
Produktneuheiten
KI-gestützte Android-Entwicklung verbessern und LLMs mit Android Bench optimieren
Lesezeit: 2 Minuten


Wir möchten Ihnen die Entwicklung hochwertiger Android-Apps erleichtern und beschleunigen. Dazu stellen wir Ihnen KI zur Verfügung, damit Sie produktiver arbeiten können. Wir wissen, dass Sie KI benötigen, die die Nuancen der Android-Plattform wirklich versteht. Deshalb haben wir gemessen, wie LLMs bei Android-Entwicklungsaufgaben abschneiden. Heute haben wir die erste Version von Android Bench veröffentlicht, unserer offiziellen Rangliste von LLMs für die Android-Entwicklung.
Unser Ziel ist es, Modellentwicklern einen Benchmark zur Verfügung zu stellen, mit dem sie LLM-Funktionen für die Android-Entwicklung bewerten können. Durch die Festlegung einer klaren, zuverlässigen Grundlage für hochwertige Android-Entwicklung helfen wir Modellerstellern, Lücken zu erkennen und Verbesserungen zu beschleunigen. So können Entwickler effizienter mit einer größeren Auswahl an hilfreichen Modellen für die KI-Unterstützung arbeiten, was letztendlich zu Apps von höherer Qualität im gesamten Android-Ökosystem führt.
Entwickelt für reale Android-Entwicklungsaufgaben
Wir haben die Benchmark erstellt, indem wir eine Reihe von Aufgaben in verschiedenen gängigen Bereichen der Android-Entwicklung zusammengestellt haben. Es besteht aus echten Herausforderungen mit unterschiedlichem Schwierigkeitsgrad, die aus öffentlichen GitHub-Android-Repositories stammen. Dazu gehören beispielsweise das Beheben von Inkompatibilitäten zwischen Android-Releases, domänenspezifische Aufgaben wie die Netzwerkkommunikation auf Wearables und die Migration zur neuesten Version von Jetpack Compose.
Bei jeder Bewertung wird versucht, das in der Aufgabe gemeldete Problem mit einem LLM zu beheben. Anschließend wird die Lösung mit Unit- oder Instrumentierungstests überprüft. Dieser modellunabhängige Ansatz ermöglicht es uns, die Fähigkeit eines Modells zu messen, komplexe Codebases zu durchsuchen, Abhängigkeiten zu verstehen und die Art von Problemen zu lösen, die Sie täglich haben.
Wir haben diese Methodik mit mehreren LLM-Anbietern, darunter JetBrains, validiert.
„Die Auswirkungen von KI auf Android zu messen, ist eine große Herausforderung. Daher ist es gut, ein so fundiertes und realistisches Framework zu sehen. Wir führen zwar selbst Benchmarks durch, aber Android Bench ist eine einzigartige und willkommene Ergänzung. Diese Methodik ist genau die Art von strenger Bewertung, die Android-Entwickler derzeit benötigen.“
– Kirill Smelov, Head of AI Integrations bei JetBrains.
Erste Android Bench-Ergebnisse
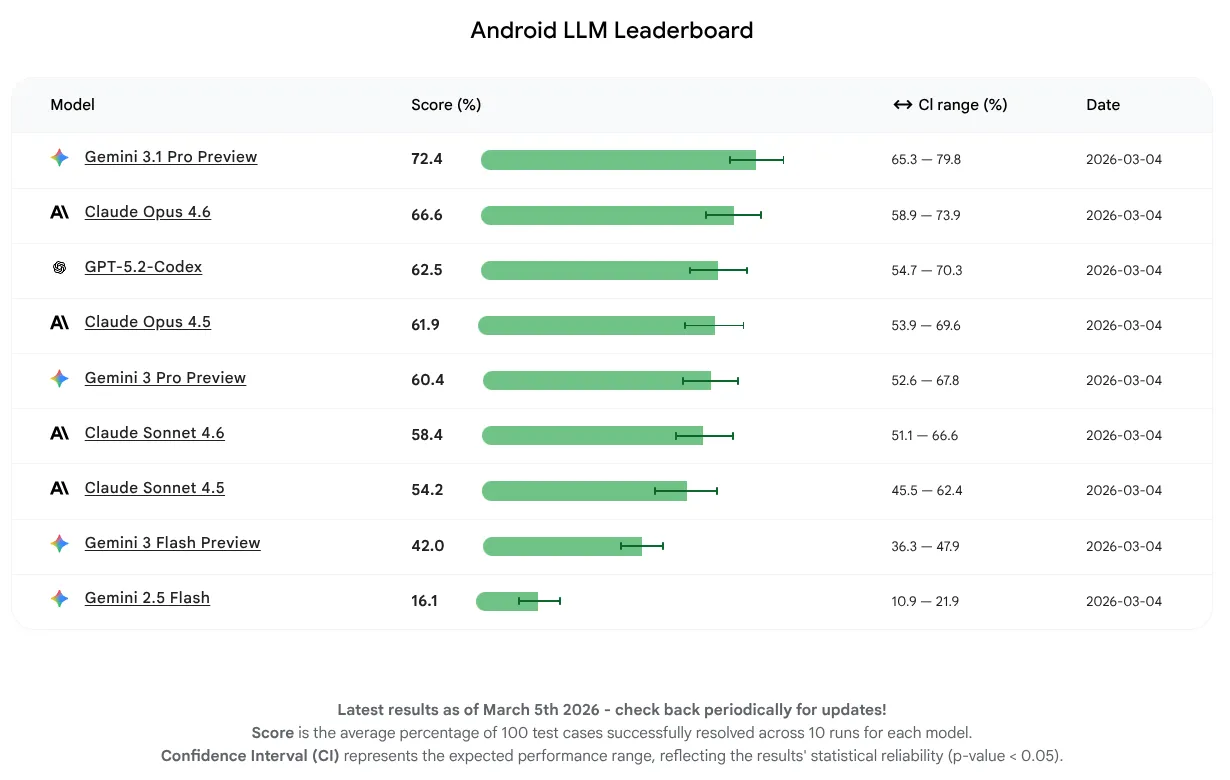
Bei dieser ersten Version wollten wir uns ausschließlich auf die Modellleistung konzentrieren und nicht auf die Verwendung von Agents oder Tools. Die Modelle konnten 16–72% der Aufgaben erfolgreich erledigen. Diese große Bandbreite zeigt, dass einige LLMs bereits eine starke Baseline für Android-Wissen haben, während andere noch Verbesserungspotenzial haben. Unabhängig davon, wie weit die Modelle jetzt sind, gehen wir davon aus, dass sie sich weiter verbessern werden, da wir die Entwickler von LLMs ermutigen, ihre Modelle für die Android-Entwicklung zu optimieren.
Das LLM mit der höchsten durchschnittlichen Punktzahl für diese erste Version ist Gemini 3.1 Pro, gefolgt von Claude Opus 4.6. Sie können alle Modelle, die wir für die KI-Unterstützung für Ihre Android-Projekte getestet haben, mit API-Schlüsseln in der neuesten stabilen Version von Android Studio ausprobieren.
Transparenz für Entwickler und LLM-Anbieter
Wir legen Wert auf einen offenen und transparenten Ansatz. Deshalb haben wir unsere Methodik, das Dataset und die Testumgebung auf GitHub öffentlich verfügbar gemacht.
Eine Herausforderung für jeden öffentlichen Benchmark ist das Risiko einer Datenkontamination, bei der Modelle während des Trainingsprozesses möglicherweise Bewertungsaufgaben gesehen haben. Wir haben Maßnahmen ergriffen, um sicherzustellen, dass unsere Ergebnisse auf echtem Denken und nicht auf Auswendiglernen oder Raten beruhen. Dazu gehören eine gründliche manuelle Überprüfung der Agentenpfade und die Integration eines Canary-Strings, um das Training zu verhindern.
Wir werden unsere Methodik weiterentwickeln, um die Integrität des Datensatzes zu wahren und gleichzeitig Verbesserungen für zukünftige Versionen des Benchmarks vorzunehmen, z. B. die Anzahl und Komplexität der Aufgaben zu erhöhen.
Wir sind gespannt, wie Android Bench langfristig die KI-Unterstützung verbessern kann. Wir möchten die Lücke zwischen Konzept und hochwertigem Code schließen. Wir schaffen die Grundlage für eine Zukunft, in der Sie alles, was Sie sich vorstellen, auf Android entwickeln können.
Verfasst von:
Weiterlesen
-

Produktneuheiten
Auf der Google I/O 2026 wurden 17 wichtige Neuerungen für Android-Entwickler angekündigt, die sich auf agentengesteuerte Produktivität, Compose First als UI-Standard sowie leistungsstarke Medien und adaptive Entwicklung für das wachsende Ökosystem konzentrieren.
Matthew McCullough • Lesezeit: 8 Minuten
-

Produktneuheiten
Wie heute bei The Android Show angekündigt wurde, entwickelt sich Android von einem Betriebssystem zu einem intelligenten System weiter. Das bietet Ihnen mehr Möglichkeiten, Nutzer mit Ihren Apps zu erreichen.
Matthew McCullough • Lesezeit: 4 Minuten
-

Produktneuheiten
Heute stellen wir Gemma 4 vor, unser neuestes hochmodernes offenes Modell, das für die Android-Entwicklung entwickelt wurde und komplexe Schlussfolgerungen und autonomes Aufrufen von Tools ermöglicht.
Matthew McCullough • Lesezeit: 2 Minuten
Auf dem Laufenden bleiben
Lassen Sie sich Woche für Woche die neuesten Informationen zur Android-Entwicklung zusenden.
