
Wiadomości o usługach
Jak automatyczna optymalizacja promptów zwiększa jakość interfejsu GenAI Prompt API w ML Kit
Czas czytania: 3 minuty
Automatyczna optymalizacja promptów (APO)
Aby jeszcze bardziej ułatwić wdrażanie w środowisku produkcyjnym przypadków użycia interfejsu ML Kit Prompt API, wprowadzamy automatyczną optymalizację promptów (APO) kierowaną na modele na urządzeniu w Vertex AI. Automatyczna optymalizacja promptów to narzędzie, które pomaga automatycznie znajdować optymalne prompty do Twoich przypadków użycia.
Era AI na urządzeniu nie jest już melodią przyszłości, ale rzeczywistością. Wraz z wprowadzeniem Gemini Nano w wersji 3 oddajemy w ręce użytkowników niespotykane dotąd możliwości rozumienia języka i rozpoznawania multimodalnego. Dzięki rodzinie modeli Gemini Nano mamy szeroki zakres obsługiwanych urządzeń w ekosystemie Androida. Dla deweloperów tworzących aplikacje nowej generacji dostęp do zaawansowanego modelu to dopiero pierwszy krok. Prawdziwym wyzwaniem jest dostosowanie: jak dostosować model podstawowy do poziomu eksperckiego w konkretnym przypadku użycia bez naruszania ograniczeń sprzętu mobilnego?
W przypadku serwerów większe LLM są zwykle bardzo wydajne i wymagają mniejszego dostosowania do domeny. Nawet w takich przypadkach można zastosować bardziej zaawansowane opcje, takie jak dostrajanie LoRA (adaptacja o niskim rzędzie). Wyjątkowa architektura Androida AICore traktuje jednak priorytetowo wspólny, oszczędny pod względem pamięci model systemowy. Oznacza to, że wdrażanie niestandardowych adapterów LoRA w przypadku każdej aplikacji wiąże się z wyzwaniami związanymi z tymi współdzielonymi usługami systemowymi.
Istnieje jednak alternatywna ścieżka, która może mieć równie duży wpływ. Dzięki wykorzystaniu automatycznej optymalizacji promptów (APO) w Vertex AI deweloperzy mogą osiągnąć jakość zbliżoną do dostrajania, a jednocześnie bezproblemowo pracować w natywnym środowisku wykonawczym Androida. Dzięki skupieniu się na lepszych instrukcjach systemowych APO umożliwia programistom dostosowywanie zachowania modelu z większą niezawodnością i skalowalnością niż tradycyjne rozwiązania do dostrajania.
Uwaga: Gemini Nano V3 to zoptymalizowana pod kątem jakości wersja uznanego modelu Gemma 3N. Wszelkie optymalizacje promptów wprowadzone w modelu open source Gemma 3N będą miały zastosowanie również w przypadku Gemini Nano V3. Na obsługiwanych urządzeniach interfejsy API ML Kit GenAI wykorzystują model nano-v3, aby zmaksymalizować jakość dla programistów na Androida.
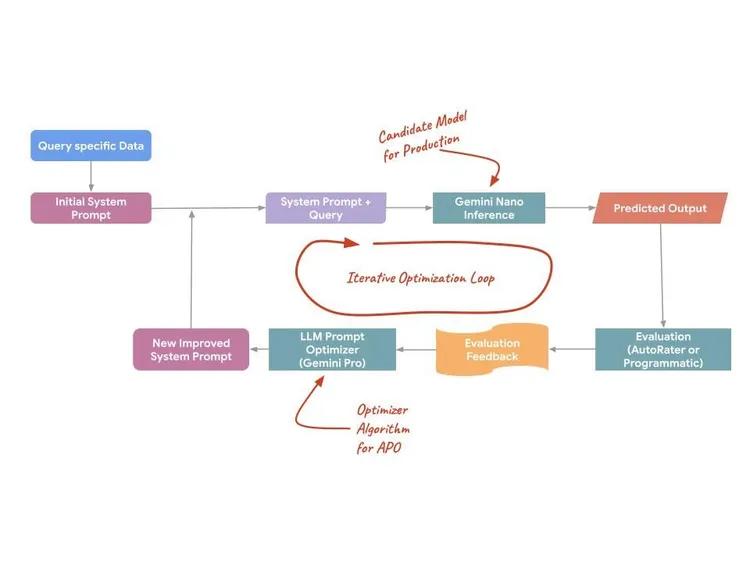
APO traktuje prompt nie jako statyczny tekst, ale jako programowalną platformę, którą można optymalizować. Wykorzystuje modele po stronie serwera (takie jak Gemini Pro i Flash), aby proponować prompty, oceniać ich warianty i znajdować optymalny prompt do konkretnego zadania. Aby zmaksymalizować skuteczność, ten proces wykorzystuje 3 mechanizmy techniczne:
- Automatyczna analiza błędów: APO analizuje wzorce błędów w danych treningowych, aby automatycznie identyfikować konkretne słabe punkty początkowego prompta.
- Semantic Instruction Distillation: analizuje ogromne zbiory przykładów szkoleniowych, aby wydobyć „prawdziwe intencje” zadania, i tworzy instrukcje, które dokładniej odzwierciedlają rzeczywisty rozkład danych.
- Równoległe testowanie kandydatów: zamiast testować po jednym pomyśle naraz, APO generuje i testuje równolegle wiele kandydatów na prompty, aby znaleźć globalne maksimum jakości.
Dlaczego APO może być przydatne w dostrajaniu jakości
Często błędnie uważa się, że dostrajanie zawsze daje lepszą jakość niż promptowanie. W przypadku nowoczesnych modeli podstawowych, takich jak Gemini Nano v3, inżynieria promptów może być skuteczna sama w sobie:
- Zachowanie ogólnych możliwości: dostrajanie ( PEFT/LoRA) wymusza na modelu nadmierne indeksowanie wagi w określonej dystrybucji danych. Często prowadzi to do „katastrofalnego zapominania”, czyli sytuacji, w której model lepiej radzi sobie z określoną składnią, ale gorzej z ogólną logiką i bezpieczeństwem. APO nie zmienia wag, zachowując możliwości modelu podstawowego.
- Wykonywanie instrukcji i odkrywanie strategii: model Gemini Nano v3 został starannie wytrenowany pod kątem wykonywania złożonych instrukcji systemowych. APO wykorzystuje to, znajdując dokładną strukturę instrukcji, która odblokowuje ukryte możliwości modelu. Często odkrywa strategie, które mogą być trudne do znalezienia dla inżynierów.
Aby potwierdzić skuteczność tego podejścia, przeprowadziliśmy ocenę APO w różnych zadaniach produkcyjnych. Nasze testy wykazały stały wzrost dokładności o 5–8% w różnych przypadkach użycia.W przypadku wielu wdrożonych funkcji na urządzeniu APO zapewniło znaczną poprawę jakości.
| Use Case | Typ zadania | Opis zadania | Wskaźnik | Ulepszenie APO |
| Klasyfikacja tematyczna | Klasyfikacja tekstu | Klasyfikowanie artykułów informacyjnych według tematów, takich jak finanse, sport itp. | Dokładność | +5% |
| Klasyfikacja intencji | Klasyfikacja tekstu | Klasyfikowanie zapytań do obsługi klienta według intencji | Dokładność | +8,0% |
| Tłumaczenie stron internetowych | Tłumaczenie tekstu | Tłumaczenie strony internetowej z języka angielskiego na język lokalny | BLEU | +8,57% |
Płynny, kompleksowy przepływ pracy programisty
Często błędnie uważa się, że dostrajanie zawsze daje lepszą jakość niż promptowanie. W przypadku nowoczesnych modeli podstawowych, takich jak Gemini Nano v3, inżynieria promptów może być skuteczna sama w sobie:
- Zachowanie ogólnych możliwości: dostrajanie ( PEFT/LoRA) wymusza na modelu nadmierne indeksowanie wagi w określonej dystrybucji danych. Często prowadzi to do „katastrofalnego zapominania”, czyli sytuacji, w której model lepiej radzi sobie z określoną składnią, ale gorzej z ogólną logiką i bezpieczeństwem. APO nie zmienia wag, zachowując możliwości modelu podstawowego.
- Wykonywanie instrukcji i odkrywanie strategii: model Gemini Nano v3 został starannie wytrenowany pod kątem wykonywania złożonych instrukcji systemowych. APO wykorzystuje to, znajdując dokładną strukturę instrukcji, która odblokowuje ukryte możliwości modelu. Często odkrywa strategie, które mogą być trudne do znalezienia dla inżynierów.
Aby potwierdzić skuteczność tego podejścia, przeprowadziliśmy ocenę APO w różnych zadaniach produkcyjnych. Nasze testy wykazały stały wzrost dokładności o 5–8% w różnych przypadkach użycia.W przypadku wielu wdrożonych funkcji na urządzeniu APO zapewniło znaczną poprawę jakości.
Podsumowanie
Wprowadzenie automatycznej optymalizacji promptów (APO) to punkt zwrotny w rozwoju generatywnej AI na urządzeniach. Wypełniając lukę między modelami podstawowymi a wydajnością na poziomie eksperckim, dajemy deweloperom narzędzia do tworzenia bardziej niezawodnych aplikacji mobilnych. Niezależnie od tego, czy dopiero zaczynasz korzystać z optymalizacji bez przykładów, czy skalujesz ją do produkcji za pomocą opartego na danych ulepszania, ścieżka do wysokiej jakości inteligencji na urządzeniu jest teraz bardziej przejrzysta. Wdrażaj już dziś przypadki użycia na urządzeniu w wersji produkcyjnej za pomocą interfejsu Prompt API w pakiecie ML Kit i automatycznej optymalizacji promptów w Vertex AI.
Przydatne linki:
Autor:



Czytaj dalej
-



Wiadomości o usługach
W Google dokładamy wszelkich starań, aby udostępniać najbardziej zaawansowane modele AI bezpośrednio na urządzeniach z Androidem, które masz w kieszeni. Z przyjemnością ogłaszamy wprowadzenie naszego najnowocześniejszego otwartego modelu: Gemma 4.
Caren Chang, David Chou • Czas czytania: 3 minuty
-

Wiadomości o usługach
AI ułatwia tworzenie spersonalizowanych aplikacji, które przekształcają treści w odpowiedni format dla użytkowników. Wcześniej umożliwiliśmy deweloperom integrację z Gemini Nano za pomocą interfejsów ML Kit GenAI API dostosowanych do konkretnych zastosowań, takich jak podsumowywanie i opisywanie obrazów.
Caren Chang, Chengji Yan, Penny Li • Czas czytania: 2 minuty
-


Wiadomości o usługach
Zależy nam na tym, aby użytkownicy Google Play mieli jak najlepsze wrażenia, a deweloperzy dysponowali narzędziami i możliwościami dostosowania, które pozwolą im osiągnąć sukces.
Paul Feng • Czas czytania: 3 minuty
Bądź na bieżąco
Otrzymuj co tydzień najnowsze informacje o tworzeniu aplikacji na Androida na swoją skrzynkę odbiorczą.
