
כדי לבדוק את ה-shaders באמצעות AGI Frame Profiler, בוחרים קריאה לציור מאחד ממעברי הרינדור, ועוברים לקטע Vertex Shader או לקטע Fragment Shader בחלונית Pipeline.
כאן תוכלו למצוא נתונים סטטיסטיים שימושיים שמגיעים מניתוח סטטי של קוד ה-shader, וגם את קוד האסמבלי של Standard Portable Intermediate Representation (SPIR-V) שאליו קוד ה-GLSL שלנו עבר קומפילציה. יש גם כרטיסייה להצגת ייצוג של GLSL המקורי (עם שמות שנוצרו על ידי קומפיילר למשתנים, לפונקציות ועוד) שעבר דקומפילציה באמצעות SPIR-V Cross, כדי לספק הקשר נוסף ל-SPIR-V.
ניתוח סטטי
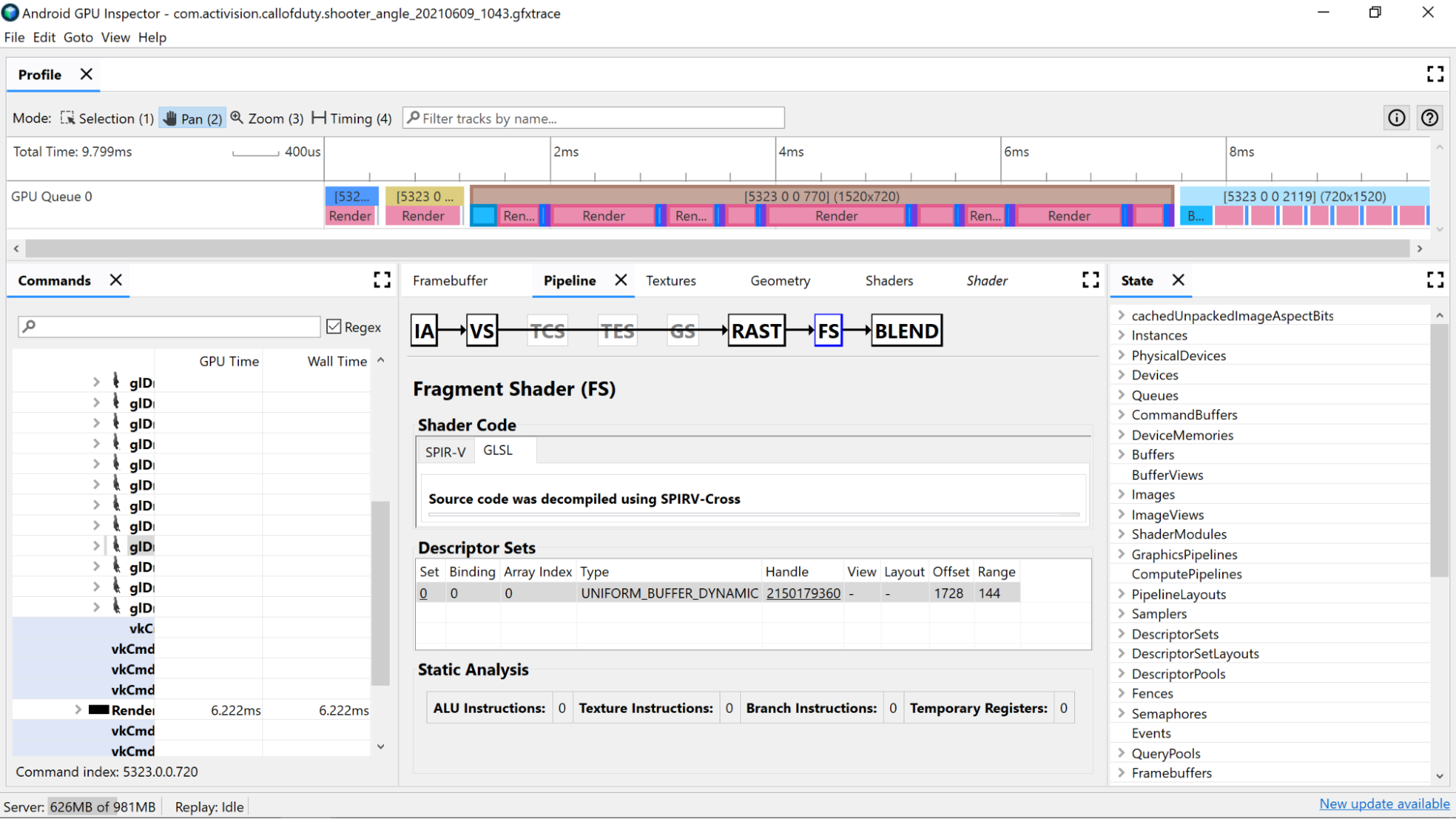
אפשר להשתמש בדלפקי ניתוח סטטי כדי לראות פעולות ברמה נמוכה ב-Shader.
הוראות ALU: המספר הזה מייצג את מספר הפעולות של ALU (חיבור, כפל, חילוק ועוד) שמבוצעות בתוך ה-Shader, והוא מהווה אינדיקטור טוב לרמת המורכבות של ה-Shader. מומלץ לנסות למזער את הערך הזה.
אפשר לשנות את מבנה החישובים הנפוצים או לפשט את החישובים שמתבצעים ב-shader כדי להקטין את מספר ההוראות שנדרשות.
הוראות לטקסטורה: המספר הזה מציין כמה פעמים מתבצעת דגימה של טקסטורה בשיידר.
- דגימת טקסטורות עלולה להיות יקרה, בהתאם לסוג הטקסטורות שמהן מתבצעת הדגימה. לכן, עיון בהפניות צולבות של קוד ה-Shader עם הטקסטורות המצורפות שנמצאות בקטע Descriptor Sets יכול לספק מידע נוסף על סוגי הטקסטורות שנמצאות בשימוש.
- מומלץ להימנע מגישה אקראית כשדוגמים טקסטורות, כי ההתנהגות הזו לא מתאימה לשמירת טקסטורות במטמון.
הוראות הסתעפות: המספר הזה מציין את מספר פעולות ההסתעפות ב-Shader. צמצום ההתפצלות הוא אידיאלי במעבדים מקביליים כמו GPU, ואפילו יכול לעזור לקומפיילר למצוא אופטימיזציות נוספות:
- כדי להימנע מהסתעפות לפי ערכים מספריים, אפשר להשתמש בפונקציות כמו
min, maxו-clamp. - בדיקת עלות החישוב על פני הסתעפות. מכיוון ששני הנתיבים של הסתעפות מבוצעים בארכיטקטורות רבות, יש הרבה תרחישים שבהם ביצוע החישוב תמיד מהיר יותר מאשר דילוג על החישוב באמצעות הסתעפות.
- כדי להימנע מהסתעפות לפי ערכים מספריים, אפשר להשתמש בפונקציות כמו
Temporary Registers: אלה הם רגיסטרים מהירים בתוך הליבה שמשמשים לאחסון התוצאות של פעולות ביניים שנדרשות לחישובים ב-GPU. יש מגבלה על מספר הרגיסטרים שזמינים לחישובים, ולכן המעבד הגרפי צריך להשתמש בזיכרון אחר מחוץ לליבה כדי לאחסן ערכי ביניים, מה שמפחית את הביצועים הכוללים. (ההגבלה הזו משתנה בהתאם לדגם ה-GPU).
מספר הרישומים הזמניים שנעשה בהם שימוש עשוי להיות גבוה מהצפוי אם קומפיילר ה-shader מבצע פעולות כמו ביטול לולאות, ולכן מומלץ להשוות את הערך הזה עם SPIR-V או GLSL שעבר דקומפילציה כדי לראות מה הקוד עושה.
ניתוח קוד של Shader
בודקים את קוד ה-shader שעבר דקומפילציה כדי לראות אם אפשר לבצע שיפורים.
- דיוק: הדיוק של משתני shader יכול להשפיע על הביצועים של ה-GPU באפליקציה.
- מומלץ להשתמש במשתנים עם
mediumpדיוק בינוני (16 ביט) בכל מקום שאפשר, כי בדרך כלל הם מהירים יותר וצורכים פחות חשמל מאשר משתנים עםhighpדיוק מלא (32 ביט).mediump - אם לא מופיעים מסיפי דיוק בשיידר בהצהרות על משתנים, או בחלק העליון של השיידר עם
precision precision-qualifier type, ברירת המחדל היא דיוק מלא (highp). חשוב לבדוק גם את ההצהרות על משתנים. - מומלץ להשתמש ב-
mediumpגם עבור הפלט של הצללת הקודקודים, מאותן סיבות שמתוארות למעלה. יש לכך גם יתרון של צמצום רוחב הפס של הזיכרון, ואולי גם צמצום השימוש הזמני ברגיסטר שנדרש לביצוע אינטרפולציה.
- מומלץ להשתמש במשתנים עם
- מאגרי נתונים אחידים: כדאי לשמור על הגודל של מאגרי נתונים אחידים קטן ככל האפשר (תוך שמירה על כללי היישור). כך אפשר לשפר את התאימות של החישובים לשמירה במטמון, ואולי גם לקדם נתונים אחידים לרישומים מהירים יותר בתוך הליבה.
הסרת פלט של Vertex Shader שלא נמצא בשימוש: אם אתם מוצאים פלט של Vertex Shader שלא נמצא בשימוש ב-Fragment Shader, הסירו אותו מה-Shader כדי לפנות רוחב פס של זיכרון ורגיסטרים זמניים.
העברת חישובים מ-Fragment Shader ל-Vertex Shader: אם קוד ה-Fragment Shader מבצע חישובים שלא תלויים במצב שספציפי ל-Fragment המוצלל (או שאפשר לבצע אינטרפולציה בצורה תקינה), מומלץ להעביר אותו ל-Vertex Shader. הסיבה לכך היא שברוב האפליקציות, vertex shader מופעל בתדירות נמוכה בהרבה בהשוואה ל-fragment shader.