
Temel bilgiler: Android 17'nin kilit içermeyen MessageQueue'su
Okuma süresi 16 dakika

Android 17'de, SDK 37 veya sonraki sürümleri hedefleyen uygulamalar, kilitsiz bir uygulama olan MessageQueue'nun yeni bir uygulamasını alır. Yeni uygulama, performansı artırır ve kaçırılan kare sayısını azaltır ancak MessageQueue özel alanlarını ve yöntemlerini yansıtan istemcilerin çalışmasını bozabilir. Davranış değişikliği ve etkisini nasıl azaltabileceğiniz hakkında daha fazla bilgi edinmek için MessageQueue davranış değişikliği dokümanlarına göz atın. Bu teknik blog yayınında, MessageQueue'nun yeniden mimarisi ve Perfetto'yu kullanarak kilit çekişmesi sorunlarını nasıl analiz edebileceğiniz hakkında genel bilgiler verilmektedir.
Looper, her Android uygulamasının kullanıcı arayüzü iş parçacığını çalıştırır. MessageQueue'dan iş çeker, Handler'a gönderir ve bu işlemi tekrarlar. MessageQueue, yirmi yıldır durumunu korumak için tek bir monitör kilidi (yani synchronized kod bloğu) kullanıyordu.
Android 17, bu bileşende önemli bir güncelleme sunuyor: DeliQueue adlı kilit içermeyen bir uygulama.
Bu yayında, kilitlerin kullanıcı arayüzü performansını nasıl etkilediği, bu sorunların Perfetto ile nasıl analiz edileceği ve Android ana iş parçacığını iyileştirmek için kullanılan belirli algoritmalar ve optimizasyonlar açıklanmaktadır.
Sorun: Kilit çekişmesi ve öncelik tersine çevrilmesi
Eski MessageQueue işlevi, tek bir kilit ile korunan bir öncelik sırası olarak çalışıyordu. Ana iş parçacığı kuyruk bakımı yaparken bir arka plan iş parçacığı mesaj yayınlarsa arka plan iş parçacığı ana iş parçacığını engeller.
Aynı kilidin özel kullanımı için iki veya daha fazla iş parçacığı yarıştığında buna kilit çekişmesi denir. Bu çekişme, Öncelik Tersine Çevrilmesi sorununa neden olabilir. Bu da kullanıcı arayüzünde duraklamaya ve diğer performans sorunlarına yol açar.
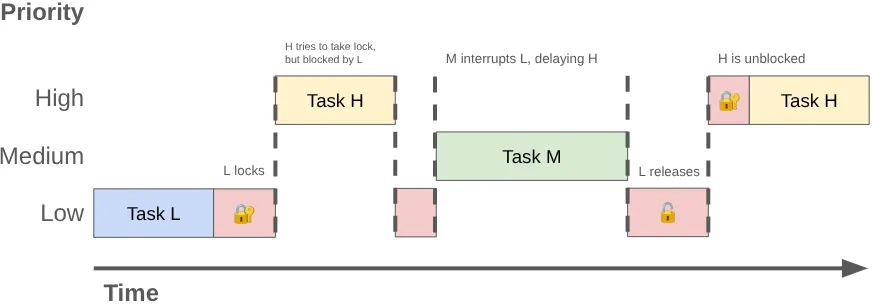
Öncelik tersine çevrilmesi, yüksek öncelikli bir iş parçacığı (ör. kullanıcı arayüzü iş parçacığı) düşük öncelikli bir iş parçacığını beklemek zorunda kaldığında meydana gelebilir. Şu sırayı ele alalım:
MessageQueuekilidini, yaptığı işin sonucunu yayınlamak için düşük öncelikli bir arka plan iş parçacığı alır.- Orta öncelikli bir iş parçacığı çalıştırılabilir hale gelir ve çekirdeğin zamanlayıcısı, düşük öncelikli iş parçacığını kesintiye uğratarak bu iş parçacığına CPU zamanı ayırır.
- Yüksek öncelikli kullanıcı arayüzü iş parçacığı mevcut görevini tamamlar ve kuyruktan okumaya çalışır ancak düşük öncelikli iş parçacığı kilidi tuttuğu için engellenir.
Düşük öncelikli iş parçacığı, kullanıcı arayüzü iş parçacığını engeller ve orta öncelikli iş, bu durumu daha da geciktirir.
Perfetto ile çekişmeyi analiz etme
Bu sorunları Perfetto'yu kullanarak teşhis edebilirsiniz. Standart bir izlemede, bir monitör kilidinde engellenen iş parçacığı uyku durumuna girer ve Perfetto, kilit sahibini gösteren bir dilim gösterir.
İz verilerini sorguladığınızda, "monitor contention with …" adlı dilimlerin ardından kilidin sahibi olan iş parçacığının adı ve kilidin alındığı kod sitesi gelir.
Örnek olay: Başlatıcıda takılma
Örnek olarak, bir kullanıcının kamera uygulamasında fotoğraf çektikten hemen sonra Pixel telefonda ana sayfada gezinirken duraklama yaşadığı bir izlemeyi analiz edelim. Aşağıda, Perfetto'nun kaçırılan kareye yol açan etkinlikleri gösteren ekran görüntüsünü görüyoruz:
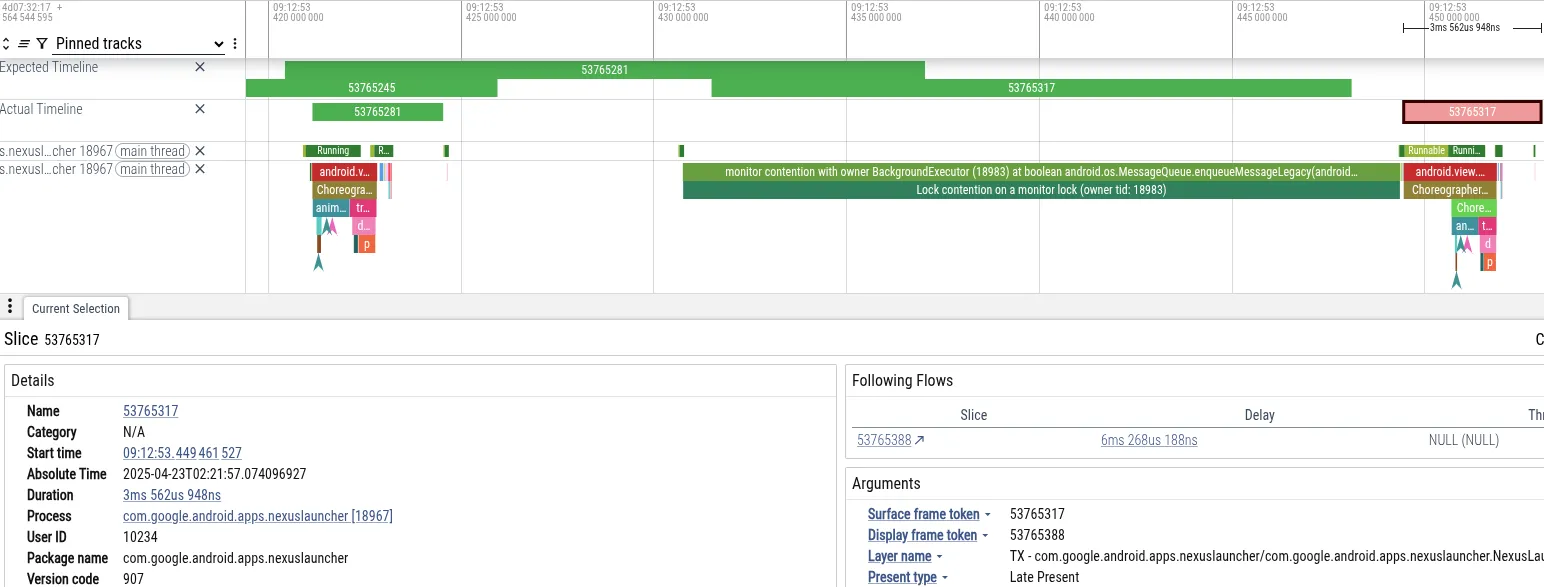
- Belirti: Başlatıcı'nın ana ileti dizisi, kare teslim tarihini kaçırdı. 18 ms boyunca engellendi. Bu süre, 60 Hz oluşturma için gereken 16 ms'lik son tarihi aşıyor.
- Teşhis: Perfetto, ana iş parçacığının
MessageQueuekilidinde engellendiğini gösterdi. Kilit, "BackgroundExecutor" adlı bir ileti dizisine aitti. - Temel neden: BackgroundExecutor, Process.THREAD_PRIORITY_BACKGROUND (çok düşük öncelik) ile çalışır. Acil olmayan bir görev (uygulama kullanım sınırlarını kontrol etme) gerçekleştirildi. Aynı anda, orta öncelikli iş parçacıkları kameradan gelen verileri işlemek için CPU süresini kullanıyordu. İşletim sistemi zamanlayıcısı, kamera iş parçacıklarını çalıştırmak için BackgroundExecutor iş parçacığını önceden boşalttı.
Bu sıra, Başlatıcı'nın kullanıcı arayüzü iş parçacığının (yüksek öncelikli) dolaylı olarak kamera çalışan iş parçacığı (orta öncelikli) tarafından engellenmesine neden oldu. Bu durum, Başlatıcı'nın arka plan iş parçacığının (düşük öncelikli) kilidi serbest bırakmasını engelledi.
PerfettoSQL ile izlemeleri sorgulama
Belirli kalıplar için izleme verilerini sorgulamak üzere PerfettoSQL'i kullanabilirsiniz. Bu özellik, kullanıcı cihazlarından veya testlerden alınan çok sayıda iziniz varsa ve bir sorunu gösteren belirli izleri arıyorsanız yararlıdır.
Örneğin, bu sorgu, bırakılan karelerle (jank) çakışan MessageQueue çekişmesini bulur:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
Bu daha karmaşık örnekte, uygulama başlatılırken MessageQueue çekişmesini belirlemek için birden fazla tabloyu kapsayan izleme verilerini birleştirin:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Diğer kalıpları bulmak için PerfettoSQL sorguları yazmak üzere en sevdiğiniz LLM'yi kullanabilirsiniz.
Google'da, milyonlarca izde PerfettoSQL sorguları çalıştırmak için BigTrace'i kullanıyoruz. Bunu yaparken, anekdot olarak gördüğümüz şeyin aslında sistematik bir sorun olduğunu doğruladık. Veriler, MessageQueue kilit çekişmesinin tüm ekosistemdeki kullanıcıları etkilediğini ortaya koyarak temel bir mimari değişikliğin gerekliliğini doğruladı.
Çözüm: Kilit içermeyen eşzamanlılık
Paylaşılan duruma erişimi senkronize etmek için özel kilitler yerine atomik bellek işlemleri kullanarak kilit içermeyen bir veri yapısı uygulayarak MessageQueue çekişme sorununu ele aldık. Diğer iş parçacıklarının planlama davranışından bağımsız olarak her zaman en az bir iş parçacığı ilerleme kaydedebiliyorsa veri yapısı veya algoritma kilit içermez. Bu özellik genellikle elde edilmesi zordur ve çoğu kod için genellikle takip etmeye değmez.
Atomik temel öğeler
Kilit içermeyen yazılımlar genellikle donanımın sağladığı atomik Read-Modify-Write (Okuma-Değiştirme-Yazma) temel öğelerini kullanır.
Eski nesil ARM64 CPU'larda atomik işlemler için Load-Link/Store-Conditional (LL/SC) döngüsü kullanılıyordu. CPU bir değer yükler ve adresi işaretler. Başka bir iş parçacığı bu adrese yazarsa depolama işlemi başarısız olur ve döngü yeniden denenir. İş parçacıkları başka bir iş parçacığını beklemeden denemeye devam edip başarılı olabileceğinden bu işlem kilitlenmez.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr(Compiler Explorer'da görüntüle)
Daha yeni ARM mimarileri (ARMv8.1), Large System Extensions (LSE)'ı destekler. Bu mimarilerde Compare-And-Swap (CAS) veya Load-And-Add (aşağıda gösterilmiştir) biçiminde talimatlar bulunur. Android 17'de, LSE'nin desteklendiği zamanları algılamak ve optimize edilmiş talimatlar yayınlamak için Android Çalışma Zamanı (ART) derleyicisine destek ekledik:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Karşılaştırmalarımızda, CAS kullanan yüksek çekişmeli kod, LL/SC varyantına göre yaklaşık 3 kat daha hızlıdır.
Java programlama dili, java.util.concurrent.atomic aracılığıyla bu ve diğer özel CPU talimatlarına dayanan atomik temel öğeler sunar.
Veri Yapısı: DeliQueue
Mühendislerimiz, MessageQueue'daki kilit çekişmesini kaldırmak için DeliQueue adlı yeni bir veri yapısı tasarladı. DeliQueue, Message ekleme işlemini Message işleme işleminden ayırır:
Messages(Treiber yığını): Kilit içermeyen bir yığın. Herhangi bir iş parçacığı, çekişme olmadan buraya yeniMessagesgönderebilir.- Öncelikli sıra (min-heap): Yalnızca Looper iş parçacığına ait olan ve
Messagesişlemek için kullanılan bir yığın (dolayısıyla erişmek için senkronizasyon veya kilit gerekmez).
Sıraya alma: Treiber yığınına gönderme
Messages listesi, baş işaretçisini güncellemek için CAS döngüsü kullanan kilit içermeyen bir yığın olan Treiber yığınında [1] tutulur.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Java Concurrency in Practice [2] adlı kitaba dayalı kaynak kodu, online olarak kullanılabilir ve kamuya açık alan olarak yayınlanmıştır.
Tüm üreticiler, diledikleri zaman yığına yeni Message gönderebilir. Bu, şarküteri tezgahında sıra numarası almaya benzer. Sıra numaranız, geldiğiniz zamana göre belirlenir ancak yemeğinizi alma sıranızla eşleşmek zorunda değildir. Bağlı bir yığın olduğundan her Message bir alt yığındır. Baş kısmı izleyip ileriye doğru yineleme yaparak Message kuyruğunun herhangi bir zamanda nasıl olduğunu görebilirsiniz. Gezinme sırasında ekleniyor olsalar bile üst kısma yeni Message'lar itilmez.
Kuyruktan çıkarma: min-heap'e toplu aktarım
İşlenecek bir sonraki Message öğesini bulmak için Looper, yığını yukarıdan başlayıp daha önce işlediği son Message öğesini bulana kadar yineleyerek Treiber yığınındaki yeni Message öğelerini işler. Looper yığın boyunca ilerlerken son tarihe göre sıralanmış min-heap'e Message ekler. Looper, yığın üzerinde tek başına hak sahibi olduğundan Message'leri kilitleme veya atomik işlemler olmadan sıralar ve işler.

Yığın aşağı doğru ilerlerken Looper, yığılmış Message'lardan öncekilere bağlantılar da oluşturarak çift bağlantılı bir liste oluşturur. Bağlı liste oluşturmak güvenlidir. Bunun nedeni, yığın aşağısını işaret eden bağlantıların CAS ile Treiber yığın algoritması aracılığıyla eklenmesi ve yığın yukarısını işaret eden bağlantıların yalnızca Looper iş parçacığı tarafından okunup değiştirilmesidir. Bu geri bağlantılar daha sonra, yığındaki rastgele noktalardan Message öğelerini O(1) süresinde kaldırmak için kullanılır.
Bu tasarım, üreticiler(kuyruğa iş gönderen iş parçacıkları) için O (1) ekleme ve tüketici(Looper) için amortize edilmiş O (log N) işleme sağlar.
Message sıralamak için min-heap kullanmak, Message'ların tek bağlantılı bir listede (en üstte köklenmiş) tutulduğu eski MessageQueue'deki temel bir kusuru da giderir. Eski uygulamada, baştan kaldırma O(1) iken ekleme için en kötü durum O(N) idi. Bu da aşırı yüklenmiş kuyruklar için kötü bir ölçeklendirme anlamına geliyordu. Buna karşılık, min-heap'e ekleme ve min-heap'ten kaldırma işlemleri logaritmik olarak ölçeklenir. Bu da rekabetçi bir ortalama performans sunar ancak kuyruk gecikmelerinde gerçekten üstün bir performans sağlar.
Eski (kilitli) MessageQueue | DeliQueue | |
| Ekle | O(N) | Arama iş parçacığı için O(1)
|
| Kafadan çıkarma | O(1) | O(logN) |
Eski kuyruk uygulamasında, üreticiler ve tüketici, temel tek bağlı listeye özel erişimi koordine etmek için bir kilit kullanıyordu. DeliQueue'da Treiber yığını eşzamanlı erişimi, tek tüketici ise iş kuyruğunun sıralanmasını yönetir.
Kaldırma: mezar taşları aracılığıyla tutarlılık
DeliQueue, kilit içermeyen Treiber yığınını tek iş parçacıklı min-heap ile birleştiren hibrit bir veri yapısıdır. Bu iki yapıyı global bir kilit olmadan senkronize tutmak benzersiz bir zorluktur: Bir ileti, yığında fiziksel olarak bulunabilir ancak kuyruktan mantıksal olarak kaldırılabilir.
DeliQueue, bu sorunu çözmek için "tombstoning" adı verilen bir teknik kullanır. Her Message, yığın içindeki konumunu geriye ve ileriye doğru işaretçiler, yığının dizisindeki dizini ve kaldırılıp kaldırılmadığını belirten bir boolean işareti aracılığıyla izler. Bir Message çalışmaya hazır olduğunda Looper iş parçacığı, kaldırılan işaretini CAS'e alır, ardından yığın ve yığından kaldırır.
Başka bir iş parçacığı Message öğesini kaldırması gerektiğinde bu öğe, veri yapısından hemen çıkarılmaz. Bunun yerine aşağıdaki adımlar uygulanır:
- Mantıksal kaldırma: İş parçacığı,
Messageöğesinin kaldırma işaretini atomik olarak false'tan true'ya ayarlamak için CAS kullanır.Message, bekleyen kaldırma işleminin kanıtı olarak veri yapısında kalır. Bu işleme "mezar taşı" adı verilir. BirMessagekaldırma için işaretlendiğinde DeliQueue, her bulunduğunda bunu kuyrukta artık mevcut değilmiş gibi ele alır. - Ertelenmiş temizleme: Veri yapısından gerçek kaldırma işlemi
Looperiş parçacığının sorumluluğundadır ve daha sonraya ertelenir. Kaldırma iş parçacığı, yığını veya heap'i değiştirmek yerineMessageöğesini başka bir kilit içermeyen serbest liste yığınına ekler. - Yapısal kaldırma: Yalnızca
Looperyığınla etkileşime girebilir veya öğeleri yığından kaldırabilir. Uyandığında boş liste temizlenir ve içerdiğiMessageişlenir. HerMessage, gruptan ayrılır ve yığından kaldırılır.
Bu yaklaşım, yığınla ilgili tüm yönetimi tek iş parçacıklı tutar. Bu özellik, gereken eşzamanlı işlem ve bellek bariyeri sayısını en aza indirerek kritik yolu daha hızlı ve basit hale getirir.
Geçiş: zararsız Java bellek modeli veri yarışları
Java standart kitaplığındaki Future veya Kotlin'deki Job ve Deferred gibi çoğu eşzamanlılık API'si, tamamlanmadan önce çalışmayı iptal etme mekanizması içerir. Bu sınıflardan birinin örneği, temel çalışmanın bir birimiyle bire bir eşleşir ve bir nesne üzerinde cancel çağrısı yapıldığında bunlarla ilişkili belirli işlemler iptal edilir.
Günümüzün Android cihazlarında çok çekirdekli CPU'lar ve eşzamanlı, nesil tabanlı atık toplama özelliği bulunur. Ancak Android ilk geliştirildiğinde her bir iş birimi için bir nesne ayırmak çok maliyetliydi. Bu nedenle, Android'in Handler, removeMessages'nin çok sayıda aşırı yüklenmesi aracılığıyla iptali destekler. Belirli bir Message'i kaldırmak yerine, belirtilen ölçütlere uyan tüm Message'leri kaldırır. Uygulamada bu, removeMessages çağrılmadan önce eklenen tüm Message öğelerinin üzerinden geçmeyi ve eşleşenleri kaldırmayı gerektirir.
İleriye doğru yineleme yaparken bir iş parçacığı, yığının mevcut başını okumak için yalnızca sıralı bir atomik işlem gerektirir. Bundan sonra, sonraki Message öğesini bulmak için normal alan okumaları kullanılır. Looper iş parçacığı, Message'leri kaldırırken next alanlarını değiştirirse Looper'nin yazma işlemi ile başka bir iş parçacığının okuma işlemi senkronize olmaz. Bu durum veri yarışı olarak adlandırılır. Normalde veri yarışı, uygulamanızda büyük sorunlara (ör. sızıntılar, sonsuz döngüler, kilitlenmeler, donmalar) neden olabilecek ciddi bir hatadır. Ancak belirli dar koşullar altında, Java bellek modelinde veri yarışları zararsız olabilir. Aşağıdaki yığınla başladığımızı varsayalım:

Başın atomik okumasını yaparız ve A'yı görürüz. A'nın sonraki işaretçisi B'yi gösterir. B işlenirken looper, A'yı C'ye ve ardından D'ye yönlendirecek şekilde güncelleyerek B ve C'yi kaldırabilir.
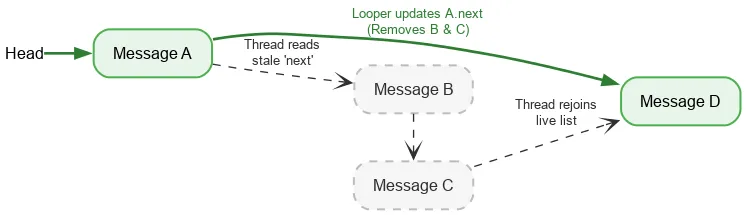
B ve C mantıksal olarak kaldırılmış olsa da B, C'ye, C ise D'ye olan sonraki işaretçisini korur. Okuma iş parçacığı, ayrılmış kaldırılmış düğümler arasında gezinmeye devam eder ve sonunda D konumunda canlı yığına yeniden katılır.
DeliQueue'yu geçiş ve kaldırma arasındaki yarışları yönetecek şekilde tasarlayarak güvenli ve kilitsiz yinelemeye olanak tanırız.
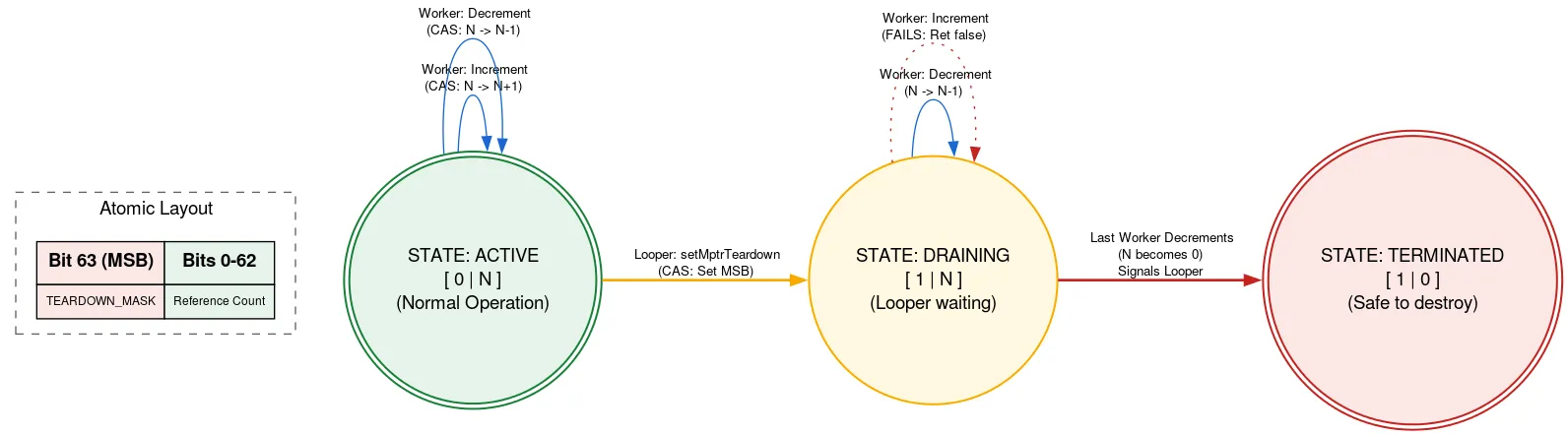
Çıkış: Yerel referans sayısı
Looper, Looper kapatıldıktan sonra manuel olarak boşaltılması gereken yerel bir ayırma ile desteklenir. Looper çıkarken başka bir iş parçacığı Message ekliyorsa serbest bırakıldıktan sonra yerel ayırmayı kullanabilir. Bu, bellek güvenliği ihlalidir. Bunu, etiketli bir referans sayısı kullanarak önleriz. Burada, atomik işlemin bir biti, Looper işleminin sonlandırılıp sonlandırılmadığını belirtmek için kullanılır.
Yerel ayırma kullanılmadan önce bir iş parçacığı, refcount atomik olarak okunur. Çıkış biti ayarlanmışsa Looper çıkış yapıyor ve yerel ayırma işlemi kullanılmamalıdır. Aksi takdirde, yerel ayırmayı kullanarak etkin iş parçacığı sayısını artırmak için CAS işlemi denenir. Gerekli işlemi yaptıktan sonra sayıyı azaltır. Çıkış biti, artırıldıktan sonra ancak azaltılmadan önce ayarlanmışsa ve sayı artık sıfırsa Looper iş parçacığını uyandırır.
Looper iş parçacığı çıkmaya hazır olduğunda atomik olarak çıkış bitini ayarlamak için CAS'i kullanır. Refcount 0 ise yerel ayırmasını boşaltmaya devam edebilir. Aksi takdirde, yerel ayırmanın son kullanıcısı referans sayısını azalttığında uyandırılacağını bilerek kendini park eder. Bu yaklaşım, Looper iş parçacığının diğer iş parçacıklarının ilerlemesini yalnızca çıkarken beklediği anlamına gelir. Bu işlem yalnızca bir kez gerçekleşir ve performansa duyarlı değildir. Ayrıca, yerel dağıtımı kullanmak için diğer kodu tamamen kilitlenmeden kullanmaya devam edebilirsiniz.
Uygulamada başka birçok püf nokta ve karmaşıklık vardır. Kaynak kodunu inceleyerek DeliQueue hakkında daha fazla bilgi edinebilirsiniz.
Optimizasyon: dallanmasız programlama
Ekip, DeliQueue'yu geliştirip test ederken birçok karşılaştırma testi yaptı ve yeni kodu dikkatlice profillendirdi. simpleperf aracı kullanılarak belirlenen bir sorun, Message karşılaştırıcı kodunun neden olduğu ardışık düzen temizlemeleriydi.
Standart bir karşılaştırıcı, koşullu atlamalar kullanır. Hangi Message öğesinin önce geleceğine karar verme koşulu aşağıda basitleştirilmiştir:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Bu kod, koşullu atlamalar (b.le ve cbnz talimatları) olarak derlenir. CPU, koşullu bir dallanmayla karşılaştığında koşul hesaplanana kadar dallanmanın alınıp alınmadığını bilemez. Bu nedenle, bir sonraki talimatın hangisi olduğunu bilemez ve dallanma tahmini adı verilen bir teknik kullanarak tahmin etmek zorunda kalır. İkili arama gibi bir durumda, her adımda dal yönü tahmin edilemeyecek şekilde farklı olacağından tahminlerin yarısının yanlış olması muhtemeldir. Dallanma tahmini, yanlış tahmin etmenin maliyeti doğru tahmin etmenin getirdiği iyileşmeden daha büyük olduğu için arama ve sıralama algoritmalarında (ör. min-heap'te kullanılan) genellikle etkili değildir. Dallanma tahmincisi yanlış tahminde bulunduğunda, tahmin edilen değeri varsaydıktan sonra yaptığı işi atmalı ve aslında izlenen yoldan tekrar başlamalıdır. Bu işleme işlem hattı temizleme adı verilir.
Bu sorunu bulmak için, şube tahmincisinin yanlış tahmin yaptığı yığın izlerini kaydeden branch-misses performans sayacını kullanarak karşılaştırma ölçütlerimizin profilini oluşturduk. Ardından, sonuçları aşağıdaki gibi Google pprof ile görselleştirdik:
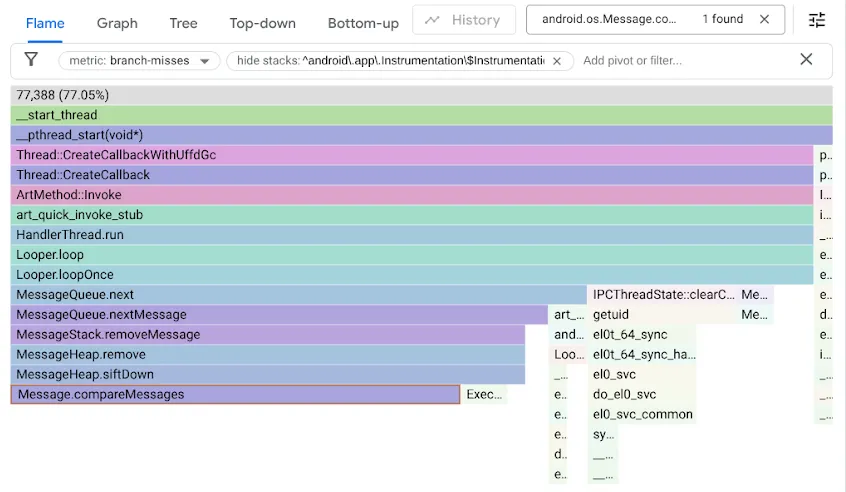
Orijinal MessageQueue kodunun, sıralı kuyruk için tek bağlantılı bir liste kullandığını hatırlayın. Ekleme işlemi, doğrusal bir arama olarak sıralı düzende listede ilerler, ekleme noktasını geçen ilk öğede durur ve yeni Message öğesini bu öğenin önüne bağlar. Başlığın kaldırılması için bağlantısının kaldırılması yeterliydi. DeliQueue ise bir min-heap kullanır. Burada mutasyonlar, dengeli bir veri yapısında logaritmik karmaşıklıkla bazı öğelerin yeniden sıralanmasını (yukarı veya aşağı süzme) gerektirir. Bu veri yapısında herhangi bir karşılaştırma, geçişi sol veya sağ alt öğeye yönlendirme konusunda eşit şansa sahiptir. Yeni algoritma, asimptotik olarak daha hızlıdır ancak arama kodu, dal atlamaları sırasında yarı yarıya durakladığı için yeni bir performans sorunu oluşturur.
Dallanma hatalarının yığın kodumuzu yavaşlattığını fark edince dalsız programlama kullanarak kodu optimize ettik:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Optimizasyonu anlamak için Compiler Explorer'da iki örneği sökün ve tahmini CPU döngüsü zaman çizelgesi oluşturabilen bir CPU simülatörü olan LLVM-MCA'yı kullanın.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Sonuç, when alanlarının karşılaştırılmasıyla zaten biliniyorsa insertSeq alanlarının karşılaştırılmasını engelleyen koşullu dal b.le'ya dikkat edin.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Burada, dallanmasız uygulama, dallı kodda en kısa yoldan bile daha az döngü ve talimat gerektirir. Bu nedenle, her durumda daha iyidir. Daha hızlı uygulama ve yanlış tahmin edilen dalların ortadan kaldırılması, bazı karşılaştırma testlerimizde 5 kat iyileşme sağladı.
Ancak bu teknik her zaman uygulanamaz. Dalsız yaklaşımlar genellikle atılacak işler yapmayı gerektirir ve dal çoğu zaman tahmin edilebilirse bu boşa giden işler kodunuzu yavaşlatabilir. Ayrıca, bir dalın kaldırılması genellikle veri bağımlılığına neden olur. Modern CPU'lar döngü başına birden fazla işlem yürütür ancak önceki bir talimattan gelen girişler hazır olana kadar bir talimatı yürütemezler. Buna karşılık CPU, dallardaki veriler hakkında tahminde bulunabilir ve bir dal doğru tahmin edilirse önceden çalışabilir.
Test ve Doğrulama
Kilit içermeyen algoritmaların doğruluğunu onaylamak son derece zordur.
Geliştirme sırasında sürekli doğrulama için standart birim testlerine ek olarak, sıra değişmezlerini doğrulamak ve veri yarışları varsa bunları tetiklemeye çalışmak için titiz yük testleri de yazdık. Test laboratuvarlarımızda, milyonlarca test örneğini emüle edilmiş cihazlarda ve gerçek donanımlarda çalıştırabildik.
Java ThreadSanitizer (JTSan) enstrümanı ile kodumuzdaki bazı veri yarışlarını tespit etmek için de aynı testleri kullanabiliriz. JTSan, DeliQueue'da sorunlu veri yarışları bulamadı ancak şaşırtıcı bir şekilde Robolectric çerçevesinde iki eşzamanlılık hatası tespit etti. Bu hataları hemen düzelttik.
Hata ayıklama özelliklerimizi geliştirmek için yeni analiz araçları oluşturduk. Aşağıda, Android platform kodundaki bir sorunu gösteren bir örnek verilmiştir. Bu örnekte, bir iş parçacığı başka bir iş parçacığını Message ile aşırı yükleyerek büyük bir birikime neden oluyor. Bu birikim, eklediğimiz MessageQueue enstrümantasyon özelliği sayesinde Perfetto'da görülebiliyor.
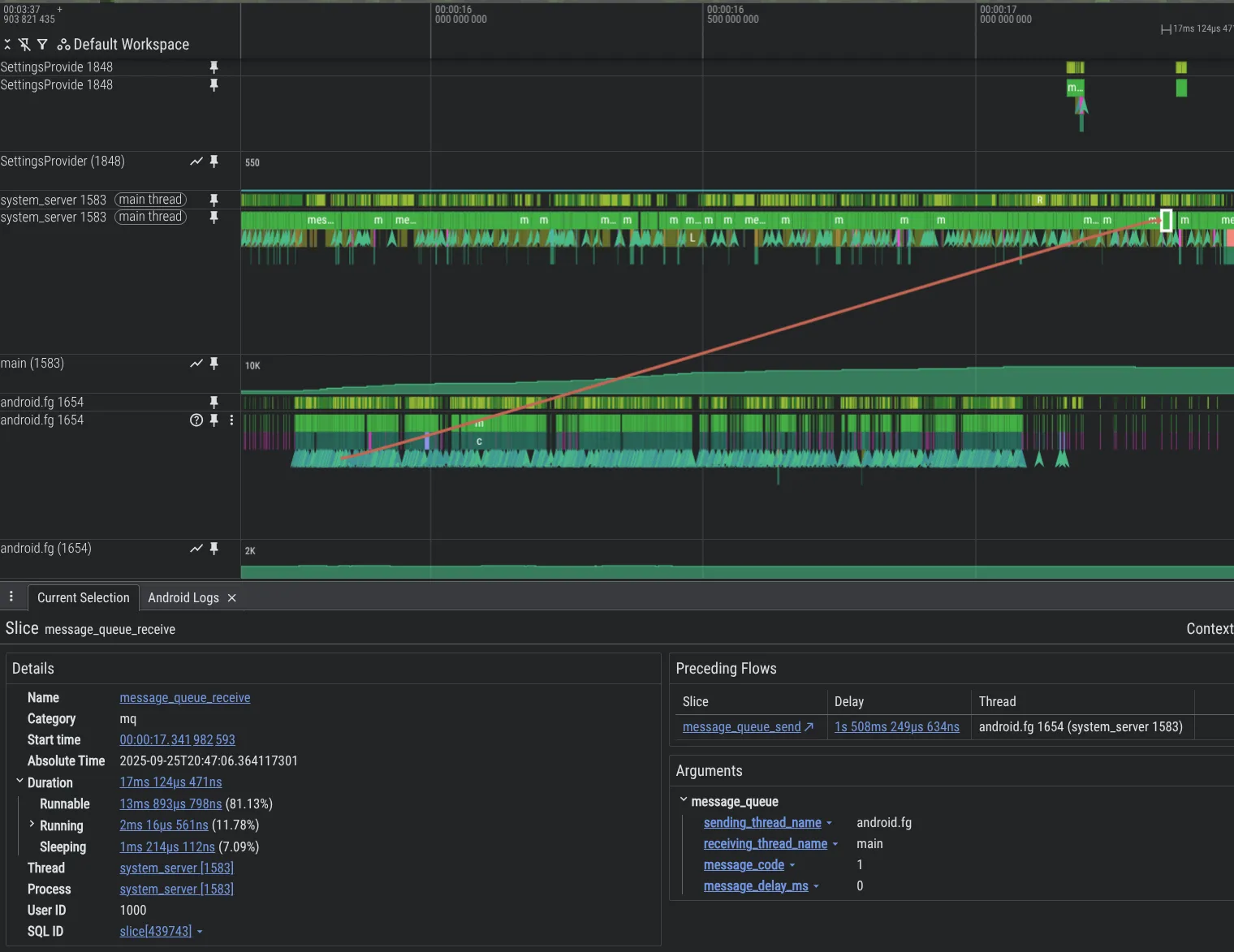
MessageQueue izlemeyi system_server sürecinde etkinleştirmek için Perfetto yapılandırmanıza aşağıdakileri ekleyin:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Etki
DeliQueue, MessageQueue uygulamasındaki kilitleri kaldırarak sistem ve uygulama performansını artırır.
- Sentetik kıyaslamalar: Geliştirilmiş eşzamanlılık (Treiber yığını) ve daha hızlı eklemeler (min-heap) sayesinde,yoğun kuyruklara çok iş parçacıklı eklemeler, eski
MessageQueue'den 5.000 kat daha hızlıdır. - Dahili beta test kullanıcılarından alınan Perfetto izlerinde, kilit çekişmesinde harcanan uygulama ana iş parçacığı süresinde% 15'lik bir azalma görüyoruz.
- Aynı test cihazlarında, kilit çekişmesinin azaltılması kullanıcı deneyiminde önemli iyileşmelere yol açar. Örneğin:
- Uygulamalarda% 4 kare kaybı.
- Sistem Arayüzü ve Başlatıcı etkileşimlerinde% 7,7 kare atlandı.
- Uygulama başlatmadan ilk karenin çizilmesine kadar geçen sürede %9, 1 azalma (95.yüzdelik dilimde).
Sonraki adımlar
DeliQueue, Android 17'deki uygulamalarda kullanıma sunuluyor. Uygulama geliştiriciler, uygulamalarını nasıl test edeceklerini öğrenmek için Android Developers blogunda uygulamanızı yeni kilit içermeyen MessageQueue için hazırlama konusunu incelemelidir.
Referanslar
[1] Treiber, R.K., 1986. Sistem programlama: Paralellikle başa çıkma. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 Ürün Haberleri
Ürün HaberleriAndroid Studio Quail 2 artık kararlı ve üretimde kullanıma hazır. Bu sürümle birlikte, eşzamanlı yapay zeka destekli iş akışları, yerel olarak entegre edilmiş bellek sızıntısı profili oluşturma ve bağlama duyarlı kilitlenme düzeltme gibi özelliklerle IDE'nizde önemli bir değişiklik yapılıyor.
Amman Asfaw • Okuma süresi 3 dakika -

 Ürün Haberleri
Ürün HaberleriMart ayında, gerçek dünyadaki Android geliştirme görevleri için LLM liderlik tablomuz olan Android Bench'i tanıtmıştık. O zamandan beri, açık ağırlıklı modelleri değerlendirme ve maliyet ile verimlilik boyutlarını skor tablosuna ekleme gibi geri bildirimleriniz doğrultusunda karşılaştırma ölçütünü geliştirdik.
Zoe Lopez-Latorre • Okuma süresi 3 dakika -

 Ürün Haberleri
Ürün HaberleriGoogle Play'de, kullanıcılara mümkün olan en iyi deneyimi sunarken geliştiricilerin başarılı olmaları için gerekli araçlara ve uyum yeteneğine sahip olmalarını sağlamayı amaçlıyoruz.
Paul Feng • Okuma süresi 3 dakika
Android geliştirmeyle ilgili en son analizleri her hafta gelen kutunuza alın.
