

我们希望让您能够更快、更轻松地构建高质量的 Android 应用,而我们帮助您提高工作效率的方式之一就是让您能够轻松使用 AI。我们知道,您希望 AI 能够真正理解 Android 平台的细微差别,因此我们一直在衡量 LLM 在执行 Android 开发任务时的表现。今天,我们发布了首个版本的 Android Bench,这是我们的官方 LLM 排行榜,用于评估其在 Android 开发方面的表现。
我们的目标是为模型创建者提供一个基准,以评估 LLM 在 Android 开发方面的能力。通过为高质量的 Android 开发建立清晰可靠的基准,我们帮助模型创建者发现差距并加快改进速度,从而让开发者能够更高效地工作,并有更多实用模型可供选择,以获取 AI 辅助。最终,这将有助于提高整个 Android 生态系统中应用的质量。
专为实际 Android 开发任务而设计
我们通过针对一系列常见的 Android 开发领域精心挑选任务集来创建基准。该基准由来自公共 GitHub Android 代码库的各种难度的实际挑战组成。场景包括解决 Android 版本之间的重大更改、特定于领域的任务(例如穿戴式设备上的网络连接)以及迁移到最新版本的 Jetpack Compose 等。
每次评估都会尝试让 LLM 修复任务中报告的问题,然后我们使用单元测试或插桩测试来验证修复结果。这种与模型无关的方法使我们能够衡量模型浏览复杂代码库、理解依赖项以及解决您每天遇到的各种问题的能力。
我们与包括 JetBrains 在内的多家 LLM 构建者验证了这种方法。
“衡量 AI 对 Android 的影响是一项巨大的挑战,因此很高兴看到这样一个合理且现实的框架。虽然我们积极进行自我基准评测,但 Android Bench 仍是一个独特且受欢迎的新增基准。这种方法正是 Android 开发者目前需要的严谨评估方式。”
- Kirill Smelov,JetBrains AI 集成主管。
首个 Android Bench 结果
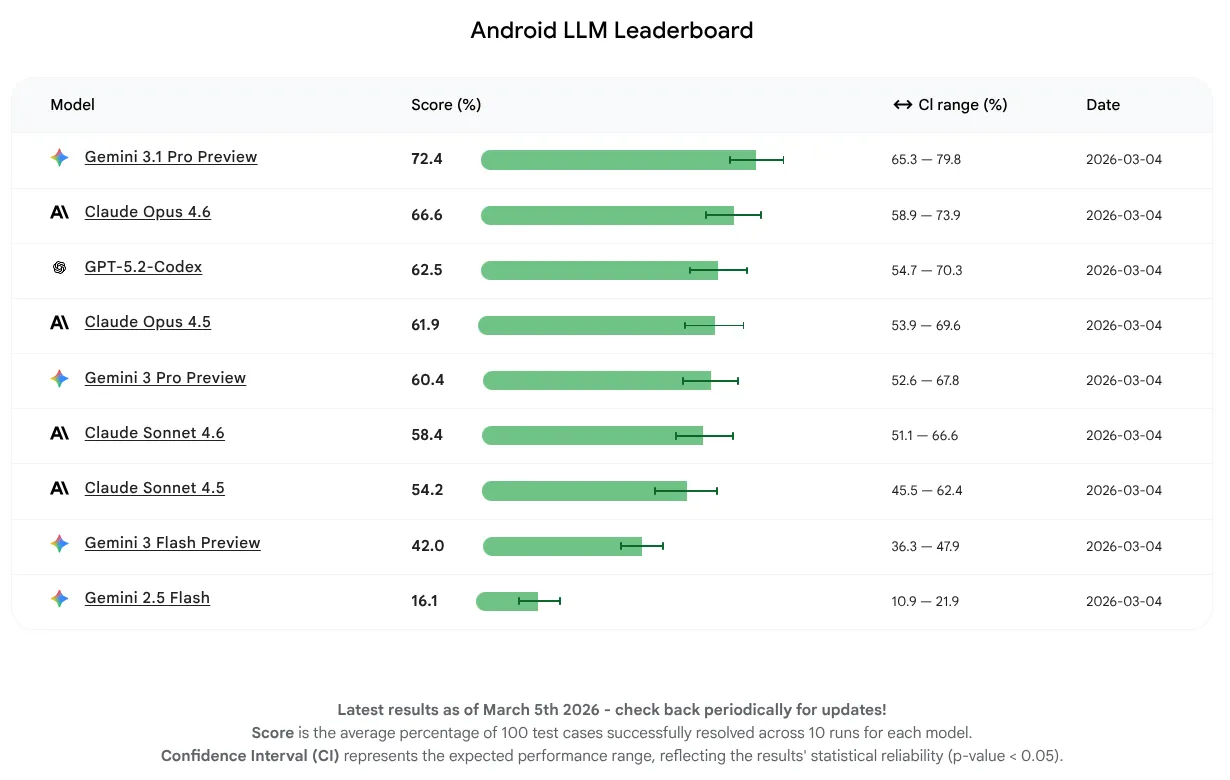
对于此初始版本,我们希望纯粹衡量模型性能,而不关注代理或工具使用情况。这些模型能够成功完成 16% 到 72% 的任务。这个范围很广,表明一些 LLM 已经具备强大的 Android 知识基础,而另一些 LLM 则有更大的改进空间。无论模型目前的水平如何,我们都预计它们会不断改进,因为我们鼓励 LLM 构建者针对 Android 开发增强其模型。
在此首个版本中,平均得分最高的 LLM 是 Gemini 3.1 Pro,紧随其后的是 Claude Opus 4.6。您可以在最新稳定版 Android Studio 中使用 API 密钥,尝试我们评估的所有模型,以获取 Android 项目的 AI 辅助。
为开发者和 LLM 构建者提供透明度
我们重视开放透明的方法,因此我们在 GitHub 上公开了 我们的方法、数据集和测试工具。
任何公共基准都面临的一个挑战是数据污染的风险,即模型可能在训练过程中看到评估任务。我们已采取措施确保我们的结果反映的是真正的推理,而不是记忆或猜测,包括对代理轨迹进行彻底的手动审核,或集成金丝雀字符串以阻止训练。
展望未来,我们将继续改进我们的方法,以保持数据集的完整性,同时也会针对基准的未来版本进行改进,例如增加任务的数量和复杂性。
我们期待 Android Bench 从长远来看如何改进 AI 辅助。我们的愿景是弥合概念与高质量代码之间的差距。我们正在为未来奠定基础,无论您想象什么,都可以在 Android 上构建出来。
-

 产品动态
产品动态Google I/O '26 大会针对 Android 开发者发布了 17 项重要公告,重点介绍了代理主导的效率、作为界面标准的 Compose First,以及针对不断扩大的生态系统的高性能媒体和自适应开发。
Matthew McCullough • 8 分钟阅读时间 -
 产品动态
产品动态在今日举办的 The Android Show 上,Google 宣布 Android 正从操作系统转型为智能系统,为您的应用创造更多互动契机。
Matthew McCullough • 4 分钟阅读时间 -
 产品动态
产品动态今天,我们推出了 Gemma 4,这是我们最新的前沿开源模型,具有复杂的推理和自主工具调用能力,可增强 Android 开发体验。
Matthew McCullough • 2 分钟阅读时间
每周获取最新的 Android 开发见解,直接发送到您的收件箱 每周。
