



En Android 17, las aplicaciones orientadas al SDK 37 o a una versión posterior recibirán una nueva implementación de MessageQueue en la que la implementación no tiene bloqueos. La nueva implementación mejora el rendimiento y reduce los fotogramas perdidos, pero puede provocar errores en los clientes que reflejan los campos y métodos privados de MessageQueue. Para obtener más información sobre el cambio de comportamiento y cómo puedes mitigar su impacto, consulta la documentación sobre el cambio de comportamiento de MessageQueue. En esta entrada de blog técnica se ofrece una descripción general de la reestructuración de MessageQueue y se explica cómo analizar los problemas de contención de bloqueos con Perfetto.
El Looper controla el hilo de UI de todas las aplicaciones Android. Extrae el trabajo de un MessageQueue, lo envía a un Handler y repite el proceso. Durante dos décadas, MessageQueue ha usado un único bloqueo de monitor (es decir, un bloque de código synchronized) para proteger su estado.
Android 17 introduce una actualización importante en este componente: una implementación sin bloqueos llamada DeliQueue.
En esta entrada se explica cómo afectan los bloqueos al rendimiento de la interfaz de usuario, cómo analizar estos problemas con Perfetto y los algoritmos y las optimizaciones específicos que se usan para mejorar el hilo principal de Android.
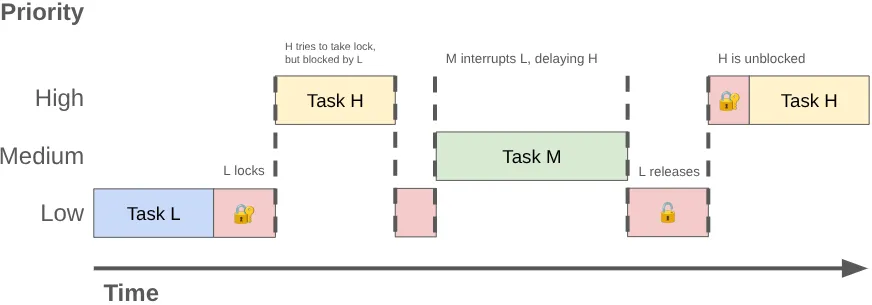
El problema: contención de bloqueos e inversión de prioridades
La función antigua MessageQueue funcionaba como una cola de prioridad protegida por un solo bloqueo. Si un subproceso en segundo plano publica un mensaje mientras el subproceso principal realiza el mantenimiento de la cola, el subproceso en segundo plano bloquea el subproceso principal.
Cuando dos o más hilos compiten por el uso exclusivo del mismo bloqueo, se denomina contención de bloqueo. Esta contención puede provocar una inversión de prioridad, lo que puede provocar tirones en la interfaz de usuario y otros problemas de rendimiento.
La inversión de prioridades puede ocurrir cuando se hace que un hilo de alta prioridad (como el hilo de UI) espere a un hilo de baja prioridad. Considera esta secuencia:
- Un hilo de fondo de baja prioridad adquiere el bloqueo
MessageQueuepara publicar el resultado del trabajo que ha realizado. - Un hilo de prioridad media se puede ejecutar y el programador del kernel le asigna tiempo de CPU, lo que interrumpe el hilo de baja prioridad.
- El hilo de UI de alta prioridad termina su tarea actual e intenta leer de la cola, pero se bloquea porque el hilo de baja prioridad tiene el bloqueo.
El hilo de baja prioridad bloquea el hilo de UI y el trabajo de prioridad media lo retrasa aún más.
Analizar la contención con Perfetto
Puedes diagnosticar estos problemas con Perfetto. En un rastreo estándar, un subproceso bloqueado en un bloqueo de monitor entra en el estado de suspensión y Perfetto muestra un segmento que indica el propietario del bloqueo.
Cuando consultes datos de trazas, busca segmentos llamados "monitor contention with …" (monitor de contención con …) seguido del nombre del subproceso que tiene el bloqueo y el sitio del código en el que se adquirió el bloqueo.
Caso práctico: jank del menú de aplicaciones
Para ilustrarlo, vamos a analizar un registro en el que un usuario ha experimentado un tirón al ir a la pantalla de inicio en un teléfono Pixel inmediatamente después de hacer una foto con la aplicación Cámara. A continuación, vemos una captura de pantalla de Perfetto que muestra los eventos que han provocado el tirón:
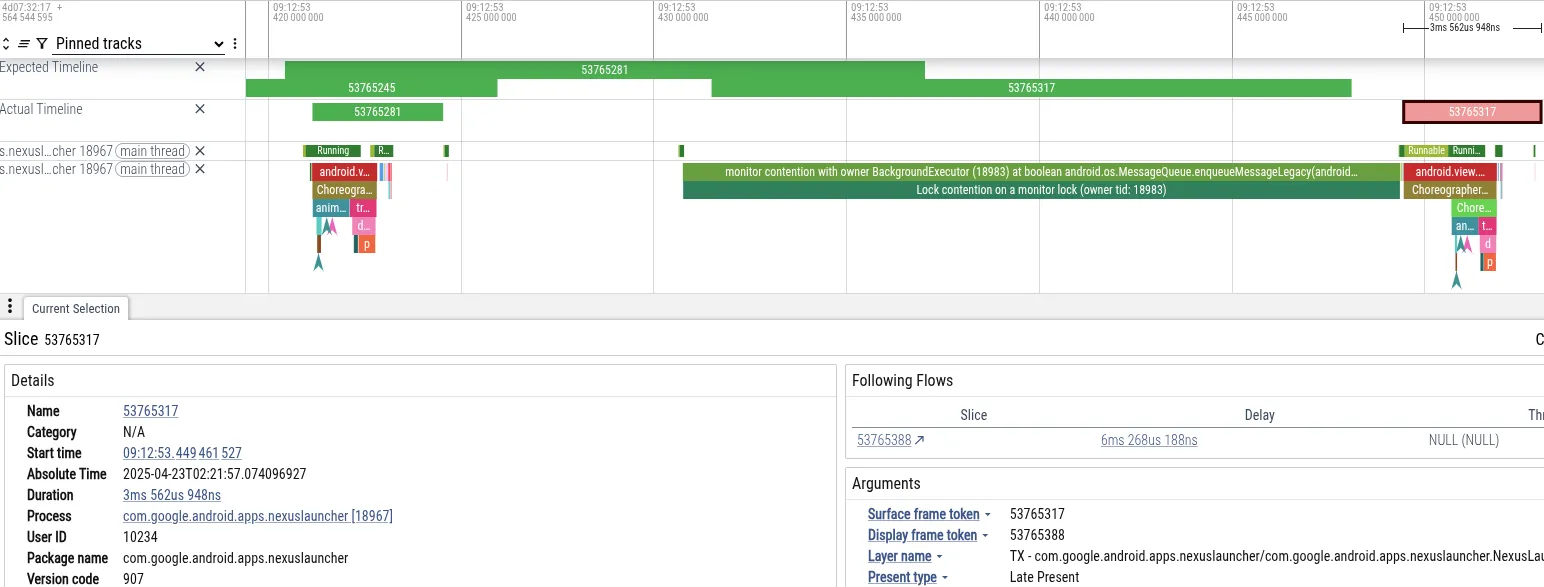
- Síntoma: el hilo principal del Launcher no ha cumplido el plazo de fotogramas. Se ha bloqueado durante 18 ms, lo que supera el plazo de 16 ms necesario para renderizar a 60 Hz.
- Diagnóstico: Perfetto ha mostrado que el hilo principal está bloqueado en el bloqueo
MessageQueue. Un hilo "BackgroundExecutor" era el propietario del bloqueo. - Causa principal: BackgroundExecutor se ejecuta en Process.THREAD_PRIORITY_BACKGROUND (prioridad muy baja). Ha realizado una tarea no urgente (comprobar los límites de uso de aplicaciones). Al mismo tiempo, los hilos de prioridad media usaban tiempo de CPU para procesar datos de la cámara. El programador del SO ha interrumpido el hilo BackgroundExecutor para ejecutar los hilos de la cámara.
Esta secuencia provocó que el hilo de UI del Launcher (alta prioridad) se bloqueara indirectamente por el subproceso de trabajo de la cámara (prioridad media), lo que impedía que el hilo de segundo plano del Launcher (prioridad baja) liberara el bloqueo.
Consultar rastros con PerfettoSQL
Puedes usar PerfettoSQL para consultar datos de traza de patrones específicos. Esto es útil si tienes un gran número de trazas de dispositivos de usuarios o pruebas y buscas trazas específicas que demuestren un problema.
Por ejemplo, esta consulta busca la contención de MessageQueue coincidente con los fotogramas perdidos (jank):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
En este ejemplo más complejo, se unen datos de la traza que abarcan varias tablas para identificar la contención de MessageQueue durante el inicio de la aplicación:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Puedes usar tu LLM favorito para escribir consultas de PerfettoSQL y encontrar otros patrones.
En Google, usamos BigTrace para ejecutar consultas de PerfettoSQL en millones de trazas. Al hacerlo, confirmamos que lo que habíamos observado de forma anecdótica era, de hecho, un problema sistémico. Los datos revelaron que la contención de bloqueos MessageQueue afecta a los usuarios de todo el ecosistema, lo que justifica la necesidad de un cambio arquitectónico fundamental.
Solución: simultaneidad sin bloqueos
Hemos solucionado el problema de contención de MessageQueue implementando una estructura de datos sin bloqueos, que usa operaciones de memoria atómicas en lugar de bloqueos exclusivos para sincronizar el acceso al estado compartido. Una estructura de datos o un algoritmo no tiene bloqueos si al menos un subproceso siempre puede avanzar, independientemente del comportamiento de programación de los demás subprocesos. Por lo general, es difícil conseguir esta propiedad y no suele merecer la pena en la mayoría del código.
Primitivas atómicas
El software sin bloqueos suele basarse en primitivas atómicas de lectura-modificación-escritura que proporciona el hardware.
En las CPUs ARM64 de generaciones anteriores, los atómicos usaban un bucle de carga y enlace/almacenamiento condicional (LL/SC). La CPU carga un valor y marca la dirección. Si otro hilo escribe en esa dirección, el almacenamiento falla y el bucle vuelve a intentarlo. Como los hilos pueden seguir intentándolo y completarse sin esperar a otro hilo, esta operación no tiene bloqueos.
ARM64 LL/SC loop example retry: ldxr x0, [x1] // Load exclusive from address x1 to x0 add x0, x0, #1 // Increment value by 1 stxr w2, x0, [x1] // Store exclusive. // w2 gets 0 on success, 1 on failure cbnz w2, retry // If w2 is non-zero (failed), branch to retr
Las arquitecturas ARM más recientes (ARMv8.1) admiten extensiones de sistema grandes (LSE), que incluyen instrucciones en forma de comparación e intercambio (CAS) o carga y suma (como se muestra más abajo). En Android 17, añadimos compatibilidad con el compilador de Android Runtime (ART) para detectar cuándo se admite LSE y emitir instrucciones optimizadas:
/ ARMv8.1 LSE atomic example ldadd x0, x1, [x2] // Atomic load-add. // Faster, no loop required.
En nuestras comparativas, el código de alta contención que usa CAS consigue una aceleración de unas 3 veces con respecto a la variante LL/SC.
El lenguaje de programación Java ofrece primitivas atómicas a través de java.util.concurrent.atomic, que se basan en estas y otras instrucciones especializadas de la CPU.
Estructura de datos: DeliQueue
Para eliminar la contención de bloqueos de MessageQueue, nuestros ingenieros diseñaron una estructura de datos novedosa llamada DeliQueue. DeliQueue separa la Messageinserción del Messageprocesamiento:
- La lista de
Messages(pila Treiber): una pila sin bloqueos. Cualquier hilo puede insertar nuevosMessagesaquí sin conflictos. - La cola de prioridad (montículo mínimo): un montículo de
Messagesque gestiona el hilo Looper (por lo que no se necesitan sincronizaciones ni bloqueos para acceder).
Poner en cola: enviar a una pila de Treiber
La lista de Messages se mantiene en una pila Treiber [1], una pila sin bloqueo que usa un bucle CAS para actualizar el puntero de encabezado.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Código fuente basado en Java Concurrency in Practice [2], disponible online y publicado en el dominio público
Cualquier productor puede enviar nuevos Messages a la pila en cualquier momento. Es como coger un número en una charcutería: el número se determina en función de cuándo llegues, pero el orden en el que recibes la comida no tiene por qué coincidir. Como se trata de una pila vinculada, cada Message es una subpila. Puedes ver cómo era la cola de Message en cualquier momento haciendo un seguimiento del encabezado e iterando hacia delante. No verás ningún Message nuevo insertado en la parte superior, aunque se añadan durante el recorrido.
Desencolar: transferencia en bloque a un montículo mínimo
Para encontrar el siguiente Message que debe gestionar, el Looper procesa los nuevos Messages de la pila Treiber recorriendo la pila desde la parte superior e iterando hasta que encuentra el último Message que ha procesado anteriormente. A medida que Looper se desplaza hacia abajo en la pila, inserta Messages en el min-heap ordenado por plazo. Como Looper es el único propietario del montículo, ordena y procesa los Messages sin bloqueos ni atómicos.

Al recorrer la pila, Looper también crea enlaces de los Messages apilados a sus predecesores, lo que forma una lista doblemente enlazada. La creación de la lista vinculada es segura porque los enlaces que apuntan hacia abajo en la pila se añaden mediante el algoritmo de pila de Treiber con CAS, y los enlaces que apuntan hacia arriba en la pila solo los lee y modifica el hilo Looper. Estos enlaces se usan para eliminar Messages de puntos arbitrarios de la pila en un tiempo O(1).
Este diseño proporciona una inserción O(1) para los productores (hilos que publican trabajo en la cola) y un procesamiento amortizado O(log N) para el consumidor (el Looper).
Usar un montículo mínimo para ordenar los Messages también resuelve un fallo fundamental del MessageQueue antiguo, en el que los Messages se mantenían en una lista enlazada simple (con la raíz en la parte superior). En la implementación antigua, la eliminación de la cabeza era O(1), pero la inserción tenía un peor caso de O(N), por lo que no se escalaba bien en colas sobrecargadas. Por el contrario, la inserción y la eliminación de elementos en el montículo mínimo se escalan logarítmicamente, lo que ofrece un rendimiento medio competitivo, pero destaca en las latencias de cola.
Antiguo (bloqueado) MessageQueue | DeliQueue | |
| Insertar | O(N) | O(1) para llamar a la conversación O(logN) para |
| Quitar de la cabeza | O(1) | O(logN) |
En la implementación de la cola antigua, los productores y el consumidor usaban un bloqueo para coordinar el acceso exclusivo a la lista enlazada simple subyacente. En DeliQueue, la pila Treiber gestiona el acceso simultáneo y el único consumidor gestiona el orden de su cola de trabajo.
Retirada: coherencia mediante marcadores
DeliQueue es una estructura de datos híbrida que combina una pila Treiber sin bloqueos con un montículo mínimo de un solo subproceso. Mantener sincronizadas estas dos estructuras sin un bloqueo global supone un reto único: un mensaje puede estar físicamente en la pila, pero se puede eliminar lógicamente de la cola.
Para solucionar este problema, DeliQueue usa una técnica llamada "tombstoning". Cada Message registra su posición en la pila mediante los punteros hacia atrás y hacia adelante, su índice en la matriz del montículo y una marca booleana que indica si se ha eliminado. Cuando un Message está listo para ejecutarse, el hilo Looper CAS su marca eliminada y, a continuación, lo elimina del montículo y de la pila.
Cuando otro subproceso necesita eliminar un Message, no lo extrae inmediatamente de la estructura de datos. En lugar de eso, sigue estos pasos:
- Eliminación lógica: el subproceso usa una operación CAS para definir de forma atómica la marca de eliminación de
Messagede false a true. ElMessagepermanece en la estructura de datos como prueba de que se va a eliminar, lo que se conoce como "marca de tumba". Una vez que se marca unMessagepara su eliminación, DeliQueue lo trata como si ya no existiera en la cola cada vez que lo encuentra. - Limpieza aplazada: la eliminación real de la estructura de datos es responsabilidad del hilo
Loopery se aplaza hasta más adelante. En lugar de modificar la pila o el montículo, el hilo del eliminador añade elMessagea otra pila de lista libre sin bloqueo. - Eliminación estructural: solo el
Looperpuede interactuar con el montículo o eliminar elementos de la pila. Cuando se activa, borra la lista libre y procesa losMessages que contenía. CadaMessagese desvincula de la pila y se elimina del montículo.
De esta forma, toda la gestión del montículo se mantiene en un solo hilo. De esta forma, se reduce el número de operaciones simultáneas y de barreras de memoria necesarias, lo que hace que la ruta crítica sea más rápida y sencilla.
Recorrido: carreras de datos benignas del modelo de memoria de Java
La mayoría de las APIs de simultaneidad, como Future en la biblioteca estándar de Java o Job y Deferred de Kotlin, incluyen un mecanismo para cancelar el trabajo antes de que finalice. Una instancia de una de estas clases se corresponde de forma individual con una unidad de trabajo subyacente. Al llamar a cancel en un objeto, se cancelan las operaciones específicas asociadas a él.
Los dispositivos Android actuales tienen CPUs multinúcleo y recolección de elementos no utilizados simultánea y generacional. Sin embargo, cuando se desarrolló Android por primera vez, era demasiado caro asignar un objeto a cada unidad de trabajo. Por lo tanto, Handler de Android admite la cancelación mediante numerosas sobrecargas de removeMessages. En lugar de eliminar un Message específico, elimina todos los Message que coincidan con los criterios especificados. En la práctica, esto requiere iterar en todos los Message insertados antes de que se llamara a removeMessages y quitar los que coincidan.
Cuando se itera hacia delante, un hilo solo requiere una operación atómica ordenada para leer el encabezado actual de la pila. Después, se usan lecturas de campos normales para encontrar el siguiente Message. Si el hilo Looper modifica los campos next mientras elimina Messages, la escritura de Looper y la lectura de otro hilo no se sincronizan, lo que provoca una condición de carrera de datos. Normalmente, una condición de carrera de datos es un error grave que puede causar problemas importantes en tu aplicación, como fugas, bucles infinitos, fallos, bloqueos, etc. Sin embargo, en determinadas condiciones, las carreras de datos pueden ser benignas en el modelo de memoria de Java. Supongamos que empezamos con una pila de:

Realizamos una lectura atómica del encabezado y vemos A. El siguiente puntero de A apunta a B. Al mismo tiempo que procesamos B, el looper podría eliminar B y C actualizando A para que apunte a C y, después, a D.
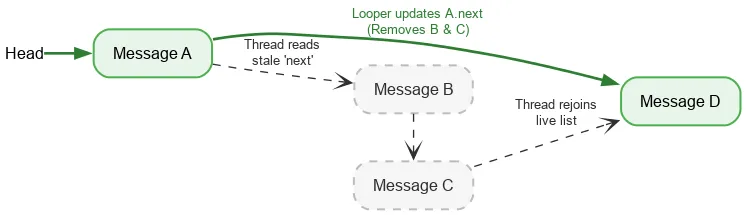
Aunque B y C se eliminen lógicamente, B conserva su puntero siguiente a C y C a D. El hilo de lectura sigue recorriendo los nodos eliminados y, finalmente, vuelve a unirse a la pila activa en D.
Al diseñar DeliQueue para gestionar las carreras entre el recorrido y la eliminación, permitimos una iteración segura y sin bloqueos.
Cerrando: recuento de referencias nativo
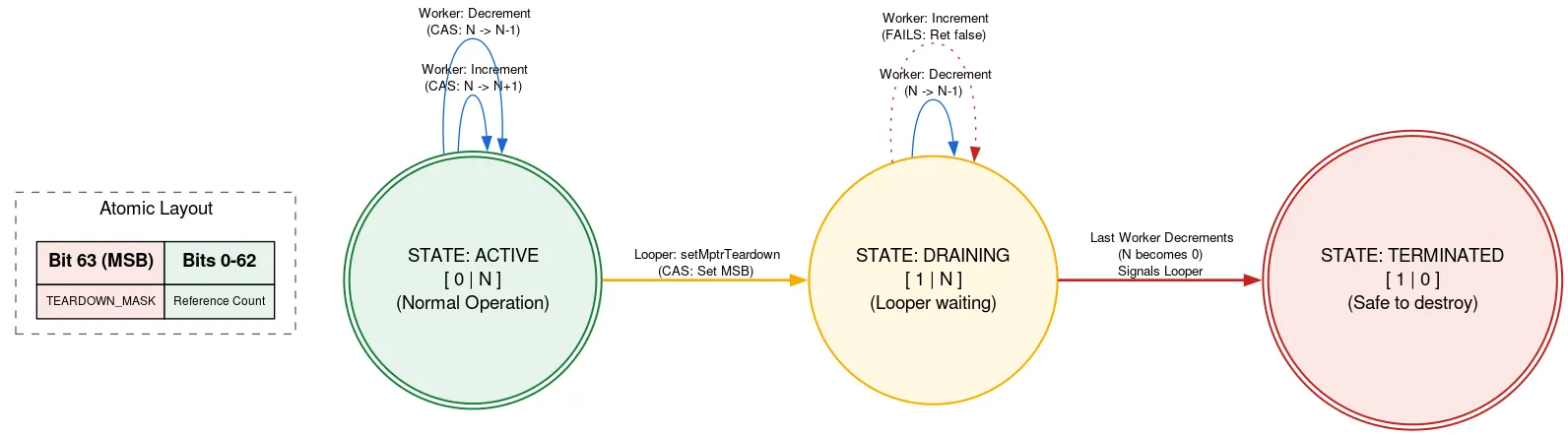
Looper se basa en una asignación nativa que debe liberarse manualmente una vez que se haya cerrado Looper. Si otro subproceso añade Messages mientras Looper se cierra, podría usar la asignación nativa después de que se haya liberado, lo que supone una infracción de la seguridad de la memoria. Para evitarlo, usamos un refcount etiquetado, donde se usa un bit del atómico para indicar si Looper está finalizando.
Antes de usar la asignación nativa, un subproceso lee el contador de referencias atómico. Si se define el bit de cierre, devuelve que Looper se está cerrando y que no se debe usar la asignación nativa. Si no es así, intenta realizar una operación CAS para incrementar el número de subprocesos activos mediante la asignación nativa. Después de hacer lo que necesita, disminuye el recuento. Si el bit de salida se ha definido después de su incremento, pero antes de su decremento, y el recuento es ahora cero, se activa el hilo Looper.
Cuando el hilo Looper está listo para salir, usa CAS para definir el bit de salida en el atómico. Si refcount era 0, puede liberar su asignación nativa. De lo contrario, se estaciona, sabiendo que se activará cuando el último usuario de la asignación nativa disminuya el recuento de referencias. Con este enfoque, el hilo Looper espera a que avancen los demás hilos, pero solo cuando se cierra. Esto solo ocurre una vez y no influye en el rendimiento, y mantiene el otro código para usar la asignación nativa sin bloqueos.
La implementación incluye muchos otros trucos y complejidades. Puedes consultar más información sobre DeliQueue en el código fuente.
Optimización: programación sin ramificaciones
Durante el desarrollo y las pruebas de DeliQueue, el equipo realizó muchas pruebas de rendimiento y analizó cuidadosamente el nuevo código. Uno de los problemas identificados con la herramienta simpleperf fueron los vaciados de la canalización provocados por el código del comparador Message.
Un comparador estándar usa saltos condicionales, y la condición para decidir qué Message va primero se simplifica de la siguiente manera:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) { if (m1 == m2) { return 0; } // Primary queue order is by when. // Messages with an earlier when should come first in the queue. final long whenDiff = m1.when - m2.when; if (whenDiff > 0) return 1; if (whenDiff < 0) return -1; // Secondary queue order is by insert sequence. // If two messages were inserted with the same `when`, the one inserted // first should come first in the queue. final long insertSeqDiff = m1.insertSeq - m2.insertSeq; if (insertSeqDiff > 0) return 1; if (insertSeqDiff < 0) return -1; return 0; }
Este código se compila en saltos condicionales (instrucciones b.le y cbnz). Cuando la CPU se encuentra con una bifurcación condicional, no puede saber si se toma la bifurcación hasta que se calcula la condición, por lo que no sabe qué instrucción leer a continuación y tiene que adivinarlo mediante una técnica llamada predicción de bifurcaciones. En un caso como la búsqueda binaria, la dirección de la rama será impredeciblemente diferente en cada paso, por lo que es probable que la mitad de las predicciones sean incorrectas. La predicción de ramificación suele ser ineficaz en los algoritmos de búsqueda y ordenación (como el que se usa en un montículo mínimo), ya que el coste de equivocarse es mayor que la mejora que se obtiene al acertar. Cuando el predictor de ramificaciones se equivoca, debe descartar el trabajo que ha hecho después de asumir el valor predicho y volver a empezar desde la ruta que se ha tomado realmente. Esto se denomina vaciado de la canalización.
Para encontrar este problema, hemos perfilado nuestras comparativas con el contador de rendimiento branch-misses, que registra los seguimientos de pila en los que el predictor de ramificaciones se equivoca. Después, visualizamos los resultados con Google pprof, como se muestra a continuación:
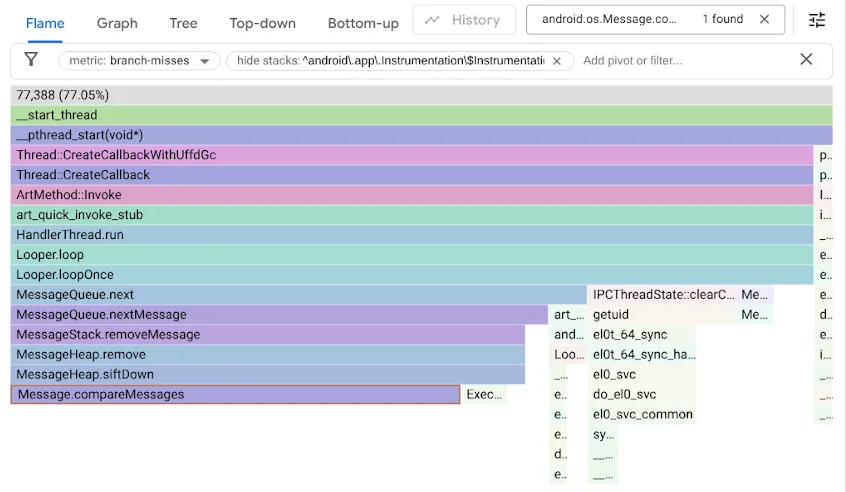
Recuerda que el código MessageQueue original usaba una lista enlazada simple para la cola ordenada. La inserción recorrería la lista en orden de clasificación como una búsqueda lineal, deteniéndose en el primer elemento que esté después del punto de inserción y vinculando el nuevo Message antes de él. Para quitarla de la cabeza, solo había que desvincularla. Mientras que DeliQueue usa un montículo mínimo, donde las mutaciones requieren reordenar algunos elementos (filtrar hacia arriba o hacia abajo) con una complejidad logarítmica en una estructura de datos equilibrada, donde cualquier comparación tiene la misma probabilidad de dirigir el recorrido a un elemento secundario izquierdo o a un elemento secundario derecho. El nuevo algoritmo es asintóticamente más rápido, pero expone un nuevo cuello de botella, ya que el código de búsqueda se detiene en las fallas de ramificación la mitad del tiempo.
Nos dimos cuenta de que los errores de ramificación ralentizaban nuestro código de montículo, así que lo optimizamos con la programación sin ramificaciones:
// Branchless Logic static int compareMessages(@NonNull Message m1, @NonNull Message m2) { final long when1 = m1.when; final long when2 = m2.when; final long insertSeq1 = m1.insertSeq; final long insertSeq2 = m2.insertSeq; // signum returns the sign (-1, 0, 1) of the argument, // and is implemented as pure arithmetic: // ((num >> 63) | (-num >>> 63)) final int whenSign = Long.signum(when1 - when2); final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2); // whenSign takes precedence over insertSeqSign, // so the formula below is such that insertSeqSign only matters // as a tie-breaker if whenSign is 0. return whenSign * 2 + insertSeqSign; }
Para entender la optimización, desmonta los dos ejemplos en Compiler Explorer y usa LLVM-MCA, un simulador de CPU que puede generar una cronología estimada de los ciclos de CPU.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Fíjate en la rama condicional b.le, que evita comparar los campos insertSeq si ya se conoce el resultado al comparar los campos when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
En este caso, la implementación sin ramificaciones requiere menos ciclos e instrucciones que incluso la ruta más corta del código con ramificaciones, por lo que es mejor en todos los casos. La implementación más rápida y la eliminación de las ramificaciones predichas incorrectamente han dado como resultado una mejora de 5 veces en algunas de nuestras comparativas.
Sin embargo, esta técnica no siempre se puede aplicar. Los enfoques sin ramificaciones suelen requerir que se haga un trabajo que se va a descartar y, si la ramificación es predecible la mayor parte del tiempo, ese trabajo desperdiciado puede ralentizar el código. Además, al eliminar una rama, a menudo se introduce una dependencia de datos. Las CPUs modernas ejecutan varias operaciones por ciclo, pero no pueden ejecutar una instrucción hasta que estén listos los datos de entrada de una instrucción anterior. Por el contrario, una CPU puede especular sobre los datos de las ramas y seguir trabajando si se predice correctamente una rama.
Pruebas y validación
Validar la corrección de los algoritmos sin bloqueo es muy difícil.
Además de las pruebas unitarias estándar para la validación continua durante el desarrollo, también hemos escrito pruebas de carga rigurosas para verificar las invariantes de las colas e intentar inducir condiciones de carrera de datos si existieran. En nuestros laboratorios de pruebas, pudimos ejecutar millones de instancias de prueba en dispositivos emulados y en hardware real.
Con la instrumentación Java ThreadSanitizer (JTSan), podríamos usar las mismas pruebas para detectar algunas condiciones de carrera de datos en nuestro código. JTSan no ha encontrado ninguna condición de carrera problemática en DeliQueue, pero, sorprendentemente, ha detectado dos errores de simultaneidad en el framework Robolectric, que hemos corregido rápidamente.
Para mejorar nuestras funciones de depuración, hemos creado nuevas herramientas de análisis. A continuación, se muestra un ejemplo de un problema en el código de la plataforma Android en el que un hilo sobrecarga a otro con Messages, lo que provoca una gran acumulación, que se puede ver en Perfetto gracias a la función de instrumentación MessageQueue que hemos añadido.
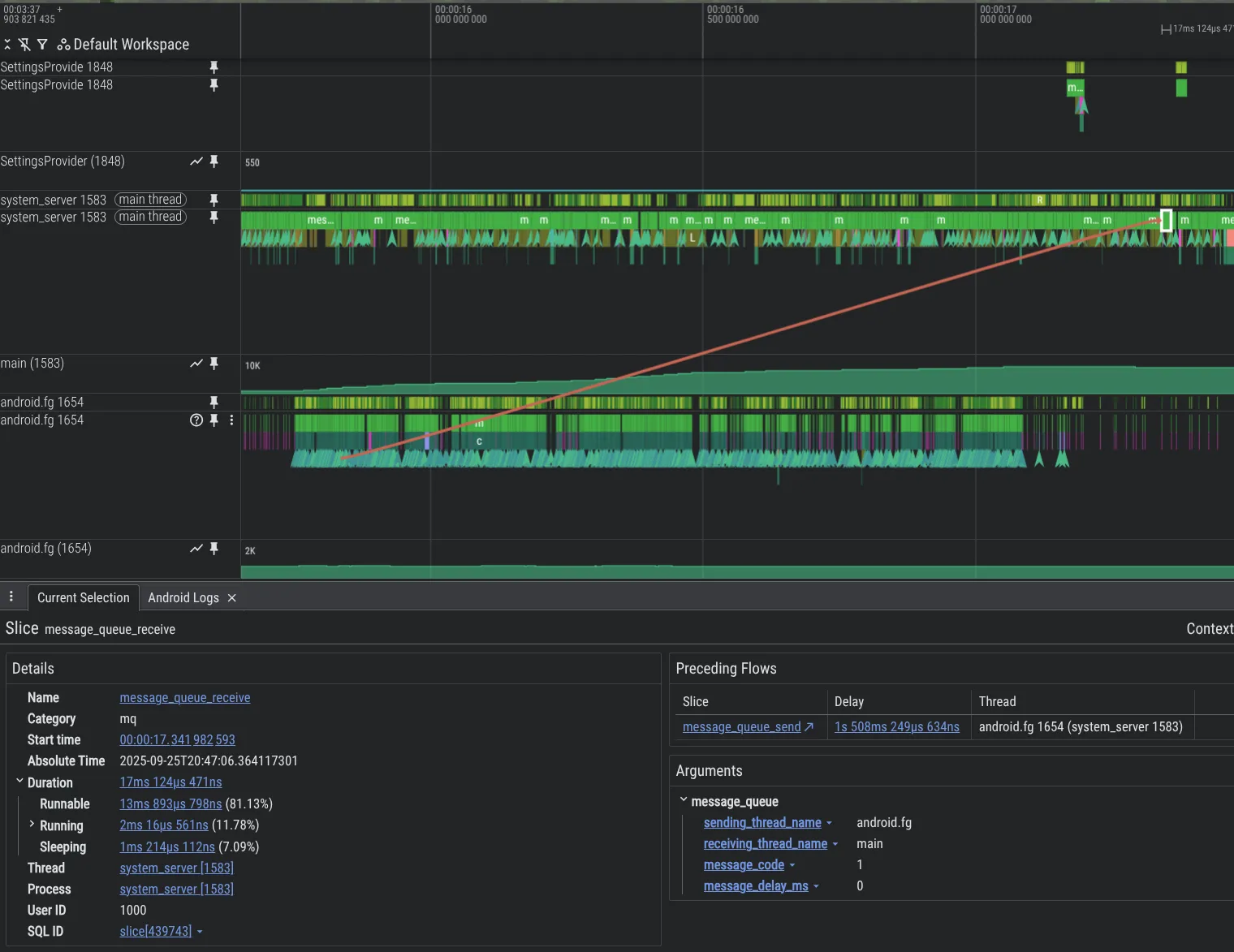
Para habilitar el seguimiento MessageQueue en el proceso system_server, incluye lo siguiente en tu configuración de Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Impacto
DeliQueue mejora el rendimiento del sistema y de las aplicaciones eliminando los bloqueos de MessageQueue.
- Pruebas de rendimiento sintéticas: las inserciones multihilo en colas ocupadas son hasta 5000 veces más rápidas que con
MessageQueue, gracias a la mejora de la simultaneidad (la pila de Treiber) y a las inserciones más rápidas (el montículo mínimo). - En las trazas de Perfetto obtenidas de testers beta internos, vemos una reducción del 15% en el tiempo del hilo principal de la aplicación dedicado a la contención de bloqueos.
- En los mismos dispositivos de prueba, la reducción de la contención de bloqueos conlleva mejoras significativas en la experiencia de usuario, como las siguientes:
- -4% de fotogramas perdidos en aplicaciones.
- -7,7% de fotogramas perdidos en las interacciones de la interfaz de usuario del sistema y del menú de aplicaciones.
- -9,1 % en el tiempo transcurrido desde el inicio de la aplicación hasta que se dibuja el primer fotograma, en el percentil 95.
Pasos siguientes
DeliQueue se está lanzando en aplicaciones de Android 17. Los desarrolladores de aplicaciones deben consultar el artículo sobre cómo preparar una aplicación para el nuevo MessageQueue sin bloqueo en el blog para desarrolladores de Android para saber cómo probar sus aplicaciones.
Referencias
[1] Treiber, R.K., 1986. Programación de sistemas: cómo gestionar el paralelismo. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., y Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Escrito por:
Seguir leyendo
-


Noticias sobre productos
Nos complace anunciar importantes actualizaciones de nuestros recursos de diseño, que te ofrecen la guía completa que necesitas para crear aplicaciones Android adaptables y de alta calidad en todos los factores de forma. Ahora tenemos una guía sobre la experiencia de escritorio y una galería de diseño de Android renovada.
Ivy Knight • Tiempo de lectura: 2 min
-


Noticias sobre productos
Se ha lanzado la primera versión alfa de Room 3.0. Room 3.0 es una versión principal de la biblioteca que introduce cambios importantes y se centra en Kotlin Multiplatform (KMP). Además, añade compatibilidad con JavaScript y WebAssembly (WASM) a la compatibilidad con Android, iOS y JVM para ordenadores.
Daniel Santiago Rivera • Tiempo de lectura: 4 min
-


Noticias sobre productos
Hoy nos complace compartir cómo estamos incorporando la optimización automática dirigida por comentarios (AutoFDO) al kernel de Android para ofrecer a los usuarios mejoras significativas en el rendimiento.
Yabin Cui • Tiempo de lectura: 4 min
Mantente al día
Recibe cada semana en tu bandeja de entrada las últimas novedades sobre el desarrollo para Android.
