
Новости о продуктах
Под капотом: функция MessageQueue в Android 17, предотвращающая блокировку.
Чтение займет 16 минут.

В Android 17 приложения, ориентированные на SDK 37 и выше, получат новую реализацию MessageQueue, в которой отсутствуют блокировки. Новая реализация повышает производительность и уменьшает количество пропущенных кадров, но может нарушить работу клиентов, использующих приватные поля и методы MessageQueue. Чтобы узнать больше об изменении поведения и о том, как минимизировать его последствия, ознакомьтесь с документацией по изменению поведения MessageQueue . В этом техническом сообщении в блоге представлен обзор перепроектирования MessageQueue и способов анализа проблем конкуренции за блокировки с помощью Perfetto.
Looper управляет потоком пользовательского интерфейса каждого приложения Android. Он получает данные из MessageQueue , передает их обработчику (Handler ) и повторяет процесс. В течение двух десятилетий MessageQueue использовал единую блокировку монитора (то есть synchronized блок кода) для защиты своего состояния.
В Android 17 представлено значительное обновление этого компонента: реализация без блокировок под названием DeliQueue .
В этой статье объясняется, как блокировки влияют на производительность пользовательского интерфейса, как анализировать эти проблемы с помощью Perfetto, а также конкретные алгоритмы и оптимизации, используемые для улучшения работы основного потока Android.
Проблема: конкуренция за блокировки и инверсия приоритетов.
Устаревшая MessageQueue функционировала как приоритетная очередь, защищенная одной блокировкой. Если фоновый поток отправляет сообщение, пока основной поток выполняет обслуживание очереди, фоновый поток блокирует основной поток.
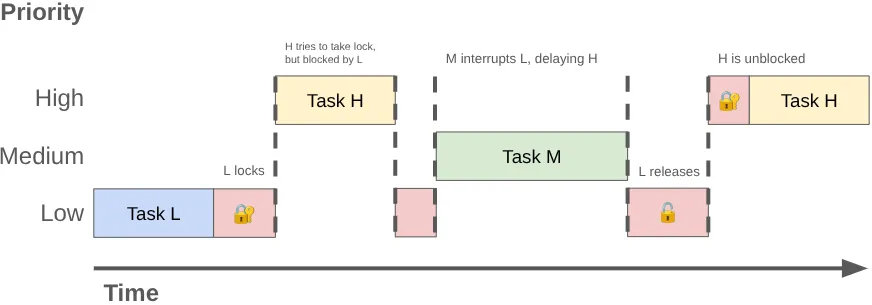
Когда два или более потока конкурируют за исключительное использование одной и той же блокировки, это называется конкуренцией за блокировку . Эта конкуренция может привести к инверсии приоритетов , вызывая задержки в работе пользовательского интерфейса и другие проблемы с производительностью.
Инверсия приоритетов может произойти, когда поток с высоким приоритетом (например, поток пользовательского интерфейса) начинает ожидать поток с низким приоритетом. Рассмотрим следующую последовательность:
- Фоновый поток с низким приоритетом получает блокировку
MessageQueueдля публикации результатов своей работы. - Поток со средним приоритетом становится доступным для выполнения, и планировщик ядра выделяет ему процессорное время, вытесняя поток с низким приоритетом.
- Поток пользовательского интерфейса с высоким приоритетом завершает свою текущую задачу и пытается прочитать данные из очереди, но блокируется, поскольку блокировку удерживает поток с низким приоритетом.
Низкоприоритетный поток блокирует поток пользовательского интерфейса, а работа со средним приоритетом ещё больше задерживает его выполнение.
Анализ противоречий с помощью Perfetto
Диагностировать эти проблемы можно с помощьюPerfetto . В стандартном трассировочном отчете поток, заблокированный на блокировке монитора, переходит в спящий режим, и Perfetto отображает фрагмент, указывающий на владельца блокировки.
При запросе данных трассировки ищите фрагменты с именем «monitor contention with …», за которым следует имя потока, которому принадлежит блокировка, и фрагмент кода, где была получена блокировка.
Пример из практики: сбои в работе лаунчера
Для наглядности проанализируем трассировку, в которой пользователь столкнулся с зависанием при переходе на главный экран телефона Pixel сразу после съемки фотографии в приложении камеры. Ниже представлен скриншот Perfetto, показывающий события, предшествовавшие пропуску кадра:
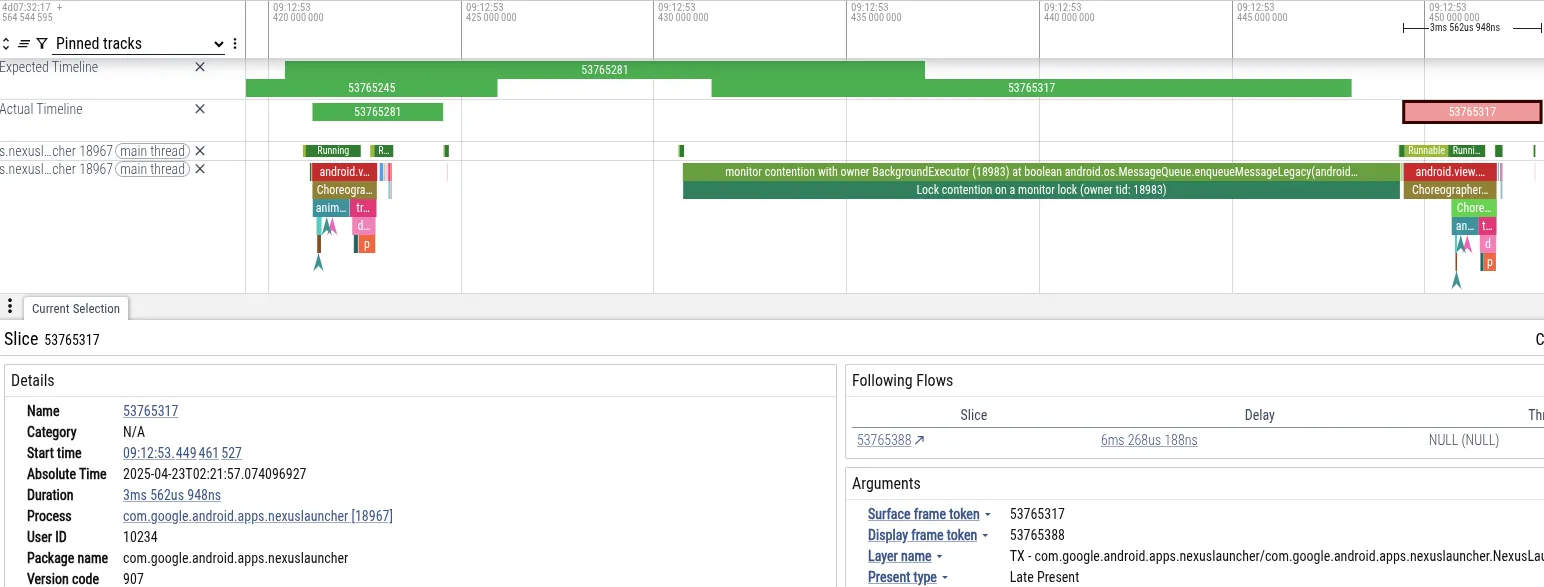
- Симптом: Основной поток запуска программы не уложился в установленный лимит кадров. Он заблокировался на 18 мс, что превышает 16 мс, необходимых для рендеринга с частотой 60 Гц.
- Диагноз: Perfetto показал, что основной поток заблокирован блокировкой
MessageQueue. Блокировка принадлежала потоку «BackgroundExecutor». - Первопричина: BackgroundExecutor работает с приоритетом Process.THREAD_PRIORITY_BACKGROUND (очень низкий приоритет). Он выполнял несрочную задачу (проверка лимитов использования приложения ). Одновременно потоки со средним приоритетом использовали процессорное время для обработки данных с камеры. Планировщик операционной системы вытеснил поток BackgroundExecutor для выполнения потоков, связанных с камерой.
Эта последовательность действий привела к тому, что поток пользовательского интерфейса Launcher (высокий приоритет) был косвенно заблокирован рабочим потоком камеры (средний приоритет), который препятствовал фоновому потоку Launcher (низкий приоритет) снять блокировку.
Запрос трассировки с помощью PerfettoSQL
С помощью PerfettoSQL можно запрашивать данные трассировки по определенным шаблонам. Это полезно, если у вас есть большой массив трассировок с пользовательских устройств или тестов, и вы ищете конкретные трассировки, демонстрирующие проблему.
Например, этот запрос обнаруживает конфликты MessageQueue совпадающие с потерей кадров (рывками):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
В этом более сложном примере объедините данные трассировки, охватывающие несколько таблиц, чтобы выявить конфликты очередей сообщений во время запуска приложения:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Вы можете использовать свой любимый язык программирования для написания запросов PerfettoSQL с целью поиска других шаблонов.
В Google мы используем BigTrace для выполнения запросов PerfettoSQL по миллионам трассировок. В результате мы подтвердили, что то, что мы наблюдали на практике, на самом деле является системной проблемой. Данные показали, что конфликты блокировок MessageQueue влияют на пользователей во всей экосистеме, что подтверждает необходимость фундаментальных архитектурных изменений.
Решение: бесблокировочная параллельная обработка
Мы решили проблему конкуренции MessageQueue , реализовав структуру данных без блокировок , используя атомарные операции с памятью вместо эксклюзивных блокировок для синхронизации доступа к общему состоянию. Структура данных или алгоритм являются безблокировочными, если хотя бы один поток всегда может продвигаться вперед независимо от поведения планирования других потоков. Это свойство, как правило, трудно достичь, и обычно не стоит стремиться к нему для большинства кода .
Атомные примитивы
Программное обеспечение, не использующее блокировки, часто опирается на атомарные примитивы чтения-изменения-записи, предоставляемые оборудованием.
На процессорах ARM64 более старых поколений атомарные операции использовали цикл «Загрузка-Связь/Сохранение-Условие» (LL/SC). Процессор загружает значение и помечает адрес. Если другой поток записывает данные по этому адресу, операция сохранения завершается неудачей, и цикл повторяется. Поскольку потоки могут продолжать попытки и успешно завершать их, не дожидаясь другого потока, эта операция не блокируется.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr( Просмотреть в обозревателе компиляторов )
Более новые архитектуры ARM (ARMv8.1) поддерживают расширения больших систем (LSE) , которые включают инструкции в виде сравнения и замены (CAS) или загрузки и сложения (показано ниже). В Android 17 мы добавили поддержку компилятора Android Runtime (ART) для определения поддержки LSE и генерации оптимизированных инструкций:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.В наших тестах высококонкурентный код, использующий CAS, обеспечивает примерно трехкратное ускорение по сравнению с вариантом LL/SC.
Язык программирования Java предоставляет атомарные примитивы через java.util.concurrent.atomic , которые используют эти и другие специализированные инструкции ЦП.
Структура данных: DeliQueue
Для устранения конфликтов блокировок в MessageQueue наши инженеры разработали новую структуру данных под названием DeliQueue . DeliQueue разделяет вставку Message и Message обработку:
- Список
Messages(стек Treiber): Стек без блокировок. Любой поток может добавлять сюда новыеMessagesбез конфликтов. - Приоритетная очередь (минимальная куча): куча
Messagesдля обработки, принадлежащая исключительно потоку Looper (следовательно, для доступа к ней не требуется синхронизация или блокировки).
Добавить в очередь: отправить в стек Treiber
Список Messages хранится в стеке Treiber [1], стеке без блокировок, который использует цикл CAS для обновления указателя головы.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Исходный код, основанный на Java Concurrency in Practice [2], доступен в сети и выпущен в общественное достояние.
Любой производитель может в любой момент добавить новые Message в стек. Это похоже на вытягивание чека в гастрономическом отделе — ваш номер определяется временем вашего прихода, но порядок получения еды не обязательно должен совпадать. Поскольку это связанный стек, каждое Message является подстеком — вы можете увидеть, как выглядела очередь Message в любой момент времени, отслеживая начало и итерируя вперед — вы не увидите, чтобы новые Message добавлялись сверху, даже если они добавляются во время вашего обхода.
Извлечение из очереди: массовая передача данных в минимальную кучу.
Чтобы найти следующее Message для обработки, Looper обрабатывает новые Message из стека Treiber, проходя по стеку, начиная с вершины и итерируя до тех пор, пока не найдет последнее Message , которое он обработал ранее. По мере продвижения вниз по стеку Looper вставляет Message в минимальную кучу, упорядоченную по времени выполнения. Поскольку Looper является единственным владельцем кучи, он упорядочивает и обрабатывает Message без блокировок или атомарных операций.

При перемещении вниз по стеку Looper также создает ссылки от расположенных в стеке Message обратно к их предшественникам, образуя таким образом двусвязный список. Создание связанного списка безопасно, поскольку ссылки, указывающие вниз по стеку, добавляются с помощью алгоритма стека Treiber с CAS, а ссылки вверх по стеку считываются и изменяются только потоком Looper . Затем эти обратные ссылки используются для удаления Message из произвольных точек стека за время O(1).
Данная конструкция обеспечивает вставку O (1) для производителей (потоков, отправляющих работу в очередь) и амортизированную обработку O (log N) для потребителя ( Looper ).
Использование минимальной кучи для упорядочивания Message также устраняет фундаментальный недостаток устаревшей MessageQueue ), где Message хранились в односвязном списке (с корнем вверху). В устаревшей реализации удаление из начала очереди занимало O (1), но вставка в худшем случае имела O(N) – что плохо масштабировалось для перегруженных очередей! Напротив, вставка и удаление из минимальной кучи масштабируются логарифмически, обеспечивая конкурентоспособную среднюю производительность, но особенно превосходя ожидания по задержкам в конце очереди.
Устаревшая (заблокированная) MessageQueue | DeliQueue | |
| Вставлять | НА) | O (1) для вызова потока O(logN) для потока |
| Удалить из головы | О (1) | O(logN) |
В устаревшей реализации очередей производители и потребители использовали блокировку для координации эксклюзивного доступа к базовому односвязному списку. В DeliQueue стек Treiber обрабатывает одновременный доступ, а единственный потребитель отвечает за упорядочивание своей очереди задач.
Удаление: обеспечение единообразия посредством надгробий.
DeliQueue — это гибридная структура данных, объединяющая стек Treiber без блокировок и однопоточную минимальную кучу. Поддержание синхронизации этих двух структур без глобальной блокировки представляет собой уникальную задачу: сообщение может физически присутствовать в стеке, но логически быть удалено из очереди.
Для решения этой проблемы DeliQueue использует метод, называемый «удалением из стека». Каждое Message отслеживает свою позицию в стеке с помощью указателей назад и вперед, своего индекса в массиве кучи и логического флага, указывающего, было ли оно удалено. Когда Message готово к выполнению, поток Looper выполняет CAS-преобразование флага удаления, а затем удаляет его из кучи и стека.
Когда другому потоку необходимо удалить Message , он не извлекает его немедленно из структуры данных. Вместо этого он выполняет следующие шаги:
- Логическое удаление: поток использует CAS для атомарной установки флага удаления
Messageиз значения false в true.Messageостается в структуре данных как свидетельство его предстоящего удаления, так называемый «надгробный камень». Как толькоMessageпомечено для удаления, DeliQueue обрабатывает его так, как если бы оно больше не существовало в очереди, всякий раз, когда оно обнаруживается. - Отложенная очистка: фактическое удаление из структуры данных является обязанностью потока
Looperи откладывается на более поздний срок. Вместо изменения стека или кучи поток удаления добавляетMessageв другой стек списка свободных блоков, не содержащий блокировок. - Удаление структурных элементов: Только
Looperможет взаимодействовать с кучей или удалять элементы из стека. После пробуждения он очищает список свободных элементов и обрабатывает содержащиеся в немMessage. Затем каждоеMessageотсоединяется от стека и удаляется из кучи.
Такой подход обеспечивает однопоточное управление всей кучей данных. Он минимизирует количество параллельных операций и необходимых барьеров памяти, что делает критический путь быстрее и проще.
Обход: безобидные состояния гонки данных в модели памяти Java
Большинство API для работы с параллельными вычислениями, такие как Future в стандартной библиотеке Java или Job и Deferred в Kotlin, включают механизм отмены работы до ее завершения. Экземпляр одного из этих классов соответствует единице базовой работы в соотношении 1:1, и вызов метода cancel для объекта отменяет конкретные операции, связанные с ним.
Современные устройства Android оснащены многоядерными процессорами и параллельной сборкой мусора, охватывающей несколько поколений. Но когда Android только разрабатывался, выделение отдельного объекта для каждой единицы работы было слишком затратным. Следовательно, Handler Android поддерживает отмену с помощью многочисленных перегрузок метода removeMessages — вместо удаления конкретного Message , он удаляет все Message , соответствующие указанным критериям. На практике это требует перебора всех Message , добавленных до вызова removeMessages , и удаления тех, которые соответствуют критериям.
При итерации вперед потоку требуется всего одна упорядоченная атомарная операция — чтение текущего начала стека. После этого для поиска следующего Message используются обычные операции чтения полей. Если поток Looper изменяет next поля, одновременно удаляя Message , запись в Looper и чтение в другом потоке не синхронизируются — это состояние гонки данных . Обычно гонка данных — это серьезная ошибка, которая может вызвать огромные проблемы в вашем приложении: утечки памяти, бесконечные циклы, сбои, зависания и многое другое. Однако при определенных узких условиях гонки данных могут быть безобидными в рамках модели памяти Java. Предположим, мы начинаем со стека из:

Мы выполняем атомарное чтение из головки и видим A. Следующий указатель A указывает на B. Одновременно с обработкой B, цикл может удалить B и C, обновив указатель A так, чтобы он указывал на C, а затем на D.
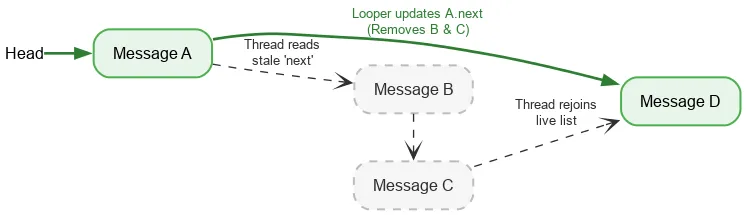
Несмотря на логическое удаление узлов B и C , узел B сохраняет указатель next на C , а C — на D Поток чтения продолжает перемещаться по отсоединенным удаленным узлам и в конечном итоге снова присоединяется к активному стеку в D
Разрабатывая DeliQueue таким образом, чтобы обрабатывать конфликты между перемещением и удалением элементов, мы обеспечиваем безопасную итерацию без блокировок.
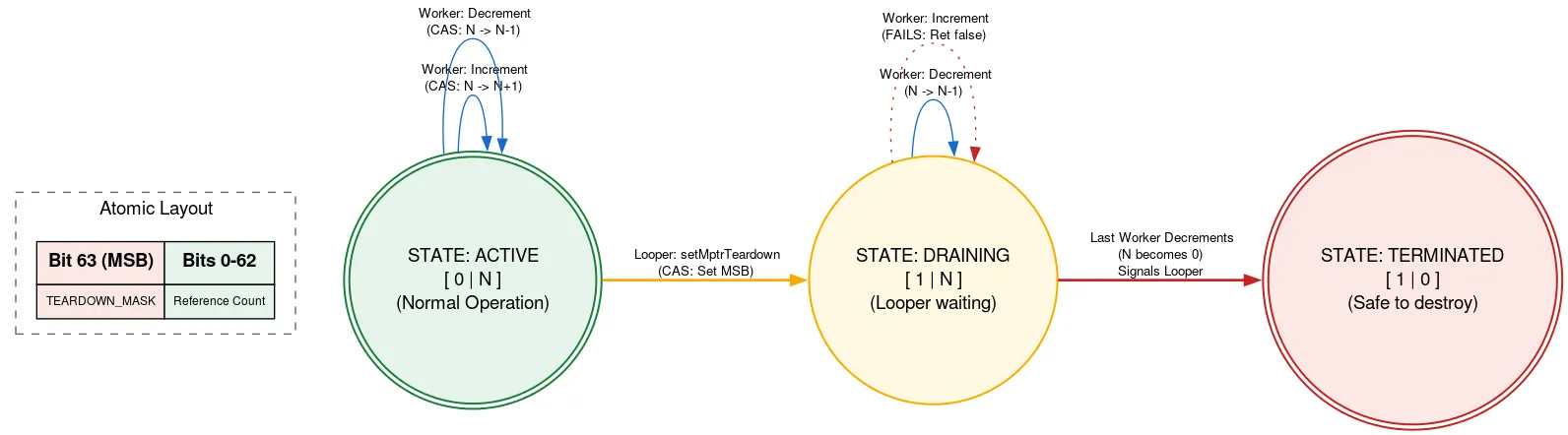
Выход из системы: подсчет реферальных ссылок
Looper использует собственное выделение памяти, которое необходимо освободить вручную после завершения работы Looper . Если какой-либо другой поток добавляет Message ) во время завершения работы Looper , он может использовать собственное выделение памяти после его освобождения, что является нарушением безопасности памяти. Мы предотвращаем это с помощью помеченного счетчика ссылок (refcount) , где один бит атомарной операции используется для указания того, завершает ли работу Looper .
Перед использованием выделенной памяти поток атомарно считывает счетчик ссылок. Если установлен бит завершения, поток возвращает сообщение о завершении работы Looper и о том, что выделенная память не должна использоваться. В противном случае он пытается выполнить операцию CAS для увеличения количества активных потоков, использующих выделенную память. После выполнения необходимых действий он уменьшает счетчик. Если бит завершения был установлен после увеличения, но до уменьшения, и счетчик теперь равен нулю, то поток Looper пробуждается.
Когда поток Looper готов завершить работу, он использует CAS для установки бита завершения в атомарной операции. Если счетчик ссылок равен 0, он может продолжить освобождение выделенной памяти. В противном случае он приостанавливает свою работу, зная, что будет разбужен, когда последний пользователь выделенной памяти уменьшит счетчик ссылок. Такой подход означает, что поток Looper ожидает завершения работы других потоков, но только в момент своего выхода. Это происходит только один раз и не является критически важным с точки зрения производительности, а также обеспечивает полную защиту от блокировок остального кода, использующего выделенную память.
В реализации есть множество других ухищрений и сложностей. Вы можете узнать больше о DeliQueue, изучив исходный код.
Оптимизация: бесветвевое программирование
В процессе разработки и тестирования DeliQueue команда провела множество сравнительных тестов и тщательно проанализировала новый код. Одна из проблем, выявленных с помощью инструмента simpleperf, заключалась в сбросе конвейера, вызванном кодом компаратора Message .
Стандартный компаратор использует условные переходы, при этом условие для определения того, какое Message идет первым, упрощено ниже:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
} Этот код компилируется в условные переходы (инструкции b.le и cbnz ). Когда процессор встречает условный переход, он не может знать, был ли выполнен переход, пока не будет вычислено условие, поэтому он не знает, какую инструкцию читать следующей, и должен угадывать, используя метод, называемый предсказанием ветвлений . В случае, подобном бинарному поиску, направление перехода будет непредсказуемо разным на каждом шаге, поэтому вероятно, что половина предсказаний будет неверной. Предсказание ветвлений часто неэффективно в алгоритмах поиска и сортировки (таких как тот, что используется в минимальной куче), потому что стоимость неправильного угадывания больше, чем улучшение от правильного угадывания. Когда предсказатель ветвлений угадывает неправильно, он должен отбросить работу, проделанную после принятия предсказанного значения, и начать заново с пути, который был фактически пройден — это называется очисткой конвейера .
Чтобы выявить эту проблему, мы провели профилирование наших бенчмарков, используя счетчик производительности branch-misses , который записывает трассировки стека в тех случаях, когда предсказатель ветвлений ошибается. Затем мы визуализировали результаты с помощью Google pprof , как показано ниже:
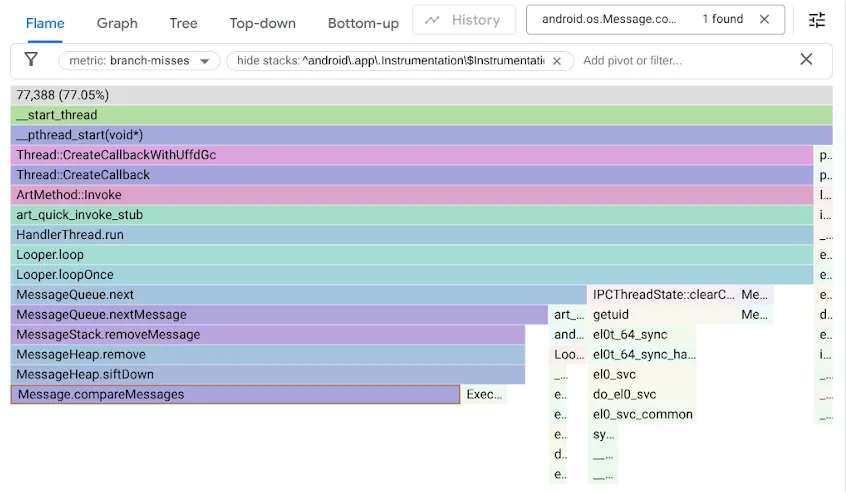
Напомним, что в исходном коде MessageQueue для упорядоченной очереди использовался односвязный список. Вставка осуществлялась путем обхода списка в отсортированном порядке как линейный поиск, останавливаясь на первом элементе, который находится после точки вставки, и связывая новое Message перед ним. Удаление из начала списка просто требовало разъединения начала списка. В то время как DeliQueue использует минимальную кучу, где изменения требуют переупорядочивания некоторых элементов (просеивание вверх или вниз) с логарифмической сложностью в сбалансированной структуре данных, где любое сравнение имеет равные шансы направить обход к левому или правому потомку. Новый алгоритм асимптотически быстрее, но выявляет новое узкое место, поскольку код поиска застревает на промахах ветвления в половине случаев.
Понимая, что промахи при переходе между ветвями замедляют работу нашего кода, описывающего кучу памяти, мы оптимизировали код, используя программирование без ветвлений :
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Чтобы понять принцип оптимизации, декомпилируйте два примера в Compiler Explorer и используйте LLVM-MCA — симулятор ЦП, который может сгенерировать приблизительную временную шкалу циклов ЦП .
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Обратите внимание на одну условную ветвь, b.le , которая позволяет избежать сравнения полей insertSeq если результат уже известен из сравнения полей when .
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
В данном случае реализация без ветвлений занимает меньше циклов и инструкций, чем даже кратчайший путь через разветвленный код — она лучше во всех случаях. Более быстрая реализация плюс устранение ошибочно предсказанных ветвлений привели к пятикратному улучшению результатов в некоторых наших тестах!
Однако этот метод применим не всегда. Подходы без ветвлений обычно требуют выполнения работы, которая в конечном итоге будет потеряна, и если ветвление предсказуемо в большинстве случаев, эта потерянная работа может замедлить выполнение кода. Кроме того, удаление ветвления часто приводит к зависимости данных . Современные процессоры выполняют несколько операций за цикл, но они не могут выполнить инструкцию, пока не будут готовы входные данные от предыдущей инструкции. В отличие от них, процессор может спекулировать на данных в ветвлениях и работать на опережение, если ветвление предсказано правильно.
Тестирование и проверка
Проверить корректность алгоритмов, работающих без блокировок, крайне сложно!
В дополнение к стандартным модульным тестам для непрерывной проверки в процессе разработки, мы также написали строгие стресс-тесты для проверки инвариантов очередей и для попытки вызвать состояния гонки данных, если таковые существовали. В наших тестовых лабораториях мы могли запускать миллионы тестовых экземпляров на эмулируемых устройствах и на реальном оборудовании.
С помощью инструментария Java ThreadSanitizer (JTSan) мы смогли использовать те же тесты для обнаружения состояний гонки данных в нашем коде. JTSan не обнаружил никаких проблемных состояний гонки данных в DeliQueue, но, к нашему удивлению, выявил две ошибки параллельного выполнения в фреймворке Robolectric, которые мы оперативно исправили.
Для улучшения возможностей отладки мы разработали новые инструменты анализа . Ниже приведён пример, демонстрирующий проблему в коде платформы Android, где один поток перегружает другой поток Message , вызывая большой объем необработанных запросов, видимый в Perfetto благодаря добавленной нами функции инструментирования MessageQueue .
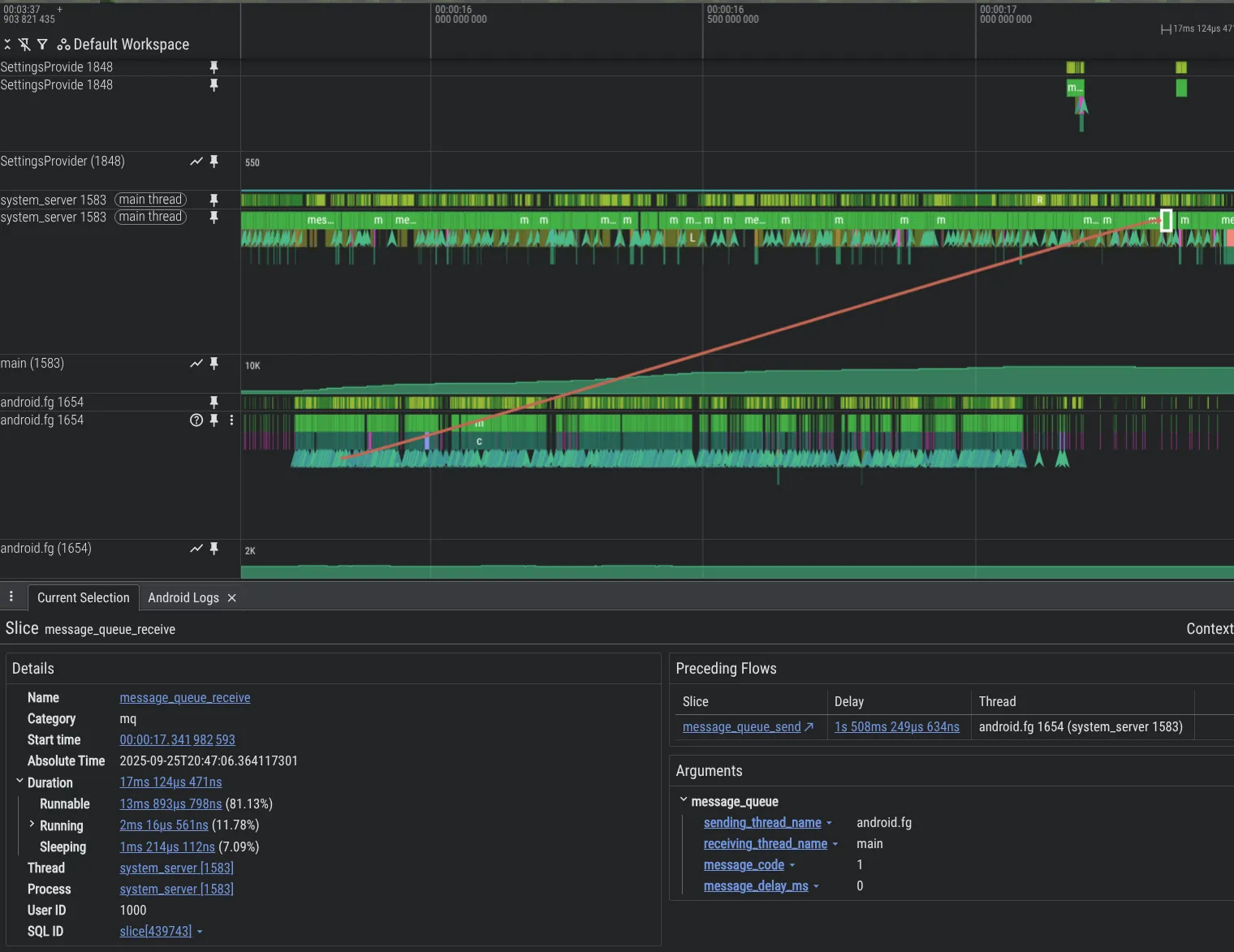
Чтобы включить трассировку MessageQueue в процессе system_server , добавьте в конфигурацию Perfetto следующее:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Влияние
DeliQueue повышает производительность системы и приложений, устраняя блокировки в MessageQueue .
- Результаты синтетических тестов: многопоточная вставка данных в загруженные очереди выполняется до 5000 раз быстрее, чем в устаревшей
MessageQueue, благодаря улучшенной параллельности (стек Treiber) и более быстрой вставке (минимальная куча). - В трассировках Perfetto, полученных от внутренних бета-тестеров , мы видим сокращение времени, затрачиваемого основным потоком приложения на конфликты блокировок, на 15%.
- На тех же тестовых устройствах снижение конкуренции за блокировки приводит к значительному улучшению пользовательского опыта, например:
- -4% пропущенных кадров в приложениях.
- -7,7% пропущенных кадров при взаимодействии с системным интерфейсом и панелью запуска.
- -9,1% времени от запуска приложения до отрисовки первого кадра (на 95-м процентиле).
Следующие шаги
Функция DeliQueue внедряется в приложения Android 17. Разработчикам приложений следует ознакомиться с информацией о подготовке приложения к работе с новой функцией MessageQueue без блокировки в блоге разработчиков Android, чтобы узнать, как тестировать свои приложения.
Ссылки
[1] Трейбер, Р.К., 1986. Системное программирование: как справляться с параллелизмом. International Business Machines Incorporated, Исследовательский центр Томаса Дж. Уотсона.
[2] Гетц, Б., Пейерлс, Т., Блох, Дж., Боубир, Дж., Холмс, Д., и Ли, Д. (2006). Параллелизм в Java на практике. Addison-Wesley Professional.
Автор:
Продолжить чтение


Новости о продуктах
В прошлом году мы ввели проверку разработчиков Android, чтобы усилить безопасность экосистемы и предотвратить распространение вредоносных приложений злоумышленниками, которые, скрываясь за анонимностью, выпускают опасные приложения.
Matthew Forsythe • 2 мин чтения



Новости о продуктах
От дополненной реальности до полностью иммерсивных сред — экосистема Android XR стремительно расширяется, и Samsung Galaxy XR уже доступен для покупки сегодня.
Stevan Silva , Vinny DaSilva • Чтение 3 минуты


Новости о продуктах
Каждый год конференция Google I/O представляет новые анонсы и ресурсы для различных экосистем и продуктов, включая разработку под Android. Поскольку разработка всё больше ориентируется на искусственный интеллект и инструменты с поддержкой агентов, мы расширили спектр наших предложений, чтобы лучше поддерживать вас независимо от того, какой подход к разработке вы выберете для Android.
Simona Milanovic • 2 мин чтения
Будьте в курсе событий
Получайте еженедельно самые свежие новости о разработке Android прямо на свою электронную почту.
