
WorkManager ti consente di creare e mettere in coda una catena di lavoro che specifica più attività dipendenti e definisce l'ordine in cui devono essere eseguite. Questa funzionalità è particolarmente utile quando devi eseguire diverse attività in un ordine specifico.
Per creare una catena di lavoro, puoi utilizzare
WorkManager.beginWith(OneTimeWorkRequest)
o
WorkManager.beginWith(List<OneTimeWorkRequest>)
, che restituiscono ciascuno un'istanza di
WorkContinuation.
Un WorkContinuation può quindi essere utilizzato per aggiungere istanze OneTimeWorkRequest dipendenti utilizzando then(OneTimeWorkRequest) o then(List<OneTimeWorkRequest>).
Ogni chiamata di WorkContinuation.then(...) restituisce una nuova istanza di WorkContinuation. Se aggiungi un List di OneTimeWorkRequest istanze, queste richieste possono potenzialmente essere eseguite in parallelo.
Infine, puoi utilizzare il metodo
WorkContinuation.enqueue()
per enqueue() la tua catena di WorkContinuation.
Vediamo un esempio. In questo esempio, sono configurati per l'esecuzione (potenzialmente in parallelo) tre diversi job worker. I risultati di questi worker vengono poi uniti e trasmessi a un job worker di memorizzazione nella cache. Infine, l'output del job viene passato a un worker di caricamento, che carica i risultati su un server remoto.
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
Unioni di input
Quando concateni le istanze OneTimeWorkRequest, l'output delle richieste di lavoro principali viene passato come input alle istanze secondarie. Quindi, nell'esempio precedente, gli output di plantName1, plantName2 e plantName3 verranno passati come input alla richiesta cache.
Per gestire gli input di più richieste di lavoro principali, WorkManager utilizza
InputMerger.
Esistono due tipi diversi di InputMerger forniti da WorkManager:
OverwritingInputMergertenta di aggiungere tutte le chiavi di tutti gli input all'output. In caso di conflitti, sovrascrive le chiavi impostate in precedenza.ArrayCreatingInputMergertenta di unire gli input, creando array quando necessario.
Se hai un caso d'uso più specifico, puoi scrivere il tuo eseguendo la sottoclasse di
InputMerger.
OverwritingInputMerger
OverwritingInputMerger è il metodo di unione predefinito. Se si verificano conflitti tra le chiavi nell'unione, l'ultimo valore di una chiave sovrascriverà le versioni precedenti nei dati di output risultanti.
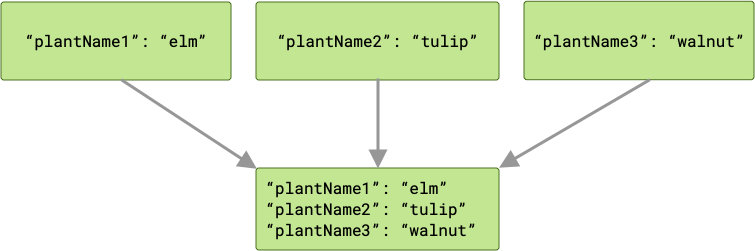
Ad esempio, se ogni input della pianta ha una chiave corrispondente al rispettivo
nome della variabile ("plantName1", "plantName2" e "plantName3"), i
dati passati al worker cache avranno tre coppie chiave-valore.
In caso di conflitto, vince l'ultimo worker a completare l'operazione e il suo valore
viene passato a cache.
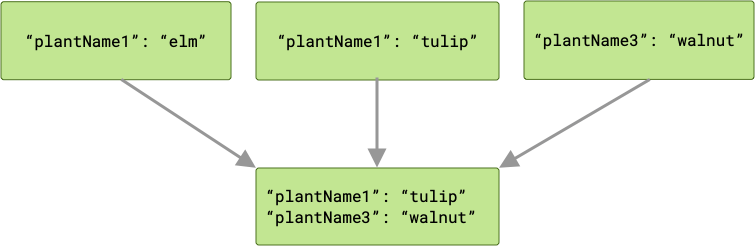
Poiché le richieste di lavoro vengono eseguite in parallelo, non hai garanzie per
l'ordine di esecuzione. Nell'esempio precedente, plantName1 potrebbe contenere un valore pari a "tulip" o "elm", a seconda di quale valore viene scritto per ultimo. Se hai la possibilità di un conflitto di chiavi e devi conservare tutti i dati di output in un'unione, ArrayCreatingInputMerger potrebbe essere un'opzione migliore.
ArrayCreatingInputMerger
Per l'esempio precedente, dato che vogliamo conservare gli output di tutti i worker con nome di pianta, dobbiamo utilizzare un ArrayCreatingInputMerger.
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
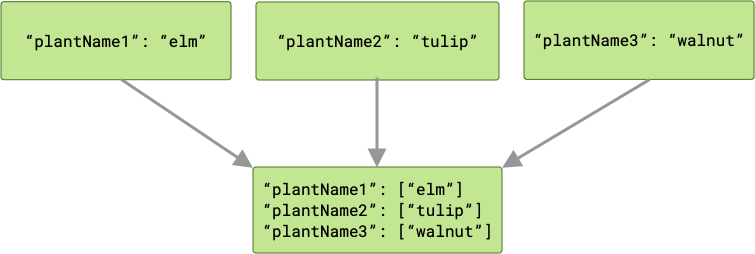
ArrayCreatingInputMerger associa ogni chiave a un array. Se ogni chiave è univoca, il risultato è una serie di array con un solo elemento.
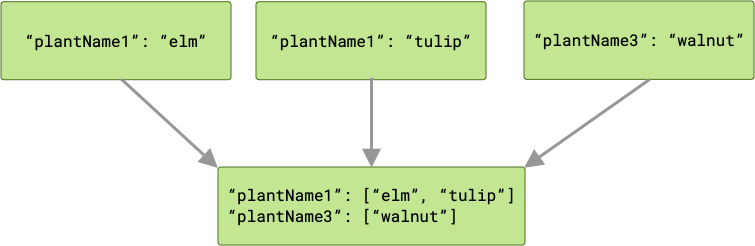
Se si verificano collisioni di chiavi, i valori corrispondenti vengono raggruppati in un array.
Concatenazione e stati di lavoro
Le catene di OneTimeWorkRequest vengono eseguite in sequenza finché il loro lavoro
viene completato correttamente (ovvero restituiscono un Result.success()). Le richieste di lavoro
potrebbero non riuscire o essere annullate durante l'esecuzione, il che ha effetti a cascata sulle
richieste di lavoro dipendenti.
Quando la prima OneTimeWorkRequest viene inserita in coda in una catena di richieste di lavoro,
tutte le richieste di lavoro successive vengono bloccate finché il lavoro della prima richiesta di lavoro non viene completato.
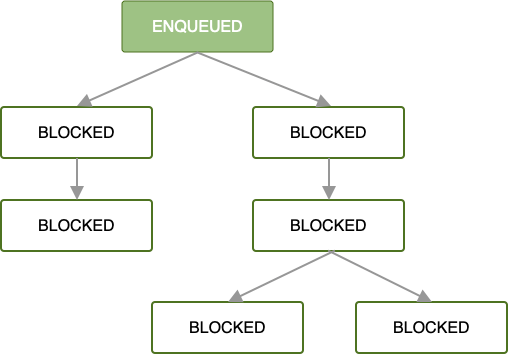
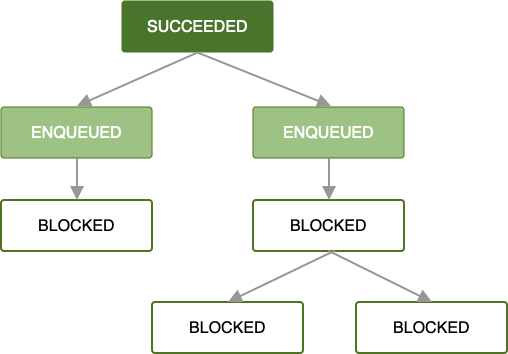
Una volta accodata e soddisfatte tutte le limitazioni del lavoro, inizia l'esecuzione della prima richiesta di lavoro. Se il lavoro viene completato correttamente nella radice
OneTimeWorkRequest o List<OneTimeWorkRequest> (ovvero restituisce un
Result.success()), viene accodata la serie successiva di richieste di lavoro dipendenti.
Finché ogni richiesta di lavoro viene completata correttamente, questo stesso pattern si propaga al resto della catena di richieste di lavoro finché tutto il lavoro nella catena non viene completato. Sebbene questo sia lo scenario più semplice e spesso preferito, è altrettanto importante gestire gli stati di errore.
Quando si verifica un errore durante l'elaborazione della richiesta di lavoro da parte di un worker, puoi riprovare a inviare la richiesta in base a una policy di backoff che definisci. Il nuovo tentativo di una richiesta che fa parte di una catena significa che verrà eseguito un nuovo tentativo solo per quella richiesta con i dati di input forniti. Qualsiasi lavoro in esecuzione in parallelo non sarà interessato.
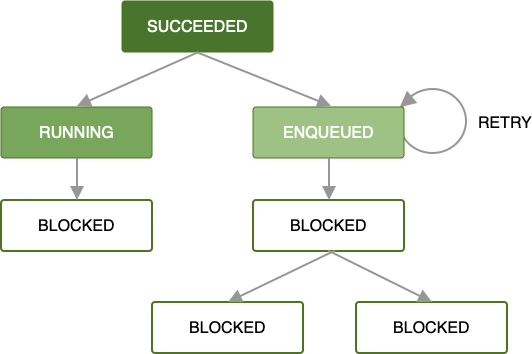
Per ulteriori informazioni sulla definizione di strategie di ripetizione personalizzate, consulta Criteri di ripetizione e backoff.
Se i criteri di riprova non sono definiti o sono esauriti oppure se raggiungi uno stato in cui OneTimeWorkRequest restituisce Result.failure(), la richiesta di lavoro e tutte le richieste di lavoro dipendenti vengono contrassegnate come FAILED..
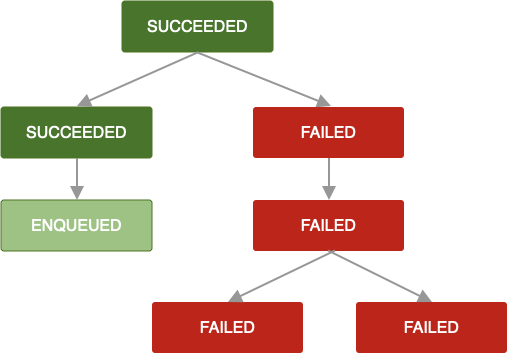
La stessa logica si applica quando un OneTimeWorkRequest viene annullato. Anche le richieste di lavoro
dipendenti vengono contrassegnate con CANCELLED e il lavoro non verrà eseguito.
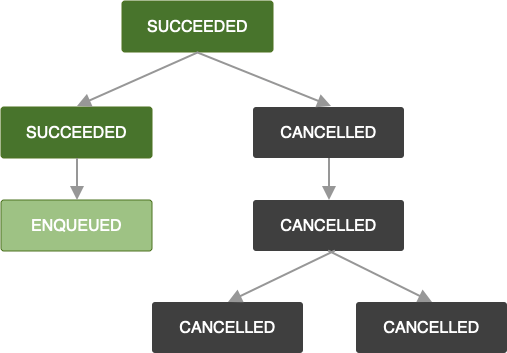
Tieni presente che se aggiungi altre richieste di lavoro a una catena che non è andata a buon fine o
che ha annullato le richieste di lavoro, anche la richiesta di lavoro appena aggiunta verrà
contrassegnata come FAILED o CANCELLED, rispettivamente. Se vuoi estendere il lavoro
di una catena esistente, consulta APPEND_OR_REPLACE in
ExistingWorkPolicy.
Quando crei catene di richieste di lavoro, le richieste di lavoro dipendenti devono definire policy di ripetizione per garantire che il lavoro venga sempre completato in modo tempestivo. Le richieste di lavoro non riuscite potrebbero comportare catene incomplete e/o uno stato imprevisto.
Per saperne di più, consulta Annullamento e interruzione del lavoro.