


El equipo de Android Runtime (ART) redujo el tiempo de compilación en un 18% sin comprometer el código compilado ni ninguna regresión máxima de memoria. Esta mejora formó parte de nuestra iniciativa de 2025 para mejorar el tiempo de compilación sin sacrificar el uso de la memoria ni la calidad del código compilado.
Optimizar la velocidad de compilación es fundamental para ART. Por ejemplo, cuando se compila justo a tiempo (JIT), afecta directamente la eficiencia de las aplicaciones y el rendimiento general del dispositivo. Las compilaciones más rápidas reducen el tiempo antes de que se activen las optimizaciones, lo que genera una experiencia del usuario más fluida y con mayor capacidad de respuesta. Además, tanto para JIT como para la compilación anticipada (AOT), las mejoras en la velocidad de compilación se traducen en un menor consumo de recursos durante el proceso de compilación, lo que beneficia la duración de la batería y la temperatura del dispositivo, en especial en los dispositivos de gama baja.
Algunas de estas mejoras en la velocidad de compilación se lanzaron en la versión de Android de junio de 2025, y el resto estará disponible en la versión de Android de fin de año. Además, todos los usuarios de Android que tengan la versión 12 y versiones posteriores pueden recibir estas mejoras a través de las actualizaciones de Mainline.
Cómo optimizar el compilador de optimización
Optimizar un compilador siempre es un juego de compensaciones. No puedes obtener velocidad gratis; tienes que renunciar a algo. Nos fijamos un objetivo muy claro y desafiante: hacer que el compilador sea más rápido, pero sin introducir regresiones de memoria y, lo que es fundamental, sin degradar la calidad del código que produce. Si el compilador es más rápido, pero las apps se ejecutan más lento, fallamos.
El único recurso que estábamos dispuestos a invertir era nuestro propio tiempo de desarrollo para investigar y encontrar soluciones inteligentes que cumplieran con estos criterios estrictos. Analicemos más de cerca cómo trabajamos para encontrar áreas de mejora, así como las soluciones adecuadas para los diversos problemas.
Cómo encontrar posibles optimizaciones que valgan la pena
Antes de comenzar a optimizar una métrica, debes poder medirla. De lo contrario, nunca podrás asegurarte de si la mejoraste o no. Por suerte para nosotros, la velocidad de compilación es bastante coherente, siempre y cuando tomes algunas precauciones, como usar el mismo dispositivo que usas para medir antes y después de un cambio, y asegurarte de no limitar la temperatura del dispositivo. Además, también tenemos mediciones deterministas, como las estadísticas del compilador, que nos ayudan a comprender lo que sucede en segundo plano.
Como el recurso que sacrificamos para estas mejoras fue nuestro tiempo de desarrollo, queríamos poder iterar lo más rápido posible. Esto significó que tomamos un puñado de apps representativas (una combinación de apps propias, apps de terceros y el sistema operativo Android) para crear prototipos de soluciones. Más adelante, verificamos que la implementación final valiera la pena con pruebas manuales y automatizadas de forma generalizada.
Con ese conjunto de APKs seleccionados, activaríamos una compilación manual de forma local, obtendríamos un perfil de la compilación y usaríamos pprof para visualizar dónde invertimos nuestro tiempo.
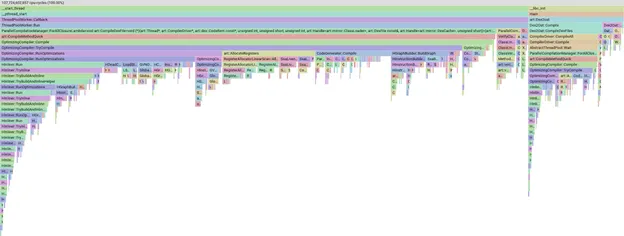
Ejemplo de un gráfico tipo llama de un perfil en pprof
La herramienta pprof es muy potente y nos permite segmentar, filtrar y ordenar los datos para ver, por ejemplo, qué fases o métodos del compilador tardan más tiempo. No entraremos en detalles sobre pprof en sí; solo debes saber que, si la barra es más grande, significa que tardó más tiempo en la compilación.
Una de estas vistas es la "de abajo hacia arriba", en la que puedes ver qué métodos tardan más tiempo. En la siguiente imagen, podemos ver un método llamado Kill, que representa más del 1% del tiempo de compilación. Algunos de los otros métodos principales también se analizarán más adelante en la entrada de blog.
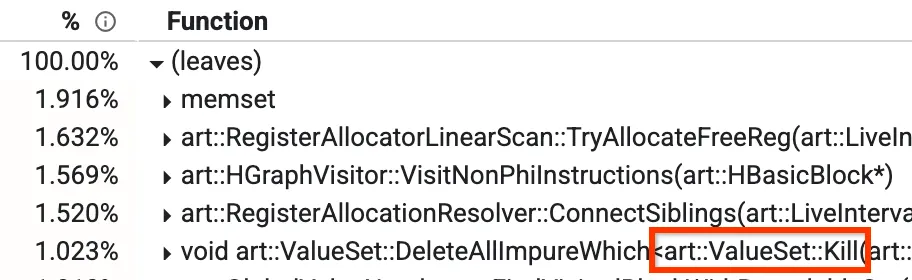
Vista de abajo hacia arriba de un perfil
En nuestro compilador de optimización, hay una fase llamada Global Value Numbering (GVN). No tienes que preocuparte por lo que hace en su totalidad, pero la parte relevante es saber que tiene un método llamado `Kill` que borrará algunos nodos según un filtro. Esto lleva mucho tiempo, ya que debe iterar a través de todos los nodos y verificarlos uno por uno. Notamos que hay algunos casos en los que sabemos de antemano que la verificación será falsa, sin importar los nodos que tengamos activos en ese momento. En estos casos, podemos omitir la iteración por completo, lo que la reduce de 1.023% a aproximadamente 0.3% y mejora el tiempo de ejecución de GVN en aproximadamente un 15%.
Cómo implementar optimizaciones que valgan la pena
Ya explicamos cómo medir y detectar dónde se invierte el tiempo, pero esto es solo el comienzo. El siguiente paso es cómo optimizar el tiempo que se dedica a la compilación.
Por lo general, en un caso como el de `Kill` anterior, analizamos cómo iteramos a través de los nodos y lo hacemos más rápido, por ejemplo, haciendo cosas en paralelo o mejorando el algoritmo en sí. De hecho, eso es lo que intentamos al principio, y solo cuando no pudimos encontrar nada que hacer, tuvimos un momento de "Espera un minuto…" y vimos que la solución era (en algunos casos) no iterar en absoluto. Cuando se realizan este tipo de optimizaciones, es fácil perderse en los detalles.
En otros casos, usamos varias técnicas diferentes, incluidas las siguientes:
- Usar heurísticas para decidir si una optimización no producirá resultados que valgan la pena y, por lo tanto, se puede omitir
- Usar estructuras de datos adicionales para almacenar en caché los datos calculados
- Cambiar las estructuras de datos actuales para obtener un aumento de velocidad
- Calcular los resultados de forma diferida para evitar ciclos en algunos casos
- Usar la abstracción correcta: las funciones innecesarias pueden ralentizar el código
- Evitar perseguir un puntero de uso frecuente a través de muchas cargas
¿Cómo sabemos si vale la pena realizar las optimizaciones?
Esa es la parte interesante, no lo sabes. Después de detectar que un área consume mucho tiempo de compilación y después de dedicar tiempo de desarrollo para intentar mejorarla, a veces no puedes encontrar una solución. Tal vez no haya nada que hacer, tardará demasiado en implementarse, regresará otra métrica de manera significativa, aumentará la complejidad de la base de código, etcétera. Por cada optimización exitosa que puedes ver en esta entrada de blog, debes saber que hay muchas otras que no se concretaron.
Si te encuentras en una situación similar, intenta estimar cuánto mejorarás la métrica haciendo la menor cantidad de trabajo posible. Esto significa, en orden:
- Estimar con una métrica que ya recopilaste o simplemente una corazonada
- Estimar con un prototipo rápido y sucio
- Implementar una solución
No olvides considerar la estimación de los inconvenientes de tu solución. Por ejemplo, si vas a depender de estructuras de datos adicionales, ¿cuánta memoria estás dispuesto a usar?
Sigue explorando
Sin más preámbulos, veamos algunos de los cambios que implementamos.
Implementamos un cambio para optimizar un método llamado FindReferenceInfoOf. Este método realizaba una búsqueda lineal de un vector para encontrar una entrada. Actualizamos esa estructura de datos para que se indexe por el ID de la instrucción, de modo que FindReferenceInfoOf sea O(1) en lugar de O(n). Además, preasignamos el vector para evitar cambiar su tamaño. Aumentamos ligeramente la memoria, ya que tuvimos que agregar un campo adicional que contaba cuántas entradas insertamos en el vector, pero fue un pequeño sacrificio, ya que la memoria máxima no aumentó. Esto aceleró nuestra fase de LoadStoreAnalysis en un 34 a 66%, lo que a su vez genera una mejora de aproximadamente 0.5 a 1.8% en el tiempo de compilación.
Tenemos una implementación personalizada de HashSet que usamos en varios lugares. La creación de esta estructura de datos llevaba una cantidad considerable de tiempo, y descubrimos por qué. Hace muchos años, esta estructura de datos se usaba solo en algunos lugares que usaban HashSets muy grandes y se modificó para optimizarla. Sin embargo, en la actualidad, se usaba en la dirección opuesta con solo algunas entradas y con una vida útil corta. Esto significaba que estábamos desperdiciando ciclos creando este enorme HashSet, pero solo lo usamos para algunas entradas antes de descartarlo. Con este cambio, mejoramos aproximadamente un 1.3 a 2% del tiempo de compilación. Como beneficio adicional, el uso de memoria disminuyó en aproximadamente un 0.5 a 1%, ya que no usábamos estructuras de datos tan grandes como antes.
Mejoramos aproximadamente un 0.5 a 1% del tiempo de compilación pasando estructuras de datos por referencia a la expresión lambda para evitar copiarlas. Esto fue algo que se omitió en la revisión original y permaneció en nuestra base de código durante años. Gracias a que analizamos los perfiles en pprof, notamos que estos métodos creaban y destruían muchas estructuras de datos, lo que nos llevó a investigarlos y optimizarlos.
Aceleramos la fase que escribe el resultado compilado almacenando en caché los valores calculados, lo que se tradujo en una mejora de aproximadamente 1.3 a 2.8% del tiempo total de compilación. Lamentablemente, la contabilidad adicional era demasiado, y nuestras pruebas automatizadas nos alertaron sobre la regresión de memoria. Más adelante, volvimos a analizar el mismo código e implementamos una versión nueva que no solo se ocupó de la regresión de memoria, sino que también mejoró el tiempo de compilación en aproximadamente un 0.5 a 1.8%. En este segundo cambio, tuvimos que refactorizar y volver a imaginar cómo debería funcionar esta fase para deshacernos de una de las dos estructuras de datos.
Tenemos una fase en nuestro compilador de optimización que inserta llamadas de función para obtener un mejor rendimiento. Para elegir qué métodos insertar, usamos heurísticas antes de realizar cualquier cálculo y verificaciones finales después de realizar el trabajo, pero justo antes de finalizar la inserción. Si alguno de ellos detecta que la inserción no vale la pena (por ejemplo, se agregarían demasiadas instrucciones nuevas), no insertamos la llamada al método.
Movimos dos verificaciones de la categoría "verificaciones finales" a la categoría "heurística" para estimar si una inserción tendrá éxito o no antes de realizar cualquier cálculo que requiera mucho tiempo. Como se trata de una estimación, no es perfecta, pero verificamos que nuestras nuevas heurísticas cubran el 99.9% de lo que se insertó antes sin afectar el rendimiento. Una de estas nuevas heurísticas se refería a los registros DEX necesarios (mejora de aproximadamente 0.2 a 1.3%), y la otra, a la cantidad de instrucciones (mejora de aproximadamente 2%).
Tenemos una implementación personalizada de un BitVector que usamos en varios lugares. Reemplazamos la clase BitVector redimensionable por un BitVectorView más simple para ciertos vectores de bits de tamaño fijo. Esto elimina algunas indirecciones y verificaciones de rango en tiempo de ejecución, y acelera la construcción de los objetos de vectores de bits.
Además, la clase BitVectorView se creó con plantillas en el tipo de almacenamiento subyacente (en lugar de usar siempre uint32_t como el BitVector anterior). Esto permite que algunas operaciones, por ejemplo, Union(), procesen el doble de bits juntos en plataformas de 64 bits. Las muestras de las funciones afectadas se redujeron en más del 1% en total cuando se compiló el SO Android. Esto se hizo en varios cambios [1, 2, 3, 4, 5, 6]
Si habláramos en detalle sobre todas las optimizaciones, estaríamos aquí todo el día. Si te interesan algunas optimizaciones más, consulta otros cambios que implementamos:
- Agrega contabilidad para mejorar los tiempos de compilación en aproximadamente un 0.6 a 1.6%.
- Calcula los datos de forma diferida para evitar ciclos, si es posible.
- Refactoriza nuestro código para omitir el trabajo de precomputación cuando no se use.
- Evita algunas cadenas de carga dependientes cuando el asignador se pueda obtener fácilmente de otros lugares.
- Otro caso de agregar una verificación para evitar el trabajo innecesario.
- Evita la bifurcación frecuente en el tipo de registro (núcleo/FP) en el asignador de registros.
- Asegúrate de que algunos arrays se inicialicen en el tiempo de compilación. No dependas de clang para hacerlo.
- Limpia algunos bucles. Usa bucles de rango que clang pueda optimizar mejor porque no necesita volver a cargar los punteros internos del contenedor debido a los efectos secundarios del bucle. Evita llamar a la función virtual `HInstruction::GetInputRecords()` en el bucle a través de `InputAt(.)` insertado para cada entrada.
- Evita las funciones Accept() para el patrón de visitante aprovechando una optimización del compilador.
Conclusión
Nuestra dedicación a mejorar la velocidad de compilación de ART generó mejoras significativas, lo que hizo que Android sea más fluido y eficiente, y también contribuyó a mejorar la duración de la batería y la temperatura del dispositivo. Al identificar e implementar optimizaciones de manera diligente, demostramos que es posible obtener ganancias sustanciales en el tiempo de compilación sin comprometer el uso de la memoria ni la calidad del código.
Nuestro recorrido incluyó la creación de perfiles con herramientas como pprof, la disposición a iterar y, a veces, incluso abandonar caminos menos fructíferos. Los esfuerzos colectivos del equipo de ART no solo redujeron el tiempo de compilación en un porcentaje notable, sino que también sentaron las bases para futuros avances.
Todas estas mejoras están disponibles en la actualización de Android de fin de año de 2025 y para Android 12 y versiones posteriores a través de las actualizaciones de Mainline. Esperamos que este análisis en profundidad de nuestro proceso de optimización proporcione información valiosa sobre las complejidades y las recompensas de la ingeniería de compiladores.
-

 Novedades sobre productos
Novedades sobre productosEn marzo, presentamos Android Bench, nuestra clasificación de LLMs para tareas de desarrollo de Android del mundo real. Desde entonces, mejoramos la comparativa en función de tus comentarios, incluida la evaluación de modelos de peso abierto y la adición de dimensiones de costo y eficiencia a la clasificación.
Zoe Lopez-Latorre • Lectura de 3 min -

 Novedades sobre productos
Novedades sobre productosEn Google Play, nos comprometemos a ofrecer la mejor experiencia posible a los usuarios, a la vez que garantizamos que los desarrolladores tengan las herramientas y la adaptabilidad necesarias para triunfar.
Paul Feng • Lectura de 3 min -

 Novedades sobre productos
Novedades sobre productosEl año pasado, presentamos la verificación de desarrolladores de Android para fortalecer la seguridad del ecosistema y evitar que los agentes maliciosos se oculten detrás del anonimato para lanzar apps dañinas.
Matthew Forsythe • Lectura de 2 min
Recibe la información más reciente sobre el desarrollo de Android en tu bandeja de entrada todas las semanas.
