


Android 运行时 (ART) 团队将编译时间缩短了 18%,同时没有影响已编译的代码,也没有出现任何峰值内存回归。这项改进是我们 2025 年计划的一部分,旨在缩短编译时间,同时不影响内存用量或已编译代码的质量。
优化编译时速度对于 ART 至关重要。例如,在即时 (JIT) 编译时,它会直接影响应用的效率和整体设备性能。更快的编译速度可以缩短优化生效前的等待时间,从而带来更流畅、响应更快的用户体验。此外,对于 JIT 和预先 (AOT) 编译,编译时速度的提升意味着在编译过程中资源消耗的减少,这有利于延长电池续航时间和改善设备散热,尤其是在低端设备上。
其中一些编译时速度改进已在 2025 年 6 月的 Android 版本中推出,其余改进将在年底的 Android 版本中提供。此外,所有搭载 Android 12 及更高版本的 Android 用户都有资格通过 Mainline 更新获取这些改进。
优化优化编译器
优化编译器始终是一项权衡取舍的工作。您无法免费获得速度,必须放弃一些东西。我们为自己设定了一个非常明确且具有挑战性的目标:让编译器更快,但不能引入内存回归,最重要的是,不能降低其生成的代码的质量。如果编译器更快,但应用运行速度更慢,那我们就失败了。
我们愿意花费的唯一资源是我们自己的开发时间,以便深入挖掘、调查并找到符合这些严格标准的巧妙解决方案。接下来,让我们仔细了解一下我们如何努力寻找需要改进的方面,以及如何找到各种问题的正确解决方案。
寻找有价值的潜在优化
在开始优化指标之前,您必须能够衡量该指标。否则,您永远无法确定是否对其进行了改进。幸运的是,只要您采取一些预防措施,例如在更改前后使用同一设备进行测量,并确保不对设备进行热节流,编译时速度就会相当一致。最重要的是,我们还有确定性测量(例如编译器统计信息),可帮助我们了解幕后发生的情况。
由于我们为这些改进牺牲的资源是开发时间,因此我们希望能够尽可能快地进行迭代。这意味着我们选取了一些具有代表性的应用(包括第一方应用、第三方应用和 Android 操作系统本身)来制作解决方案原型。之后,我们通过广泛的手动和自动测试验证了最终实现是否值得。
借助这组精心挑选的 APK,我们会在本地触发手动编译,获取编译的配置文件,并使用 pprof 可视化我们花费时间的位置。
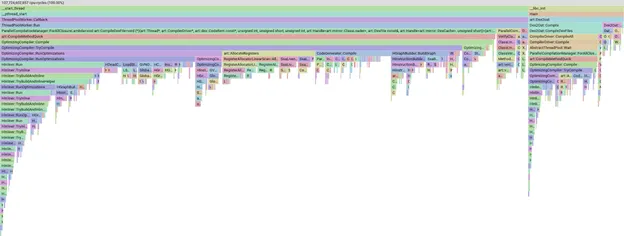
pprof 中配置文件的火焰图示例
pprof 工具非常强大,可让我们对数据进行切片、过滤和排序,以便查看哪些编译器阶段或方法花费的时间最多。我们不会详细介绍 pprof 本身;您只需知道,如果条形图越大,则表示编译花费的时间越多。
其中一个视图是“自下而上”视图,您可以在其中查看哪些方法花费的时间最多。在下图中,我们可以看到一个名为 Kill 的方法,占编译时间的 1% 以上。博文稍后还将讨论其他一些热门方法。
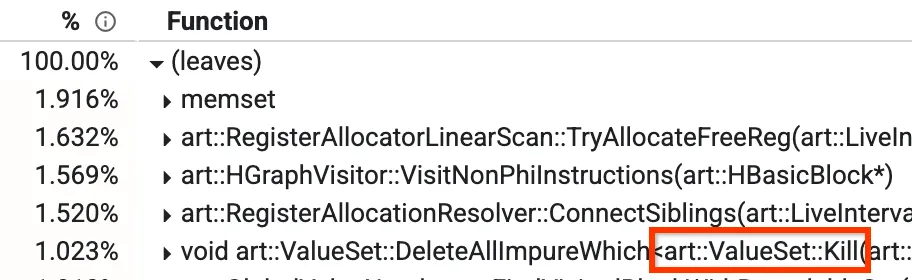
配置文件的自下而上视图
在我们的优化编译器中,有一个名为全局值编号 (GVN) 的阶段。您不必担心它作为一个整体的作用,但相关部分是了解它有一个名为 `Kill` 的方法,该方法会根据过滤器删除一些节点。这非常耗时,因为它必须遍历所有节点并逐个检查。我们注意到,在某些情况下,无论我们当时有哪些活跃节点,我们都事先知道检查结果将为 false。在这些情况下,我们可以完全跳过迭代,将其从 1.023% 降至约 0.3%,并将 GVN 的运行时提升约 15%。
实现有价值的优化
我们介绍了如何衡量以及如何检测花费时间的位置,但这仅仅是开始。下一步是如何优化编译花费的时间。
通常,在上述 `Kill` 这样的情况下,我们会查看如何遍历节点,并通过并行执行操作或改进算法本身等方式更快地完成遍历。事实上,我们一开始就是这样尝试的,只有在找不到任何可做的事情时,我们才突然意识到,解决方案是(在某些情况下)根本不进行迭代!在进行此类优化时,很容易只见树木不见森林。
在其他情况下,我们使用了多种不同的技术,包括:
- 使用启发法来确定优化是否无法产生有价值的结果,因此可以跳过
- 使用额外的数据结构来缓存计算的数据
- 更改当前数据结构以提高速度
- 在某些情况下延迟计算结果以避免循环
- 使用正确的抽象 - 不必要的功能可能会降低代码速度
- 避免在多次加载中追踪常用指针
我们如何知道优化是否值得追求?
这就是巧妙之处,您不知道。在检测到某个区域消耗大量编译时间并投入开发时间尝试改进后,有时您无法找到解决方案。也许没有什么可做的,实现需要花费太长时间,会显著回归另一个指标,增加代码库复杂性等。对于您在本博文中看到的每一个成功的优化,请注意,还有无数其他优化未能实现。
如果您遇到类似情况,请尝试估算通过尽可能少的工作量可以改进指标的程度。这意味着,按以下顺序:
- 使用您已收集的指标或仅凭直觉进行估算
- 使用快速而粗糙的原型进行估算
- 实现解决方案。
别忘了考虑估算解决方案的缺点。例如,如果您要依赖额外的数据结构,您愿意使用多少内存?
深入了解
事不宜迟,让我们来看看我们实现的一些更改。
我们实现了一项更改,以优化名为 FindReferenceInfoOf 的方法。此方法正在对向量进行线性搜索以查找条目。我们更新了该数据结构,使其按指令的 ID 进行索引,以便 FindReferenceInfoOf 为 O(1) 而不是 O(n)。此外,我们还预先分配了向量以避免调整大小。我们略微增加了内存,因为我们必须添加一个额外的字段来统计我们在向量中插入的条目数,但这是一个很小的牺牲,因为峰值内存没有增加。这使我们的 LoadStoreAnalysis 阶段加快了 34-66%,从而使编译时间缩短了约 0.5-1.8%。
我们有一个 HashSet 的自定义实现,在多个位置使用。创建此数据结构花费了大量时间,我们找到了原因。多年前,此数据结构仅在少数使用非常大的 HashSet 的位置使用,并且经过调整以针对该情况进行优化。但是,如今,它在相反的方向上使用,只有少数条目,并且生命周期很短。这意味着我们浪费了周期来创建这个巨大的 HashSet,但我们只使用了几个条目就将其丢弃了。通过此更改,我们缩短了约 1.3-2% 的编译时间。此外,由于我们不再使用以前那么大的数据结构,内存用量减少了约 0.5-1%。
我们通过按引用将数据结构传递给 lambda 来避免复制数据结构,从而缩短了约 0.5-1% 的编译时间。这是原始审核中遗漏的内容,并且在我们的代码库中存在多年。多亏了查看 pprof 中的配置文件,我们才注意到这些方法正在创建和销毁大量数据结构,这促使我们对其进行调查和优化。
我们通过缓存计算的值来加快写入已编译输出的阶段,这使总编译时间缩短了约 1.3-2.8%。遗憾的是,额外的簿记工作太多,我们的自动测试提醒我们出现了内存回归。后来,我们再次查看了同一代码,并实现了一个新版本,该版本不仅解决了内存回归问题,还进一步缩短了约 0.5-1.8% 的编译时间!在第二次更改中,我们必须重构并重新构想此阶段的工作方式,以便摆脱其中一个数据结构。
在我们的优化编译器中,有一个阶段会内联函数调用,以获得更好的性能。为了选择要内联的方法,我们在进行任何计算之前使用启发法,并在完成工作后但在最终确定内联之前进行最终检查。如果其中任何一个检测到内联不值得(例如,会添加太多新指令),那么我们就不会内联方法调用。
我们将两个检查从“最终检查”类别移到了“启发法”类别,以便在进行任何耗时的计算之前估算内联是否会成功。由于这只是估算,因此并不完美,但我们验证了我们的新启发法涵盖了之前内联的 99.9%,而不会影响性能。其中一个新启发法与所需的 DEX 寄存器(提升约 0.2-1.3%)有关,另一个与 指令数(提升约 2%)有关。
我们有一个 BitVector 的自定义实现,在多个位置使用。对于某些固定大小的位向量,我们将可调整大小的 BitVector 类替换为更简单的 BitVectorView。这消除了某些间接寻址和运行时范围检查,并加快了位向量对象的构建速度。
此外,BitVectorView 类是基于底层存储类型进行模板化的(而不是像旧的 BitVector 那样始终使用 uint32_t)。这允许某些操作(例如 Union())在 64 位平台上一起处理两倍的位数。在编译 Android 操作系统时,受影响函数的样本总共减少了 1% 以上。这是通过多次更改 [1, 2, 3, 4, 5, 6] 完成的
如果我们详细讨论所有优化,那我们今天就没完没了了!如果您对更多优化感兴趣,请查看我们实现的其他一些更改:
- 添加簿记以将编译时间缩短约 0.6-1.6%。
- 尽可能延迟计算数据以避免循环。
- 重构我们的代码,以便在不使用预计算工作时跳过该工作。
- 当分配器可以从其他位置轻松获取时,避免一些依赖加载链。
- 另一个添加检查以避免不必要的工作的示例。
- 避免频繁分支在寄存器分配器中寄存器类型(核心/FP)。
- 确保在编译时初始化某些数组。不要依赖 clang 来完成此操作。
- 清理一些循环。使用 clang 可以更好地优化的范围循环,因为它不需要因循环副作用而重新加载容器的内部指针。避免通过内联的 `InputAt(.)` 为每个输入在循环中调用虚拟函数 `HInstruction::GetInputRecords()`。
- 通过利用编译器优化来避免访问者模式的 Accept() 函数。
总结
我们致力于提升 ART 的编译时速度,并取得了显著的改进,使 Android 更加流畅高效,同时也有助于延长电池续航时间和改善设备散热。通过认真识别和实现优化,我们证明了在不影响内存用量或代码质量的情况下,可以显著缩短编译时间。
我们的历程包括使用 pprof 等工具进行分析,愿意进行迭代,有时甚至放弃不太有成效的方法。ART 团队的共同努力不仅显著缩短了编译时间,还为未来的发展奠定了基础。
所有这些改进都包含在 2025 年年底的 Android 更新中,并且通过 Mainline 更新适用于 Android 12 及更高版本。我们希望通过深入了解我们的优化流程,为您提供有关编译器工程的复杂性和回报的宝贵见解!
-

 产品动态
产品动态今年 3 月,我们推出了 Android Bench,这是我们针对实际 Android 开发任务的大语言模型排行榜。此后,我们根据您的反馈改进了基准,包括评估开放权重模型,以及在排行榜中添加成本和效率维度。
Zoe Lopez-Latorre • 3 分钟阅读时间 -

 产品动态
产品动态在 Google Play,我们致力于为用户打造卓越的体验,同时确保开发者拥有取得成功所需的工具和灵活的应变空间。
Paul Feng • 3 分钟阅读时间 -

 产品动态
产品动态去年,我们推出了 Android 开发者验证功能,以加强生态系统安全性,并阻止恶意方匿名发布有害应用。
Matthew Forsythe • 2 分钟阅读时间
每周通过电子邮件接收最新的 Android 开发洞见 每周。
