
WorkManager позволяет создавать и ставить в очередь цепочку задач, которая определяет несколько зависимых задач и порядок их выполнения. Эта функциональность особенно полезна, когда необходимо выполнять несколько задач в определенной последовательности.
Для создания цепочки задач можно использовать WorkManager.beginWith(OneTimeWorkRequest) или WorkManager.beginWith(List<OneTimeWorkRequest>) , каждый из которых возвращает экземпляр WorkContinuation .
Затем объект WorkContinuation можно использовать для добавления зависимых экземпляров OneTimeWorkRequest с помощью then(OneTimeWorkRequest) или then(List<OneTimeWorkRequest>) .
Каждый вызов метода WorkContinuation.then(...) возвращает новый экземпляр WorkContinuation . Если добавить List экземпляров OneTimeWorkRequest , эти запросы потенциально могут выполняться параллельно.
Наконец, вы можете использовать метод WorkContinuation.enqueue() для enqueue() цепочки вызовов WorkContinuation в очередь.
Рассмотрим пример. В этом примере настроено выполнение 3 различных задач Worker (возможно, параллельно). Результаты этих задач Worker объединяются и передаются в задачу Worker, отвечающую за кэширование. Наконец, выходные данные этой задачи передаются в задачу Worker, отвечающую за загрузку, которая загружает результаты на удаленный сервер.
Котлин
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
Слияния входных данных
При объединении экземпляров OneTimeWorkRequest выходные данные родительских запросов передаются в качестве входных данных дочерним экземплярам. Таким образом, в приведенном выше примере выходные данные экземпляров plantName1 , plantName2 и plantName3 будут переданы в качестве входных данных для запроса cache .
Для управления входными данными из нескольких родительских запросов на выполнение работ WorkManager использует InputMerger .
В WorkManager предоставляются два разных типа InputMerger :
OverwritingInputMergerпытается добавить все ключи из всех входных данных в выходные. В случае конфликтов он перезаписывает ранее установленные ключи.ArrayCreatingInputMergerпытается объединить входные данные, создавая массивы при необходимости.
Если у вас более специфичный сценарий использования, вы можете написать собственный класс, создав подкласс InputMerger .
ПерезаписьВходногоСлияния
Метод OverwritingInputMerger используется по умолчанию для слияния. Если при слиянии возникают конфликты ключей, то последнее значение ключа перезапишет все предыдущие версии в результирующих выходных данных.
Например, если каждый из входных параметров растения имеет ключ, соответствующий имени соответствующей переменной ( "plantName1" , "plantName2" и "plantName3" ), то данные, передаваемые в cache процесс, будут содержать три пары ключ-значение.
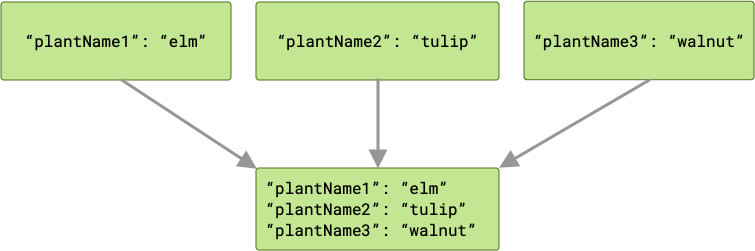
В случае возникновения конфликта, последний завершивший операцию «побеждает», и его значение передается в cache .
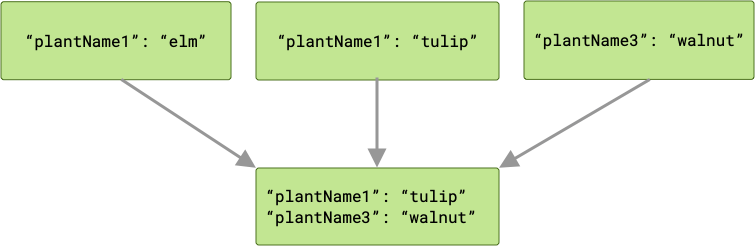
Поскольку ваши запросы на выполнение выполняются параллельно, вы не можете гарантировать порядок их выполнения. В приведенном выше примере plantName1 может содержать значение либо "tulip" , либо "elm" , в зависимости от того, какое значение будет записано последним. Если существует вероятность конфликта ключей и вам необходимо сохранить все выходные данные при слиянии, то ArrayCreatingInputMerger может быть лучшим вариантом.
ArrayCreatingInputMerger
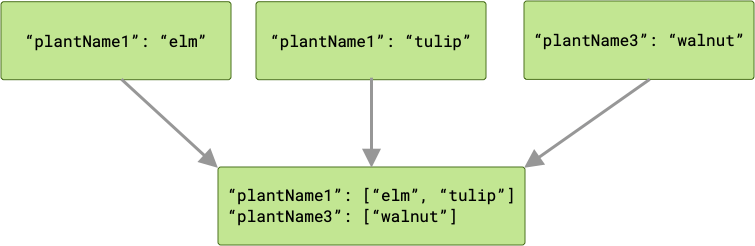
В приведенном выше примере, учитывая, что мы хотим сохранить выходные данные от всех рабочих с определенными названиями заводов, нам следует использовать ArrayCreatingInputMerger .
Котлин
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
ArrayCreatingInputMerger сопоставляет каждый ключ с массивом. Если каждый из ключей уникален, то результатом будет последовательность массивов, состоящих из одного элемента.
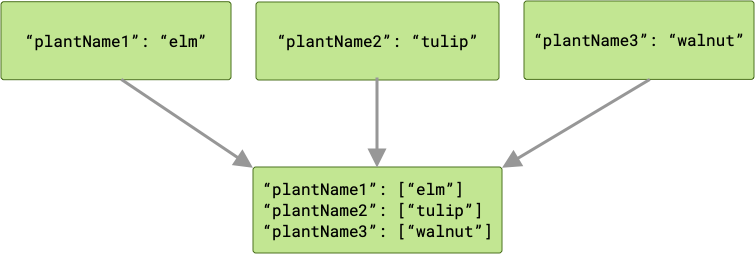
В случае возникновения конфликтов ключей соответствующие значения группируются в массив.
Статусы цепочки задач и статусы работы
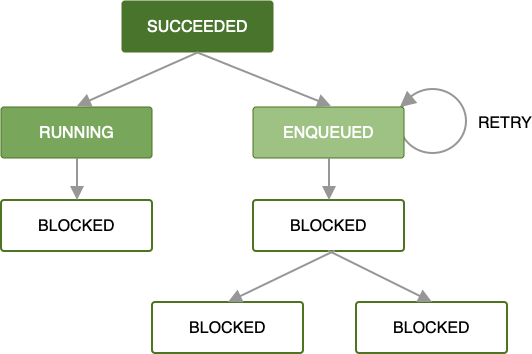
Цепочки запросов OneTimeWorkRequest выполняются последовательно до тех пор, пока их работа успешно завершается (то есть, они возвращают Result.success() ). Запросы на выполнение работы могут завершиться неудачей или быть отменены во время выполнения, что оказывает влияние на зависимые запросы на выполнение работы.
Когда первый запрос OneTimeWorkRequest ставится в очередь в цепочке запросов на выполнение работ, все последующие запросы блокируются до тех пор, пока не будет завершена работа по первому запросу.

После того, как запрос на выполнение задания поставлен в очередь и выполнены все ограничения по объему работы, начинается его выполнение. Если работа успешно завершена в корневом объекте OneTimeWorkRequest или List<OneTimeWorkRequest> (то есть, возвращается Result.success() ), то в очередь будет поставлен следующий набор зависимых запросов на выполнение работы.

Пока каждый запрос на выполнение работы успешно завершается, этот же принцип распространяется на всю цепочку запросов, пока не будет выполнена вся работа в цепочке. Хотя это самый простой и часто предпочтительный случай, обработка ошибок не менее важна.
Если во время обработки вашего запроса работником возникает ошибка, вы можете повторить этот запрос в соответствии с определенной вами политикой задержки . Повторная попытка обработки запроса, являющегося частью цепочки, означает, что будет повторен только этот запрос с предоставленными ему входными данными. Любая работа, выполняемая параллельно, останется без изменений.
Для получения дополнительной информации о настройке пользовательских стратегий повторных попыток см. раздел «Политика повторных попыток и задержки» .
Если политика повторных попыток не определена или исчерпана, или вы иным образом достигаете состояния, при котором OneTimeWorkRequest возвращает Result.failure() , то этот запрос на выполнение работы и все зависимые от него запросы на выполнение работы помечаются как FAILED.

Та же логика применяется и при отмене запроса OneTimeWorkRequest . Все зависимые запросы на выполнение работ также помечаются как CANCELLED , и их работа не будет выполнена.
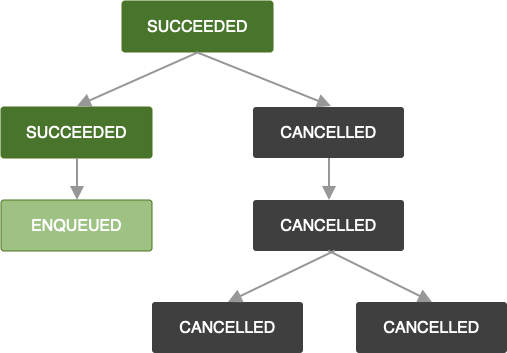
Обратите внимание, что если вы добавите новые запросы на выполнение работ к цепочке, в которой запросы на выполнение работ завершились неудачей или были отменены, то ваш новый добавленный запрос на выполнение работ также будет помечен как FAILED или CANCELLED соответственно. Если вы хотите продлить выполнение работ в существующей цепочке, см. APPEND_OR_REPLACE в ExistingWorkPolicy .
При создании цепочек запросов на выполнение работ зависимые запросы должны определять правила повторных попыток, чтобы гарантировать своевременное завершение работы. Неудачные запросы на выполнение работ могут привести к незавершенным цепочкам и/или непредвиденному состоянию.
Для получения более подробной информации см. раздел «Отмена и прекращение работ» .