannt ist.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Hier benötigt die verzweigungslose Implementierung weniger Zyklen und Anweisungen als selbst der kürzeste Pfad durch den verzweigten Code – sie ist in allen Fällen besser. Die schnellere Implementierung und die Eliminierung falsch vorhergesagter Verzweigungen führten in einigen unserer Benchmarks zu einer fünffachen Verbesserung.
Diese Technik ist jedoch nicht immer anwendbar. Bei branchlosen Ansätzen ist in der Regel Arbeit erforderlich, die verworfen wird. Wenn die Verzweigung die meiste Zeit vorhersehbar ist, kann diese verschwendete Arbeit Ihren Code verlangsamen. Außerdem wird durch das Entfernen einer Verzweigung häufig eine Datenabhängigkeit eingeführt. Moderne CPUs führen mehrere Vorgänge pro Zyklus aus, können eine Anweisung jedoch erst ausführen, wenn die Eingaben aus einer vorherigen Anweisung bereit sind. Im Gegensatz dazu kann eine CPU spekulieren, welche Daten in Verzweigungen verwendet werden, und vorarbeiten, wenn eine Verzweigung richtig vorhergesagt wird.
Tests und Validierung
Die Korrektheit von sperrfreien Algorithmen zu validieren ist notorisch schwierig.
Zusätzlich zu den standardmäßigen Unit-Tests für die kontinuierliche Validierung während der Entwicklung haben wir auch strenge Belastungstests geschrieben, um die Invarianten der Warteschlange zu überprüfen und zu versuchen, Datenkonflikte zu verursachen, falls sie vorhanden waren. In unseren Testlabors konnten wir Millionen von Testinstanzen auf emulierten Geräten und auf echter Hardware ausführen.
Mit der Instrumentierung Java ThreadSanitizer (JTSan) konnten wir mit denselben Tests auch einige Data Races in unserem Code erkennen. JTSan hat in DeliQueue keine problematischen Data Races gefunden, aber überraschenderweise zwei Parallelitätsfehler im Robolectric-Framework erkannt, die wir umgehend behoben haben.
Zur Verbesserung unserer Debugging-Funktionen haben wir neue Analysetools entwickelt. Das folgende Beispiel zeigt ein Problem im Android-Plattformcode, bei dem ein Thread einen anderen Thread mit Message überlastet, was zu einem großen Rückstand führt. Dieser ist in Perfetto dank der von uns hinzugefügten MessageQueue-Instrumentierungsfunktion sichtbar.
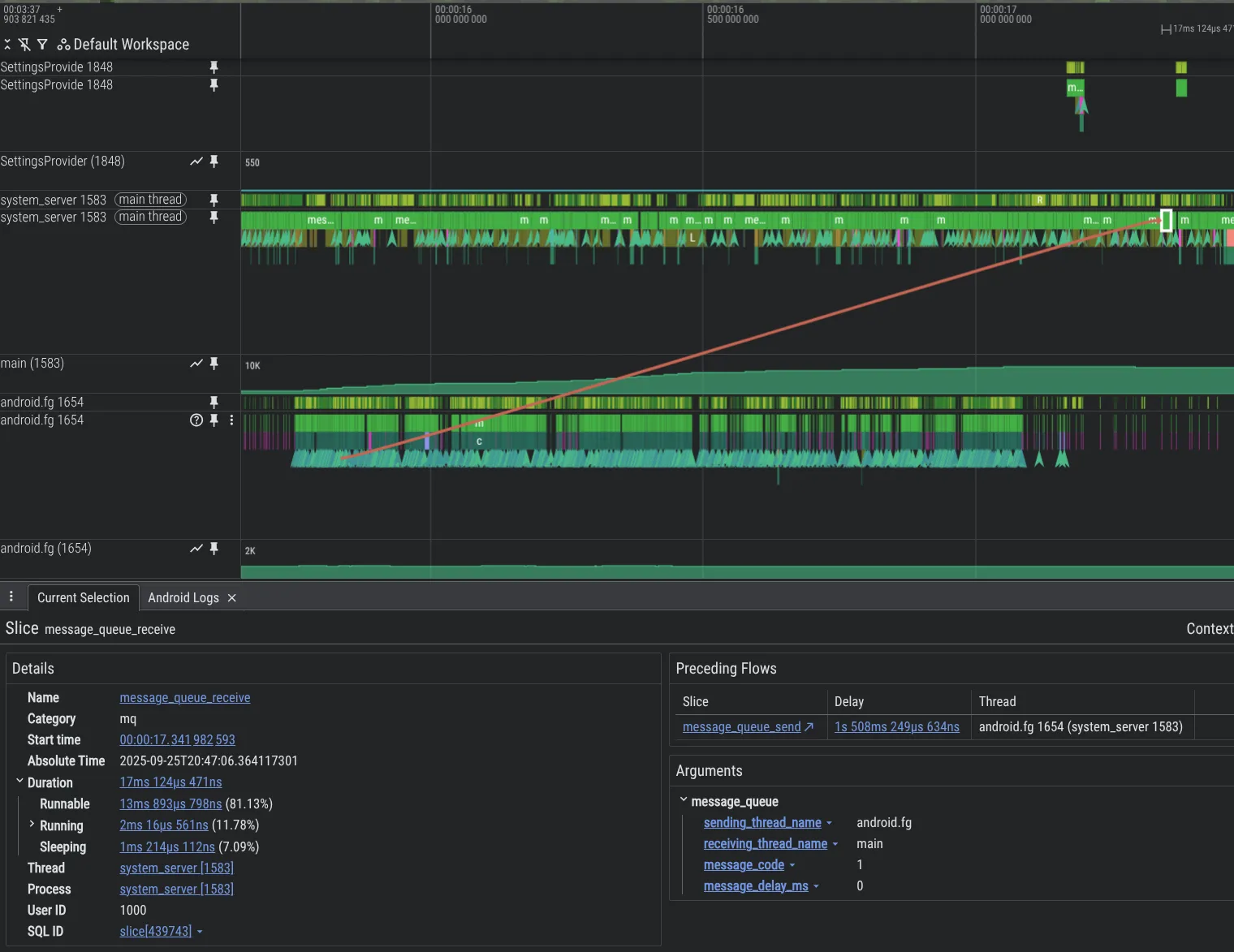
Wenn Sie das MessageQueue-Tracing im system_server-Prozess aktivieren möchten, fügen Sie Folgendes in Ihre Perfetto-Konfiguration ein:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Auswirkungen
DeliQueue verbessert die System- und App-Leistung, indem Sperren aus MessageQueue entfernt werden.
- Synthetische Benchmarks:Das Einfügen von Multithreads in ausgelastete Warteschlangen ist dank verbesserter Nebenläufigkeit (Treiber-Stack) und schnellerem Einfügen (Min-Heap) bis zu 5.000-mal schneller als bei der alten
MessageQueue. - In Perfetto-Traces von internen Betatestern sehen wir eine Reduzierung der Zeit, die der Hauptthread der App mit Sperrkonflikten verbringt, um 15 %.
- Auf denselben Testgeräten führt die reduzierte Sperrenkonkurrenz zu erheblichen Verbesserungen der Nutzerfreundlichkeit, z. B.:
- 4% weniger ausgelassene Frames in Apps.
- –7,7% verpasste Frames bei System-UI- und Launcher-Interaktionen
- –9, 1 % bei der Zeit vom App-Start bis zum Rendern des ersten Frames (95.Perzentil).
Weiteres Vorgehen
DeliQueue wird für Apps in Android 17 eingeführt. App-Entwickler sollten sich im Android-Entwicklerblog ansehen, wie sie ihre Apps für die neue schlosslose MessageQueue vorbereiten und testen können.
Verweise
[1] Treiber, R.K., 1986. Systemprogrammierung: Umgang mit Parallelität. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Verfasst von:
Weiterlesen
-



Produktneuheiten
Das Android XR-Ökosystem wächst rasant – von Augmented-Overlays bis hin zu vollständig immersiven Umgebungen. Das Samsung Galaxy XR ist bereits heute verfügbar.
Stevan Silva, Vinny DaSilva • Lesezeit: 3 Minuten
-


Produktneuheiten
Auf der Google I/O werden jedes Jahr neue Ankündigungen und Ressourcen für Ökosysteme und Produkte, einschließlich der Android-Entwicklung, vorgestellt. Da sich die Entwicklung hin zu KI- und Agent-basierten Tools verschiebt, haben wir unser Angebot erweitert, um Sie bei der Entwicklung für Android besser zu unterstützen.
Simona Milanovic • Lesezeit: 2 Minuten
-

Produktneuheiten
Auf der Google I/O 2026 haben wir gezeigt, wie Sie mit den neuesten Entwicklungen im Android-Ökosystem die Qualität Ihrer App steigern und gleichzeitig die Entwicklungseffizienz maximieren können.
Ataul Munim • Lesezeit: 3 Minuten
Auf dem Laufenden bleiben
Lassen Sie sich Woche für Woche die neuesten Informationen zur Android-Entwicklung zusenden.
