
बारीकियों के बारे में जानें: Android 17 में लॉक-फ़्री MessageQueue
पढ़ने में 16 मिनट लगेंगे

Android 17 में, SDK 37 या इसके बाद के वर्शन को टारगेट करने वाले ऐप्लिकेशन को MessageQueue का नया वर्शन मिलेगा. इसमें लॉक-फ़्री सुविधा उपलब्ध होगी. नया वर्शन लागू करने से परफ़ॉर्मेंस बेहतर होती है और छूटे हुए फ़्रेम की संख्या कम होती है. हालांकि, इससे उन क्लाइंट को नुकसान पहुंच सकता है जो MessageQueue के निजी फ़ील्ड और तरीकों को दिखाते हैं. बदलाव के बारे में ज़्यादा जानने और इसके असर को कम करने के तरीके के बारे में जानने के लिए, MessageQueue के व्यवहार में हुए बदलाव से जुड़ा दस्तावेज़ देखें. इस तकनीकी ब्लॉग पोस्ट में, MessageQueue के रीआर्किटेक्चर के बारे में खास जानकारी दी गई है. साथ ही, इसमें यह भी बताया गया है कि Perfetto का इस्तेमाल करके, लॉक कंटेंशन की समस्याओं का विश्लेषण कैसे किया जा सकता है.
Looper, हर Android ऐप्लिकेशन के यूज़र इंटरफ़ेस (यूआई) थ्रेड को कंट्रोल करता है. यह MessageQueue से काम लेता है, उसे Handler को भेजता है, और इस प्रोसेस को दोहराता है. दो दशकों तक, MessageQueue ने अपनी स्थिति को सुरक्षित रखने के लिए, एक ही मॉनिटर लॉक (यानी कि synchronized कोड ब्लॉक) का इस्तेमाल किया.
Android 17 में, इस कॉम्पोनेंट के लिए एक अहम अपडेट पेश किया गया है: लॉक-फ़्री तरीके से लागू किया गया DeliQueue.
इस पोस्ट में बताया गया है कि लॉक, यूज़र इंटरफ़ेस (यूआई) की परफ़ॉर्मेंस पर कैसे असर डालते हैं. साथ ही, Perfetto की मदद से इन समस्याओं का विश्लेषण कैसे किया जाता है. इसमें Android के मुख्य थ्रेड को बेहतर बनाने के लिए इस्तेमाल किए गए खास एल्गोरिदम और ऑप्टिमाइज़ेशन के बारे में भी बताया गया है.
समस्या: लॉक कंटेंशन और प्रायॉरिटी इनवर्ज़न
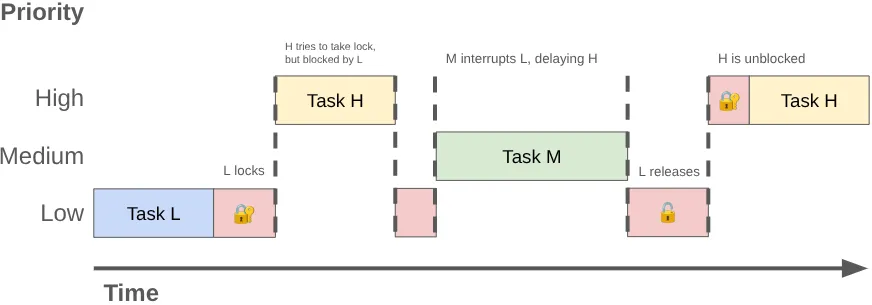
लेगसी MessageQueue, एक लॉक से सुरक्षित की गई प्राथमिकता वाली सूची के तौर पर काम करता था. अगर मुख्य थ्रेड, कतार को मैनेज कर रही है और उसी दौरान कोई बैकग्राउंड थ्रेड मैसेज पोस्ट करती है, तो बैकग्राउंड थ्रेड, मुख्य थ्रेड को ब्लॉक कर देती है.
जब दो या दो से ज़्यादा थ्रेड, एक ही लॉक का इस्तेमाल करने के लिए आपस में प्रतिस्पर्धा करती हैं, तो इसे लॉक कंटेंशन कहा जाता है. इस वजह से, प्राथमिकता पलटने की समस्या हो सकती है. इससे यूज़र इंटरफ़ेस (यूआई) में रुकावट आ सकती है और परफ़ॉर्मेंस से जुड़ी अन्य समस्याएं हो सकती हैं.
प्रायॉरिटी इन्वर्ज़न की समस्या तब हो सकती है, जब ज़्यादा प्राथमिकता वाली थ्रेड (जैसे कि यूज़र इंटरफ़ेस थ्रेड) को कम प्राथमिकता वाली थ्रेड के लिए इंतज़ार करना पड़े. इस क्रम पर विचार करें:
- कम प्राथमिकता वाली बैकग्राउंड थ्रेड, किए गए काम का नतीजा पोस्ट करने के लिए
MessageQueueलॉक हासिल करती है. - मीडियम प्राथमिकता वाला थ्रेड, चलाने लायक बन जाता है. साथ ही, कर्नल का शेड्यूलर इसे सीपीयू का समय देता है. इससे कम प्राथमिकता वाले थ्रेड को रोका जाता है.
- ज़्यादा प्राथमिकता वाली यूज़र इंटरफ़ेस (यूआई) थ्रेड, मौजूदा टास्क पूरा करती है और कतार से डेटा पढ़ने की कोशिश करती है. हालांकि, इसे ब्लॉक कर दिया जाता है, क्योंकि कम प्राथमिकता वाली थ्रेड लॉक को होल्ड करती है.
कम प्राथमिकता वाली थ्रेड, यूज़र इंटरफ़ेस (यूआई) थ्रेड को ब्लॉक करती है. साथ ही, सामान्य प्राथमिकता वाला काम इसे और देर तक ब्लॉक करता है.
Perfetto की मदद से, परफ़ॉर्मेंस से जुड़ी समस्याओं का विश्लेषण करना
इन समस्याओं का पता लगाने के लिए, Perfetto का इस्तेमाल किया जा सकता है. स्टैंडर्ड ट्रेस में, मॉनिटर लॉक पर ब्लॉक की गई थ्रेड स्लीपिंग स्टेट में चली जाती है. साथ ही, Perfetto एक स्लाइस दिखाता है, जो लॉक के मालिक के बारे में बताता है.
ट्रेस डेटा के लिए क्वेरी करते समय, “monitor contention with …” नाम वाले स्लाइस ढूंढें. इसके बाद, उस थ्रेड का नाम ढूंढें जिसके पास लॉक है और उस कोड साइट का नाम ढूंढें जहां लॉक हासिल किया गया था.
केस स्टडी: लॉन्चर में जंक
उदाहरण के लिए, हम एक ऐसे ट्रेस का विश्लेषण करते हैं जिसमें किसी उपयोगकर्ता को Pixel फ़ोन पर, कैमरा ऐप्लिकेशन में फ़ोटो लेने के तुरंत बाद होम पेज पर नेविगेट करते समय जंक का सामना करना पड़ा. यहां Perfetto का एक स्क्रीनशॉट दिया गया है. इसमें छूटे हुए फ़्रेम से पहले के इवेंट दिखाए गए हैं:
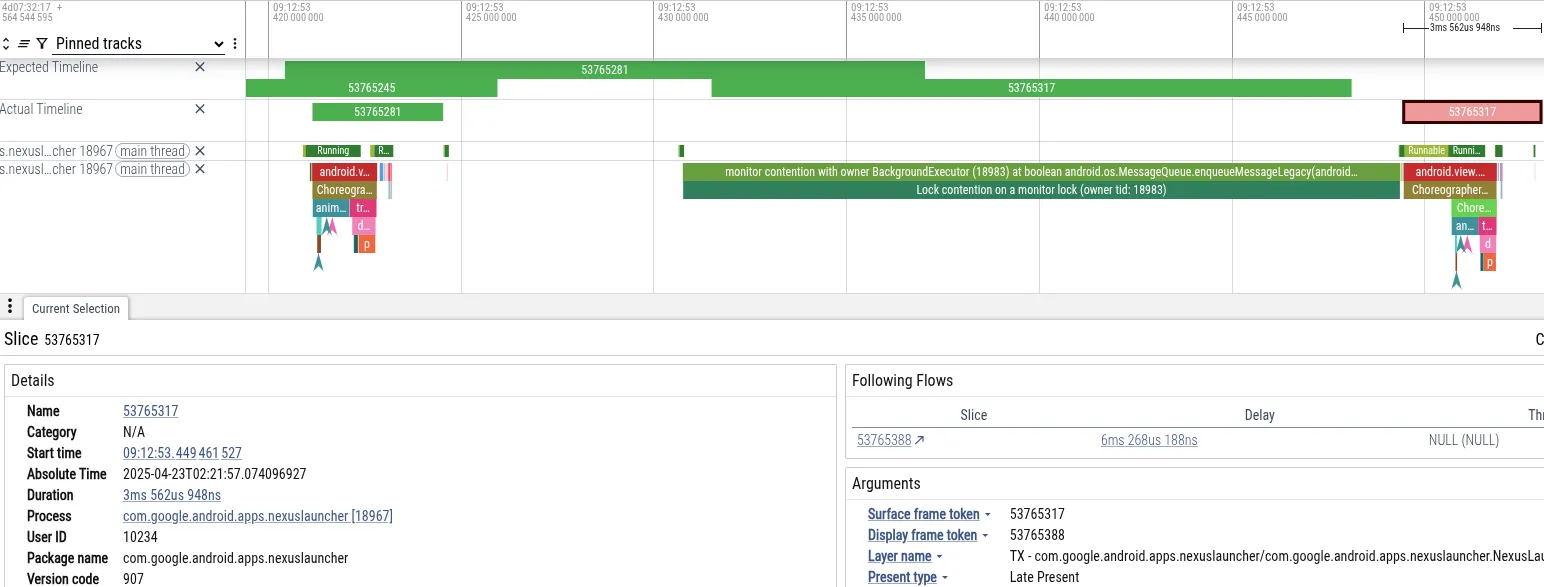
- समस्या: लॉन्चर की मुख्य थ्रेड, फ़्रेम के लिए तय की गई समयसीमा को पूरा नहीं कर पाई. इसे 18 मि॰से॰ के लिए ब्लॉक किया गया था. यह 60 हर्ट्ज़ रेंडरिंग के लिए ज़रूरी 16 मि॰से॰ की समयसीमा से ज़्यादा है.
- निदान: Perfetto ने दिखाया कि मुख्य थ्रेड,
MessageQueueलॉक पर ब्लॉक है. “BackgroundExecutor” थ्रेड के पास लॉक का मालिकाना हक था. - समस्या की वजह: BackgroundExecutor, Process.THREAD_PRIORITY_BACKGROUND (बहुत कम प्राथमिकता) पर चलता है. इसने कोई ज़रूरी काम नहीं किया (जैसे, ऐप्लिकेशन इस्तेमाल करने की सीमाएं देखना). साथ ही, सामान्य प्राथमिकता वाली थ्रेड, कैमरे से मिले डेटा को प्रोसेस करने के लिए सीपीयू का इस्तेमाल कर रही थीं. ओएस शेड्यूलर ने BackgroundExecutor थ्रेड को रोककर, कैमरा थ्रेड को चालू कर दिया.
इस क्रम की वजह से, लॉन्चर की यूज़र इंटरफ़ेस (यूआई) थ्रेड (ज़्यादा प्राथमिकता) को कैमरा वर्कर थ्रेड (सामान्य प्राथमिकता) ने परोक्ष रूप से ब्लॉक कर दिया था. इससे लॉन्चर की बैकग्राउंड थ्रेड (कम प्राथमिकता) लॉक को रिलीज़ नहीं कर पा रही थी.
PerfettoSQL की मदद से ट्रेस के बारे में क्वेरी करना
किसी खास पैटर्न के लिए, ट्रेस डेटा को क्वेरी करने के लिए, PerfettoSQL का इस्तेमाल किया जा सकता है. यह तब काम आता है, जब आपके पास उपयोगकर्ता के डिवाइसों या टेस्ट से मिले ट्रेस का बड़ा डेटा बैंक हो और आपको ऐसी खास ट्रेसिंग ढूंढनी हो जिनसे किसी समस्या का पता चलता हो.
उदाहरण के लिए, इस क्वेरी से MessageQueue कॉन्टेंशन का पता चलता है, जो फ़्रेम के ड्रॉप होने (जैंक) के साथ होता है:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
इस ज़्यादा मुश्किल उदाहरण में, ऐप्लिकेशन के शुरू होने के दौरान MessageQueue के लिए होने वाले टकराव की पहचान करने के लिए, एक से ज़्यादा टेबल में मौजूद ट्रेस डेटा को जोड़ें:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
अन्य पैटर्न खोजने के लिए, अपने पसंदीदा एलएलएम का इस्तेमाल करके PerfettoSQL क्वेरी लिखी जा सकती हैं.
Google में, हम लाखों ट्रेस में PerfettoSQL क्वेरी चलाने के लिए, BigTrace का इस्तेमाल करते हैं. इससे हमें यह पुष्टि करने में मदद मिली कि हमें जो समस्या दिख रही थी वह वाकई एक सिस्टमैटिक समस्या है. डेटा से पता चला कि MessageQueue लॉक कंटेंशन का असर पूरे इकोसिस्टम के उपयोगकर्ताओं पर पड़ता है. इससे आर्किटेक्चर में बुनियादी बदलाव करने की ज़रूरत का पता चलता है.
समाधान: लॉक-फ़्री कंकरेंसी
हमने MessageQueue कंटेंशन की समस्या को हल करने के लिए, लॉक-फ़्री डेटा स्ट्रक्चर लागू किया है. साथ ही, शेयर की गई स्थिति को सिंक करने के लिए, एक्सक्लूसिव लॉक के बजाय एटॉमिक मेमोरी ऑपरेशन का इस्तेमाल किया है. किसी डेटा स्ट्रक्चर या एल्गोरिदम को लॉक-फ़्री तब कहा जाता है, जब कम से कम एक थ्रेड हमेशा आगे बढ़ सकती है. भले ही, अन्य थ्रेड के शेड्यूल करने का तरीका कुछ भी हो. आम तौर पर, इस प्रॉपर्टी को हासिल करना मुश्किल होता है. साथ ही, ज़्यादातर कोड के लिए, इसे हासिल करने की कोशिश करना फ़ायदेमंद नहीं होता.
एटॉमिक प्रिमिटिव
लॉक-फ़्री सॉफ़्टवेयर अक्सर एटॉमिक रीड-मॉडिफ़ाई-राइट प्रिमिटिव पर निर्भर करता है, जो हार्डवेयर उपलब्ध कराता है.
पुरानी जनरेशन के ARM64 सीपीयू पर, ऐटॉमिक ऑपरेशन के लिए Load-Link/Store-Conditional (LL/SC) लूप का इस्तेमाल किया जाता था. सीपीयू, वैल्यू लोड करता है और पते को मार्क करता है. अगर कोई अन्य थ्रेड उस पते पर लिखता है, तो स्टोर काम नहीं करता है और लूप फिर से कोशिश करता है. थ्रेड, किसी दूसरी थ्रेड का इंतज़ार किए बिना कोशिश करती रहती हैं और सफल हो सकती हैं. इसलिए, यह ऑपरेशन लॉक-फ़्री होता है.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrनए एआरएम आर्किटेक्चर (ARMv8.1) में, लार्ज सिस्टम एक्सटेंशन (एलएसई) की सुविधा काम करती है. इसमें तुलना और स्वैप (सीएएस) या लोड और जोड़ें (नीचे दिखाया गया है) के तौर पर निर्देश शामिल होते हैं. Android 17 में, हमने Android Runtime (ART) कंपाइलर के लिए सहायता जोड़ी है. इससे यह पता लगाया जा सकता है कि LSE की सुविधा कब काम करती है और ऑप्टिमाइज़ किए गए निर्देश कब जारी किए जाते हैं:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.हमारे बेंचमार्क में, CAS का इस्तेमाल करने वाला हाई-कंटेंशन कोड, LL/SC वैरिएंट की तुलना में ~3 गुना ज़्यादा तेज़ी से काम करता है.
Java प्रोग्रामिंग लैंग्वेज, java.util.concurrent.atomic के ज़रिए ऐटॉमिक प्रिमिटिव उपलब्ध कराती है. ये प्रिमिटिव, इन और अन्य खास सीपीयू निर्देशों पर निर्भर करती हैं.
डेटा स्ट्रक्चर: DeliQueue
MessageQueue से लॉक कंटेंशन हटाने के लिए, हमारे इंजीनियरों ने एक नया डेटा स्ट्रक्चर डिज़ाइन किया है. इसे DeliQueue कहा जाता है. DeliQueue, Message इंसर्शन को Message प्रोसेसिंग से अलग करता है:
Messages(Treiber stack): यह लॉक-फ़्री स्टैक है. कोई भी थ्रेड, बिना किसी रुकावट के यहां नयाMessagesपुश कर सकती है.- प्रायोरिटी क्यू (मिन-हीप): यह
Messagesका एक हीप होता है, जिसे सिर्फ़ Looper थ्रेड मैनेज करता है. इसलिए, इसे ऐक्सेस करने के लिए किसी सिंक्रनाइज़ेशन या लॉक की ज़रूरत नहीं होती.
Enqueue: pushing to a Treiber stack
Messages की सूची को Treiber स्टैक [1] में रखा जाता है. यह एक लॉक-फ़्री स्टैक है, जो हेड पॉइंटर को अपडेट करने के लिए CAS लूप का इस्तेमाल करता है.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Java Concurrency in Practice [2] पर आधारित सोर्स कोड, ऑनलाइन उपलब्ध है और सार्वजनिक डोमेन में रिलीज़ किया गया है
कोई भी प्रोड्यूसर, किसी भी समय स्टैक में नए Message जोड़ सकता है. यह किसी खाने की चीज़ों की दुकान पर टिकट लेने जैसा है. आपका नंबर इस बात पर निर्भर करता है कि आप कब पहुंचे, लेकिन आपको खाना किस क्रम में मिलेगा, यह ज़रूरी नहीं कि आपके नंबर के हिसाब से हो. यह एक लिंक किया गया स्टैक है. इसलिए, हर Message एक सब-स्टैक है. हेड को ट्रैक करके और आगे की ओर दोहराकर, यह देखा जा सकता है कि किसी भी समय Message की कतार कैसी थी. आपको सबसे ऊपर कोई नया Message नहीं दिखेगा, भले ही उन्हें आपके ट्रैवर्सल के दौरान जोड़ा जा रहा हो.
Dequeue: bulk transfer to a min-heap
अगले Message को हैंडल करने के लिए, Looper, Treiber स्टैक से नए Message प्रोसेस करता है. इसके लिए, वह स्टैक को ऊपर से शुरू करके तब तक दोहराता है, जब तक उसे वह आखिरी Message नहीं मिल जाता जिसे उसने पहले प्रोसेस किया था. जैसे-जैसे Looper स्टैक में नीचे की ओर बढ़ता है, वैसे-वैसे यह समयसीमा के हिसाब से क्रम में लगे छोटे से ढेर में Messages डालता जाता है. Looper के पास हीप का मालिकाना हक होता है. इसलिए, यह लॉक या एटॉमिक के बिना Message को ऑर्डर और प्रोसेस करता है.

स्टैक में नीचे की ओर जाते समय, Looper स्टैक किए गए Message से उनके पूर्ववर्तियों के लिंक भी बनाता है. इस तरह, दो बार लिंक की गई सूची बन जाती है. लिंक की गई सूची बनाना सुरक्षित है. ऐसा इसलिए, क्योंकि स्टैक में नीचे की ओर मौजूद लिंक, CAS के साथ Treiber स्टैक एल्गोरिदम के ज़रिए जोड़े जाते हैं. साथ ही, स्टैक में ऊपर की ओर मौजूद लिंक को सिर्फ़ Looper थ्रेड पढ़ता है और उसमें बदलाव करता है. इसके बाद, इन बैक लिंक का इस्तेमाल करके, स्टैक में किसी भी पॉइंट से Message को O(1) समय में हटाया जाता है.
इस डिज़ाइन में, प्रोड्यूसर(थ्रेड पोस्ट करने का काम, कतार में) के लिए O (1) इंसर्शन और उपभोक्ता(Looper) के लिए O (log N) प्रोसेसिंग की सुविधा मिलती है.
Message को क्रम में लगाने के लिए, मिन-हीप का इस्तेमाल करने से, लेगसी MessageQueue की एक बुनियादी समस्या भी हल हो जाती है. इसमें Message को एक ही लिंक वाली सूची में रखा जाता था (सबसे ऊपर रूट किया गया). लेगसी वर्शन में, हेड से हटाने की प्रोसेस O(1) थी. हालांकि, जोड़ने की प्रोसेस में सबसे खराब स्थिति O(N) थी. इससे, ज़्यादा लोड वाली कतारों के लिए स्केलिंग ठीक से नहीं हो पाती थी! इसके उलट, मिन-हीप में डेटा डालने और निकालने की प्रोसेस, लॉगरिथम के हिसाब से होती है. इससे औसत परफ़ॉर्मेंस अच्छी मिलती है. हालांकि, यह टेल लेटेंसी के मामले में सबसे बेहतर होती है.
लेगसी (लॉक किया गया) MessageQueue | DeliQueue | |
| शामिल करें | O(N) | O(1) for calling thread
|
| हेड से हटाएं | O(1) | O(logN) |
लेगसी क्यू के लागू होने पर, प्रोड्यूसर और उपभोक्ता ने लॉक का इस्तेमाल किया. इससे, सिंगल-लिंक की गई सूची को एक्सक्लूसिव ऐक्सेस करने में मदद मिली. DeliQueue में, Treiber स्टैक एक साथ कई अनुरोधों को हैंडल करता है. साथ ही, सिंगल कंज्यूमर, वर्क क्यू को क्रम से लगाता है.
हटाना: टॉमस्टोन के ज़रिए एक जैसा अनुभव
DeliQueue एक हाइब्रिड डेटा स्ट्रक्चर है. यह लॉक-फ़्री Treiber स्टैक को सिंगल-थ्रेड वाले min-heap से जोड़ता है. ग्लोबल लॉक के बिना इन दोनों स्ट्रक्चर को सिंक में रखना एक मुश्किल काम है: ऐसा हो सकता है कि कोई मैसेज स्टैक में मौजूद हो, लेकिन लॉजिक के हिसाब से उसे कतार से हटा दिया गया हो.
इस समस्या को हल करने के लिए, DeliQueue “टॉम्बस्टोनिंग” नाम की तकनीक का इस्तेमाल करता है. हर Message, स्टैक में अपनी पोज़िशन को ट्रैक करता है. इसके लिए, वह पीछे और आगे के पॉइंटर, हीप के ऐरे में मौजूद इंडेक्स, और एक बूलियन फ़्लैग का इस्तेमाल करता है. यह फ़्लैग बताता है कि Message को हटाया गया है या नहीं. जब कोई Message चलने के लिए तैयार होता है, तब Looper थ्रेड, हटाए गए फ़्लैग को CAS करता है. इसके बाद, उसे हीप और स्टैक से हटा देता है.
जब किसी अन्य थ्रेड को Message को हटाना होता है, तो वह उसे डेटा स्ट्रक्चर से तुरंत नहीं निकालता. इसके बजाय, यह तरीका अपनाएं:
- लॉजिकल रिमूवल: थ्रेड, CAS का इस्तेमाल करके
Messageके रिमूवल फ़्लैग को फ़ॉल्स से ट्रू पर सेट करता है.Messageडेटा स्ट्रक्चर में मौजूद रहता है. इससे यह पता चलता है कि इसे हटाया जाना है. इसे “टूंबस्टोन” कहा जाता है. जब किसीMessageको हटाने के लिए फ़्लैग किया जाता है, तो DeliQueue इसे इस तरह से मैनेज करता है कि यह अब क्यू में मौजूद नहीं है. - डेटा स्ट्रक्चर से डेटा हटाने की ज़िम्मेदारी
Looperथ्रेड की होती है. इसे बाद तक के लिए टाला जा सकता है. रिमूवर थ्रेड, स्टैक या हीप में बदलाव करने के बजाय,Messageको लॉक-फ़्री फ़्रीलिस्ट स्टैक में जोड़ता है. - स्ट्रक्चरल रिमूवल: सिर्फ़
Looperही हीप के साथ इंटरैक्ट कर सकता है या स्टैक से एलिमेंट हटा सकता है. जब यह चालू होता है, तो यह फ़्रीलिस्ट को मिटा देता है और इसमें मौजूदMessageको प्रोसेस करता है. इसके बाद, हरMessageको स्टैक से अनलिंक कर दिया जाता है और हीप से हटा दिया जाता है.
इस तरीके से, हीप को मैनेज करने का काम एक ही थ्रेड में होता है. इससे एक साथ होने वाली कार्रवाइयों और मेमोरी बैरियर की संख्या कम हो जाती है. इससे, अहम पाथ को तेज़ी से और आसानी से पूरा किया जा सकता है.
ट्रैवर्सल: Java मेमोरी मॉडल में डेटा रेस की समस्या
ज़्यादातर कॉंकुरेंसी एपीआई, जैसे कि Java स्टैंडर्ड लाइब्रेरी में Future या Kotlin के Job और Deferred, में काम पूरा होने से पहले उसे रद्द करने का तरीका शामिल होता है. इन क्लास का कोई इंस्टेंस, काम की किसी यूनिट से 1:1 मैच करता है. साथ ही, किसी ऑब्जेक्ट पर cancel को कॉल करने से, उनसे जुड़े खास ऑपरेशन रद्द हो जाते हैं.
आजकल के Android डिवाइसों में मल्टी-कोर सीपीयू और एक साथ कई जनरेशन के गारबेज कलेक्शन की सुविधा होती है. हालांकि, जब Android को पहली बार बनाया गया था, तब काम की हर यूनिट के लिए एक ऑब्जेक्ट असाइन करना बहुत महंगा था. इसलिए, Android का Handler, removeMessages के कई ओवरलोड के ज़रिए रद्द करने की सुविधा देता है. यह किसी खास Message को हटाने के बजाय, उन सभी Message को हटा देता है जो बताई गई शर्तों को पूरा करते हैं. असल में, इसके लिए removeMessages को कॉल करने से पहले, डाली गई सभी Message को दोहराना होता है. साथ ही, मैच होने वाली वैल्यू को हटाना होता है.
आगे की ओर दोहराते समय, किसी थ्रेड को स्टैक के मौजूदा हेड को पढ़ने के लिए, सिर्फ़ एक क्रमबद्ध एटॉमिक ऑपरेशन की ज़रूरत होती है. इसके बाद, अगले Message को ढूंढने के लिए, सामान्य फ़ील्ड रीड का इस्तेमाल किया जाता है. अगर Looper थ्रेड, Messages को हटाते समय next फ़ील्ड में बदलाव करता है, तो Looper का राइट और किसी अन्य थ्रेड का रीड, सिंक्रनाइज़ नहीं होता. इसे डेटा रेस कहते हैं. आम तौर पर, डेटा रेस एक गंभीर बग होता है. इससे आपके ऐप्लिकेशन में कई समस्याएं आ सकती हैं. जैसे, डेटा लीक होना, इनफ़िनिट लूप, क्रैश होना, फ़्रीज़ होना वगैरह. हालांकि, कुछ खास स्थितियों में Java मेमोरी मॉडल में डेटा रेस से कोई नुकसान नहीं होता. मान लें कि हमारे पास इन चीज़ों का एक स्टैक है:

हम हेड को ऐटॉमिक तरीके से पढ़ते हैं और हमें A दिखता है. A का अगला पॉइंटर, B की ओर इशारा करता है. B को प्रोसेस करते समय, लूपर B और C को हटा सकता है. इसके लिए, वह A को अपडेट करके C और फिर D पर पॉइंट करता है.
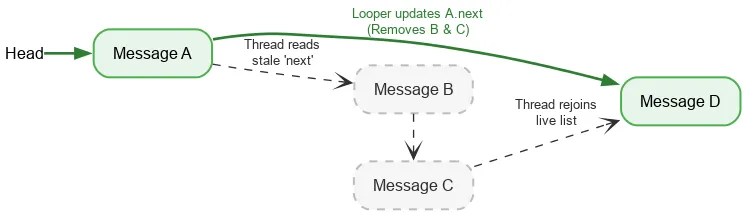
B और C को लॉजिक के हिसाब से हटा दिया गया है. हालांकि, B का अगला पॉइंटर C पर और C का अगला पॉइंटर D पर बना रहता है. रीडिंग थ्रेड, हटाए गए नोड से होकर गुज़रती है और आखिर में D पर लाइव स्टैक से जुड़ जाती है.
DeliQueue को इस तरह से डिज़ाइन किया गया है कि यह ट्रैवर्सल और रिमूवल के बीच रेस को हैंडल कर सके. इससे हम सुरक्षित और लॉक-फ़्री इटरेशन की अनुमति देते हैं.
Quitting: Native refcount
Looper को नेटिव ऐलोकेशन से बैक किया जाता है. Looper के बंद होने के बाद, इसे मैन्युअल तरीके से खाली करना होगा. अगर Looper बंद होने के दौरान कोई अन्य थ्रेड Message जोड़ रहा है, तो वह थ्रेड, Message के खाली होने के बाद नेटिव ऐलोकेशन का इस्तेमाल कर सकता है. यह मेमोरी की सुरक्षा से जुड़े नियम का उल्लंघन है. हम टैग किए गए रेफ़काउंट का इस्तेमाल करके, ऐसा होने से रोकते हैं. इसमें एटॉमिक के एक बिट का इस्तेमाल यह बताने के लिए किया जाता है कि Looper बंद हो रहा है या नहीं.
नेटिव ऐलोकेशन का इस्तेमाल करने से पहले, थ्रेड, रेफ़काउंट ऐटॉमिक को पढ़ता है. अगर क्विटिंग बिट सेट है, तो यह दिखाता है कि Looper बंद हो रहा है और नेटिव ऐलोकेशन का इस्तेमाल नहीं किया जाना चाहिए. अगर ऐसा नहीं होता है, तो यह नेटिव ऐलोकेशन का इस्तेमाल करके, चालू थ्रेड की संख्या बढ़ाने के लिए CAS की कोशिश करता है. ज़रूरी कार्रवाई करने के बाद, यह संख्या को कम कर देता है. अगर बिट को बढ़ाने के बाद, लेकिन घटाने से पहले बंद किया गया था और अब गिनती शून्य है, तो यह Looper थ्रेड को चालू करता है.
जब Looper थ्रेड बंद होने के लिए तैयार होता है, तब यह CAS का इस्तेमाल करके एटॉमिक में क्विटिंग बिट सेट करता है. अगर रेफ़काउंट 0 था, तो यह अपने नेटिव ऐलोकेशन को खाली कर सकता है. ऐसा न होने पर, यह खुद को पार्क कर लेता है. ऐसा इसलिए, क्योंकि इसे पता होता है कि जब नेटिव ऐलोकेशन का आखिरी उपयोगकर्ता रेफ़काउंट को कम करेगा, तब इसे चालू किया जाएगा. इस तरीके का मतलब है कि Looper थ्रेड, अन्य थ्रेड के प्रोसेस होने का इंतज़ार करता है. हालांकि, ऐसा सिर्फ़ तब होता है, जब वह बंद हो रहा हो. ऐसा सिर्फ़ एक बार होता है और इससे परफ़ॉर्मेंस पर कोई असर नहीं पड़ता. साथ ही, यह नेटिव ऐलोकेशन का इस्तेमाल करने के लिए, अन्य कोड को पूरी तरह से लॉक-फ़्री रखता है.
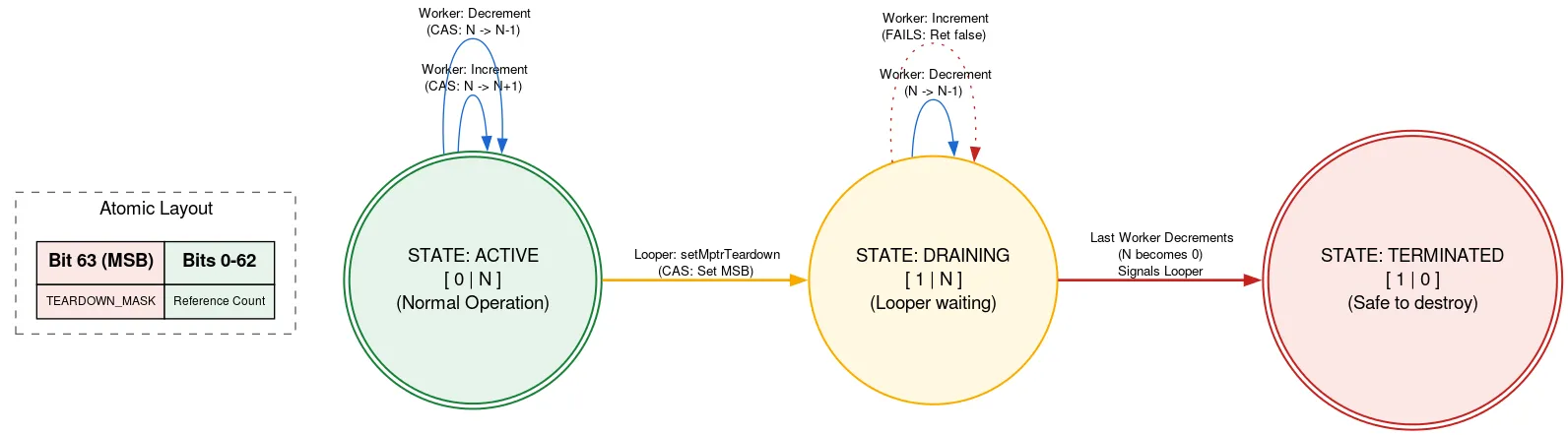
इसे लागू करने के लिए, कई अन्य तरकीबें और जटिलताएं भी हैं. सोर्स कोड देखकर, DeliQueue के बारे में ज़्यादा जाना जा सकता है.
ऑप्टिमाइज़ेशन: ब्रांचलेस प्रोग्रामिंग
DeliQueue को डेवलप और टेस्ट करते समय, टीम ने कई बेंचमार्क चलाए और नए कोड की बारीकी से जांच की. simpleperf टूल का इस्तेमाल करके, एक समस्या का पता लगाया गया. यह समस्या, Message तुलना करने वाले कोड की वजह से पाइपलाइन फ़्लश होने की वजह से हुई थी.
स्टैंडर्ड कंपैरेटर, शर्त के हिसाब से जंप का इस्तेमाल करता है. यह तय करने के लिए कि कौनसी Message पहले आएगी, यहां दी गई शर्त का इस्तेमाल किया जाता है:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}यह कोड, शर्तों के हिसाब से जंप करने वाले निर्देशों (b.le और cbnz निर्देश) में कंपाइल होता है. जब सीपीयू को कोई शर्त वाली ब्रांच मिलती है, तो वह तब तक यह नहीं जान पाता कि ब्रांच को लिया गया है या नहीं, जब तक कि शर्त का हिसाब नहीं लगाया जाता. इसलिए, उसे यह नहीं पता होता कि अगला निर्देश कौन-सा पढ़ना है. उसे अनुमान लगाना पड़ता है. इसके लिए, वह ब्रांच का अनुमान लगाने की तकनीक का इस्तेमाल करता है. बाइनरी सर्च जैसे मामले में, हर चरण में ब्रांच की दिशा का अनुमान नहीं लगाया जा सकता. इसलिए, ऐसा हो सकता है कि आधे अनुमान गलत हों. सर्च और सॉर्टिंग एल्गोरिदम (जैसे कि मिन-हीप में इस्तेमाल किया जाने वाला एल्गोरिदम) में ब्रांच प्रेडिक्शन अक्सर असरदार नहीं होता है. ऐसा इसलिए, क्योंकि गलत अनुमान लगाने की लागत, सही अनुमान लगाने से मिलने वाले फ़ायदे से ज़्यादा होती है. जब ब्रांच प्रेडिक्टर का अनुमान गलत होता है, तो उसे अनुमानित वैल्यू के बाद किए गए काम को हटाना होता है. साथ ही, उसे उस पाथ से फिर से शुरू करना होता है जिसे असल में लिया गया था. इसे पाइपलाइन फ़्लश कहा जाता है.
इस समस्या का पता लगाने के लिए, हमने branch-misses परफ़ॉर्मेंस काउंटर का इस्तेमाल करके अपने बेंचमार्क की प्रोफ़ाइल बनाई. यह काउंटर, स्टैक ट्रेस रिकॉर्ड करता है. इनमें ब्रांच प्रेडिक्टर गलत अनुमान लगाता है. इसके बाद, हमने नतीजों को Google pprof की मदद से विज़ुअलाइज़ किया. यह नीचे दिखाया गया है:
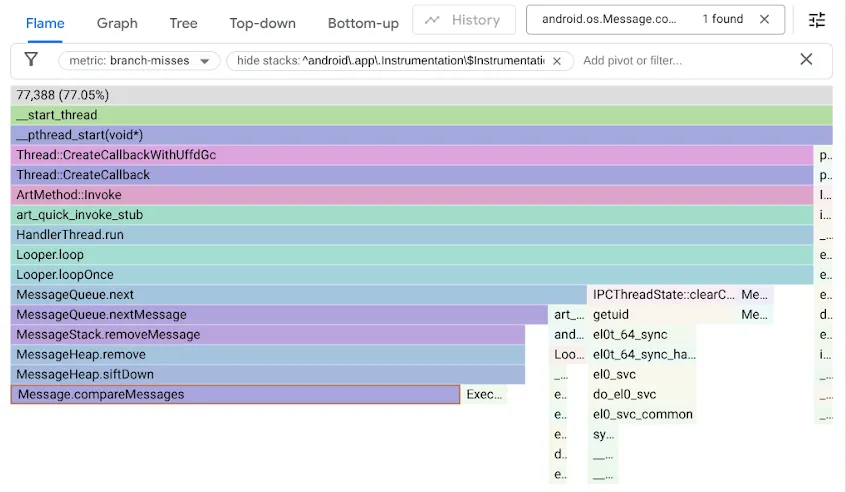
याद करें कि ओरिजनल MessageQueue कोड में, क्रम से लगाई गई सूची के लिए सिंगल-लिंक की गई सूची का इस्तेमाल किया गया था. डेटा डालने के लिए, सूची में क्रम से लीनियर सर्च की जाएगी. यह सर्च, सूची के उस पहले एलिमेंट पर रुकेगी जहां डेटा डालना है. इसके बाद, नए Message को उससे पहले लिंक कर दिया जाएगा. हेड को हटाने के लिए, उसे अनलिंक करना ज़रूरी है. वहीं, DeliQueue में मिन-हीप का इस्तेमाल किया जाता है. इसमें म्यूटेशन के लिए, कुछ एलिमेंट को फिर से क्रम में लगाने (ऊपर या नीचे की ओर ले जाना) की ज़रूरत होती है. ऐसा लॉगरिथमिक कॉम्प्लेक्सिटी के साथ, बैलेंस किए गए डेटा स्ट्रक्चर में किया जाता है. इसमें किसी भी तुलना में, ट्रैवर्सल को बाएं चाइल्ड या दाएं चाइल्ड पर ले जाने की संभावना बराबर होती है. नया एल्गोरिदम, एसिम्प्टोटिक तौर पर ज़्यादा तेज़ है. हालांकि, इससे एक नई समस्या सामने आती है. खोज कोड, आधे समय तक ब्रांच मिस होने की वजह से रुक जाता है.
हमें पता चला कि ब्रांच मिस होने की वजह से, हमारे हीप कोड की स्पीड कम हो रही है. इसलिए, हमने ब्रांच-फ़्री प्रोग्रामिंग का इस्तेमाल करके कोड को ऑप्टिमाइज़ किया:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}ऑप्टिमाइज़ेशन को समझने के लिए, Compiler Explorer में दिए गए दोनों उदाहरणों को अलग-अलग करें. इसके बाद, LLVM-MCA का इस्तेमाल करें. यह एक सीपीयू सिम्युलेटर है, जो सीपीयू साइकल की अनुमानित टाइमलाइन जनरेट कर सकता है.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
शर्त के आधार पर काम करने वाली एक ब्रांच, b.le पर ध्यान दें. अगर when फ़ील्ड की तुलना करने से नतीजा पहले ही पता चल जाता है, तो यह insertSeq फ़ील्ड की तुलना करने से बचती है.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
यहां, ब्रांचलेस कोड को लागू करने में, ब्रांच वाले कोड के सबसे छोटे पाथ की तुलना में भी कम साइकल और निर्देश लगते हैं. इसलिए, यह हर मामले में बेहतर है. इस तकनीक को तेज़ी से लागू करने के साथ-साथ, गलत अनुमान वाली ब्रांच को हटाने से, हमारे कुछ बेंचमार्क में पांच गुना सुधार हुआ है!
हालांकि, यह तरीका हमेशा काम नहीं करता. ब्रांचलेस अप्रोच में, आम तौर पर ऐसा काम करना पड़ता है जिसे बाद में हटा दिया जाता है. अगर ब्रांच का अनुमान ज़्यादातर समय लगाया जा सकता है, तो इस तरह के काम से आपके कोड की स्पीड कम हो सकती है. इसके अलावा, किसी ब्रांच को हटाने से अक्सर डेटा डिपेंडेंसी की समस्या आ जाती है. मॉडर्न सीपीयू, हर साइकल में कई कार्रवाइयां करते हैं. हालांकि, वे किसी निर्देश को तब तक लागू नहीं कर सकते, जब तक पिछले निर्देश से मिले इनपुट तैयार न हो जाएं. इसके उलट, सीपीयू ब्रांच में मौजूद डेटा के बारे में अंदाज़ा लगा सकता है. अगर किसी ब्रांच का अनुमान सही होता है, तो वह आगे काम कर सकता है.
जांच और पुष्टि करना
लॉक-फ़्री एल्गोरिदम के सही होने की पुष्टि करना बहुत मुश्किल होता है!
डेवलपमेंट के दौरान लगातार पुष्टि करने के लिए, हमने स्टैंडर्ड यूनिट टेस्ट के साथ-साथ स्ट्रेस टेस्ट भी लिखे हैं. इनसे यह पुष्टि की जाती है कि कतार में मौजूद डेटा में कोई बदलाव नहीं हुआ है. साथ ही, अगर डेटा रेस मौजूद हैं, तो उन्हें ट्रिगर करने की कोशिश की जाती है. हमारे टेस्ट लैब में, हम इम्यूलेट किए गए डिवाइसों और असली हार्डवेयर पर लाखों टेस्ट इंस्टेंस चला सकते हैं.
Java ThreadSanitizer (JTSan) इंस्ट्रुमेंटेशन की मदद से, हम अपने कोड में कुछ डेटा रेस का पता लगाने के लिए भी इन्हीं टेस्ट का इस्तेमाल कर सकते हैं. JTSan को DeliQueue में डेटा रेस से जुड़ी कोई समस्या नहीं मिली. हालांकि, हैरानी की बात यह है कि उसे Robolectric फ़्रेमवर्क में एक साथ कई कार्रवाइयां होने से जुड़ी दो गड़बड़ियां मिलीं. हमने तुरंत इन गड़बड़ियों को ठीक कर दिया.
डीबग करने की हमारी क्षमताओं को बेहतर बनाने के लिए, हमने नए विश्लेषण टूल बनाए हैं. यहां Android प्लैटफ़ॉर्म कोड में मौजूद समस्या का एक उदाहरण दिया गया है. इसमें एक थ्रेड, दूसरी थ्रेड पर Message का ज़्यादा इस्तेमाल कर रही है. इससे काफ़ी बैकलॉग हो रहा है. यह बैकलॉग, Perfetto में दिखता है. ऐसा MessageQueue इंस्ट्रुमेंटेशन की उस सुविधा की वजह से होता है जिसे हमने जोड़ा है.
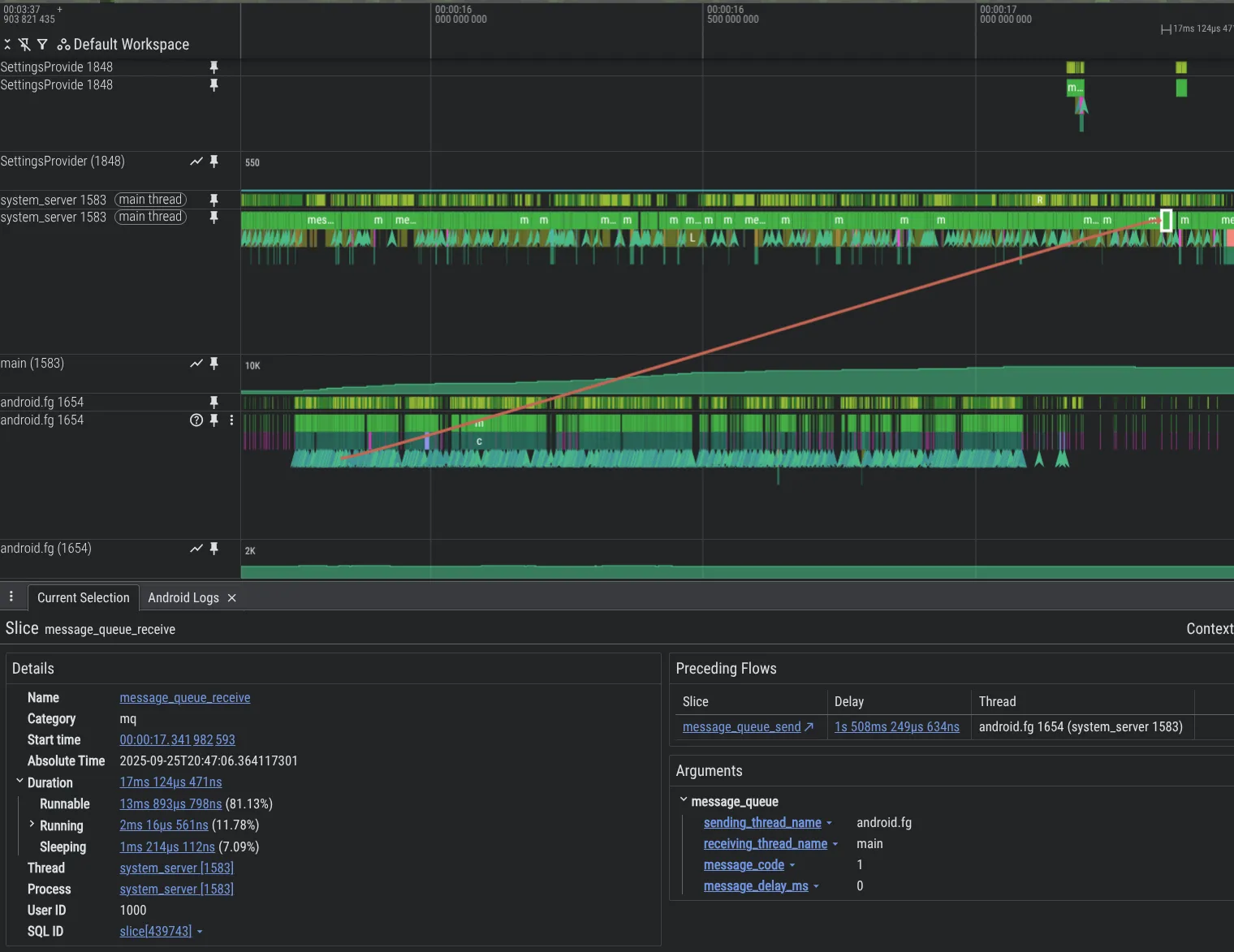
system_server प्रोसेस में MessageQueue ट्रेसिंग की सुविधा चालू करने के लिए, Perfetto कॉन्फ़िगरेशन में यह शामिल करें:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}असर
DeliQueue, MessageQueue से लॉक हटाकर सिस्टम और ऐप्लिकेशन की परफ़ॉर्मेंस को बेहतर बनाता है.
- सिंथेटिक बेंचमार्क: व्यस्त कतारों में मल्टी-थ्रेड किए गए इंसर्शन,लेगसी
MessageQueueकी तुलना में 5, 000 गुना ज़्यादा तेज़ी से होते हैं. ऐसा बेहतर कॉन्करेंसी (ट्राइबर स्टैक) और तेज़ी से इंसर्शन (मिन-हीप) की वजह से होता है. - हमें इंटरनल बीटा टेस्टर से मिले Perfetto ट्रेस में, लॉक कंटेंशन में ऐप्लिकेशन की मुख्य थ्रेड के समय में 15% की कमी दिखी.
- एक ही टेस्ट डिवाइस पर, लॉक कंटेंशन कम होने से उपयोगकर्ता अनुभव में काफ़ी सुधार होता है. जैसे:
- -ऐप्लिकेशन में 4% फ़्रेम छूट गए.
- सिस्टम यूज़र इंटरफ़ेस (यूआई) और लॉन्चर इंटरैक्शन में 7.7% फ़्रेम छूट गए.
- ऐप्लिकेशन चालू होने से लेकर पहली बार फ़्रेम दिखने के बीच लगने वाले समय में 9.1% की कमी आई है. यह 95%ile पर है.
अगले चरण
DeliQueue को Android 17 में ऐप्लिकेशन के लिए रोल आउट किया जा रहा है. ऐप्लिकेशन डेवलपर को, Android Developers ब्लॉग पर जाकर, बिना लॉक के MessageQueue की सुविधा के लिए ऐप्लिकेशन तैयार करने के बारे में पढ़ना चाहिए. इससे उन्हें अपने ऐप्लिकेशन की जांच करने का तरीका पता चलेगा.
रेफ़रंस
[1] Treiber, R.K., 1986. सिस्टम प्रोग्रामिंग: पैरललिज़्म से निपटना. इंटरनेशनल बिज़नेस मशीन कॉर्पोरेशन, थॉमस जे. वॉटसन रिसर्च सेंटर.
[2] Goetz, B., पीयरल्स, टी., ब्लॉक, जे॰, बोबीर, जे॰, होम्स, डी., और डी॰ ली (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंGoogle Play पर, हम उपयोगकर्ताओं को सबसे अच्छा अनुभव देने के लिए प्रतिबद्ध हैं. साथ ही, हम यह भी पक्का करते हैं कि डेवलपर के पास सफल होने के लिए ज़रूरी टूल और अडैप्टेबिलिटी हो.
Paul Feng • तीन मिनट में पढ़ा जा सकता है -

 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंपिछले साल, हमने Android डेवलपर की पहचान की पुष्टि करने की सुविधा लॉन्च की थी. इससे, हमने अपने नेटवर्क की सुरक्षा को बेहतर बनाया था. साथ ही, बुरे मकसद से काम करने वाले लोगों या ग्रुप को नुकसान पहुंचाने वाले ऐप्लिकेशन रिलीज़ करने से रोका था. ये लोग अपनी पहचान छिपाकर ऐसा करते थे.
Matthew Forsythe • दो मिनट में पढ़ें -


 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंऑगमेंटेड ओवरले से लेकर पूरी तरह से इमर्सिव एनवायरमेंट तक, Android XR का इकोसिस्टम तेज़ी से बढ़ रहा है. Samsung Galaxy XR, आज से ही उपलब्ध है.
Stevan Silva, Vinny DaSilva • तीन मिनट में पढ़ा जा सकता है
Android डेवलपमेंट से जुड़ी नई अहम जानकारी, हर हफ़्ते अपने इनबॉक्स में पाएं.
