
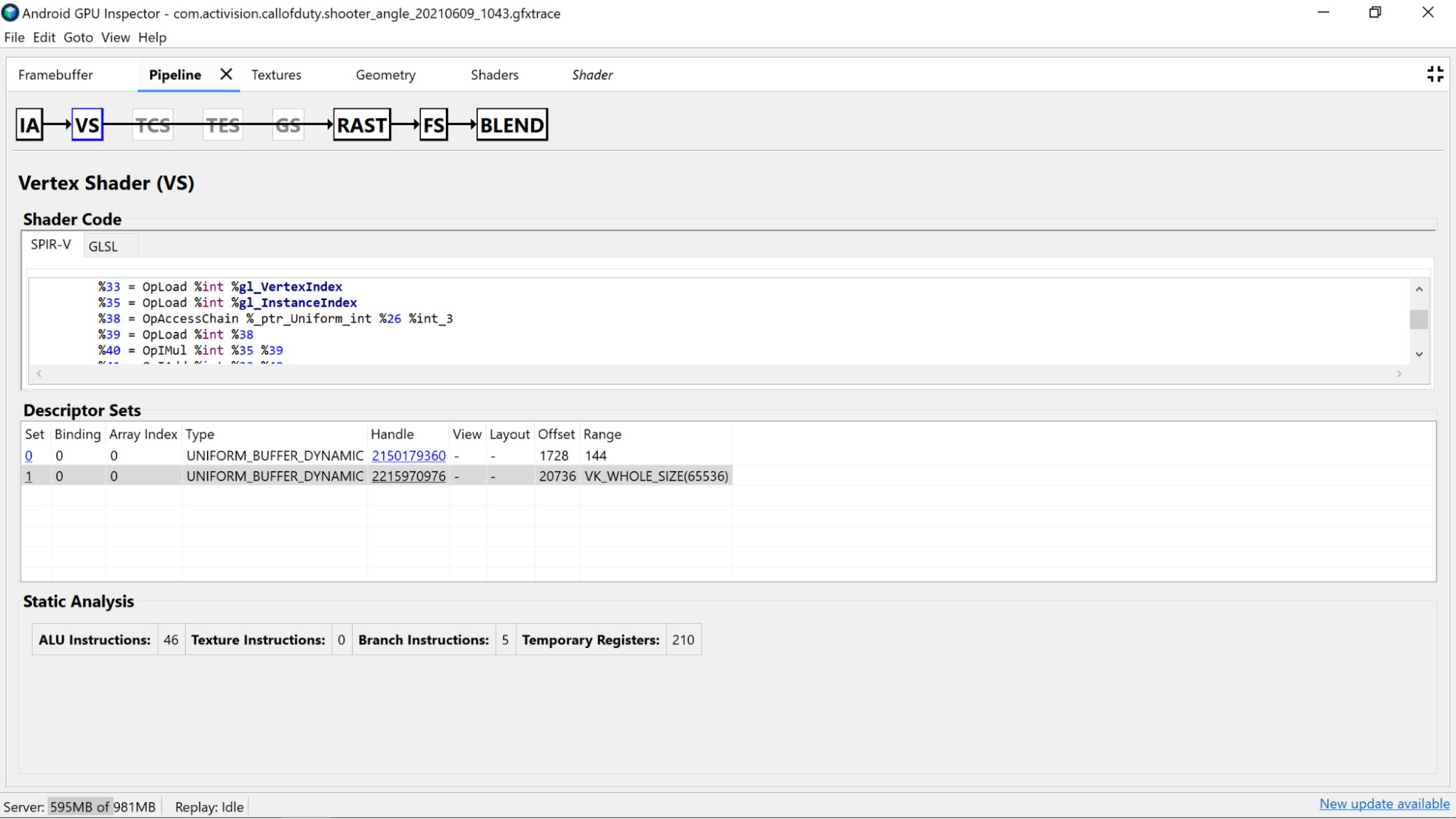
AGI Frame Profiler umożliwia zbadanie shaderów przez wybranie wywołania rysowania z jednego z naszych przebiegów renderowania i przejście do sekcji Vertex Shader lub Fragment Shader w panelu Pipeline.
Znajdziesz tu przydatne statystyki pochodzące z analizy statycznej kodu shadera, a także standardową przenośną reprezentację pośrednią (SPIR-V), do której skompilowaliśmy nasz GLSL. Jest też karta, na której można wyświetlić reprezentację oryginalnego kodu GLSL (z nazwami zmiennych, funkcji itp. wygenerowanymi przez kompilator), który został zdekompilowany za pomocą SPIR-V Cross, aby zapewnić dodatkowy kontekst dla SPIR-V.
Analiza statyczna
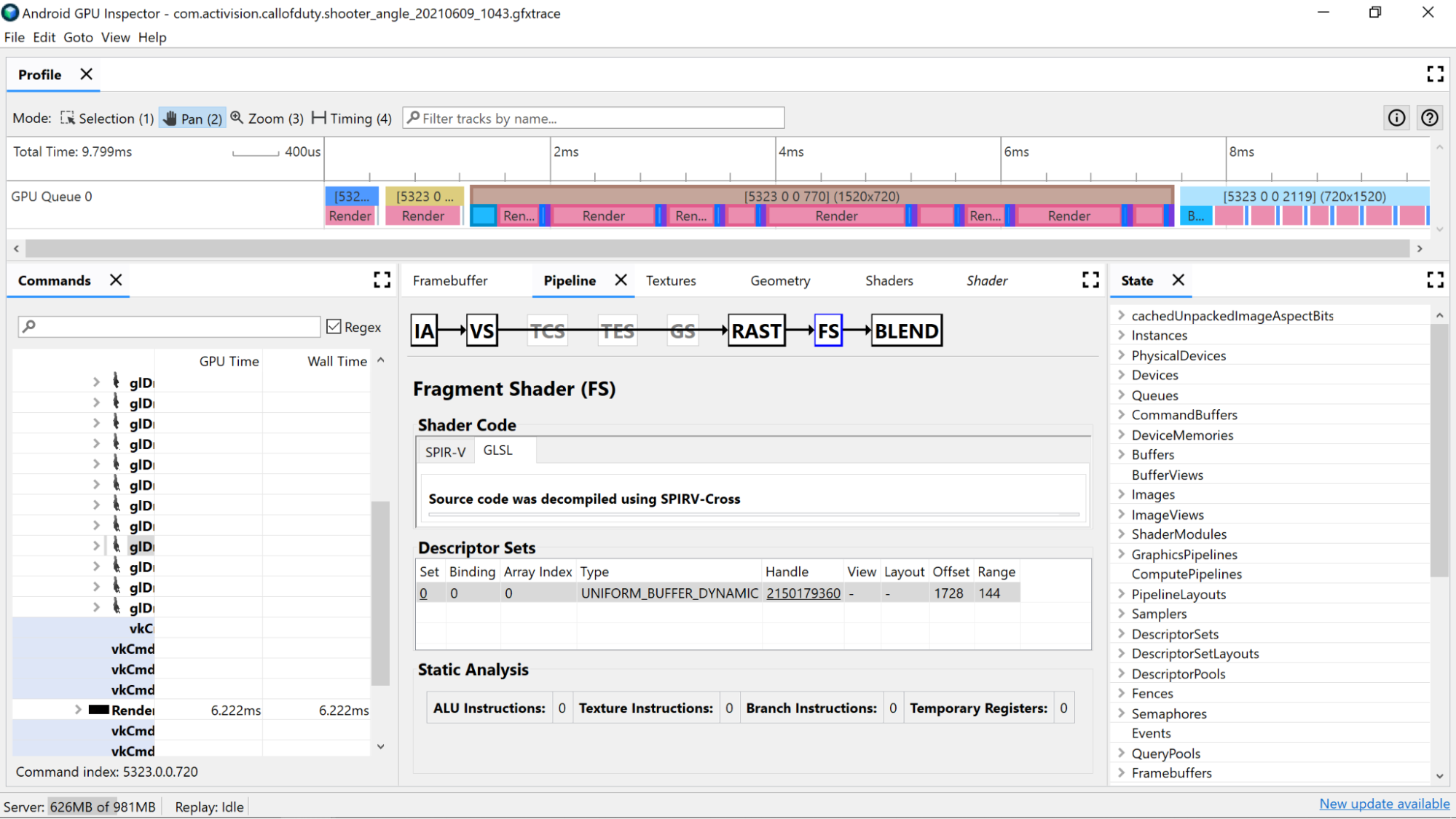
Użyj liczników analizy statycznej, aby wyświetlić operacje niskiego poziomu w cieniowaniu.
Instrukcje ALU: ta liczba pokazuje, ile operacji ALU (dodawanie, mnożenie, dzielenie itp.) jest wykonywanych w cieniowaniu. Jest to dobry wskaźnik złożoności cieniowania. Staraj się minimalizować tę wartość.
Refaktoryzacja typowych obliczeń lub uproszczenie obliczeń wykonywanych w cieniowaniu może pomóc zmniejszyć liczbę potrzebnych instrukcji.
Instrukcje dotyczące tekstury: ta liczba pokazuje, ile razy w cieniu następuje próbkowanie tekstury.
- Próbkowanie tekstur może być kosztowne w zależności od typu tekstur, z których pobierane są próbki. Porównanie kodu shadera z powiązanymi teksturami znalezionymi w sekcji Zbiory deskryptorów może dostarczyć więcej informacji o rodzajach używanych tekstur.
- Unikaj losowego dostępu podczas próbkowania tekstur, ponieważ nie jest to idealne rozwiązanie w przypadku buforowania tekstur.
Instrukcje rozgałęzienia: ta liczba pokazuje liczbę operacji rozgałęzienia w cieniowaniu. Minimalizowanie rozgałęzień jest idealne w przypadku procesorów równoległych, takich jak GPU, a nawet może pomóc kompilatorowi w znalezieniu dodatkowych optymalizacji:
- Używaj funkcji takich jak
min,maxiclamp, aby uniknąć rozgałęziania wartości liczbowych. - Sprawdź koszt obliczeń w przypadku rozgałęzienia. W wielu architekturach wykonuje się obie ścieżki rozgałęzienia, więc w wielu przypadkach zawsze szybsze jest wykonanie obliczeń niż pominięcie ich za pomocą rozgałęzienia.
- Używaj funkcji takich jak
Rejestry tymczasowe: są to szybkie rejestry w rdzeniu, które służą do przechowywania wyników operacji pośrednich wymaganych przez obliczenia na GPU. Liczba rejestrów dostępnych do obliczeń jest ograniczona, zanim GPU będzie musiał użyć innej pamięci poza rdzeniem do przechowywania wartości pośrednich, co zmniejsza ogólną wydajność. (Ten limit różni się w zależności od modelu GPU).
Liczba używanych rejestrów tymczasowych może być wyższa niż oczekiwana, jeśli kompilator cieniowania wykonuje operacje takie jak rozwijanie pętli. Warto więc porównać tę wartość z kodem SPIR-V lub zdekompilowanym kodem GLSL, aby sprawdzić, co robi kod.
Analiza kodu shadera
Sprawdź zdekompilowany kod shadera, aby określić, czy można wprowadzić jakieś ulepszenia.
- Precyzja: precyzja zmiennych shadera może mieć wpływ na wydajność procesora graficznego aplikacji.
- W miarę możliwości używaj modyfikatora precyzji
mediumpw przypadku zmiennych, ponieważ zmienne 16-bitowe o średniej precyzji (mediump) są zwykle szybsze i bardziej energooszczędne niż zmienne 32-bitowe o pełnej precyzji (highp). - Jeśli w shaderze nie widzisz żadnych kwalifikatorów precyzji w deklaracjach zmiennych ani u góry shadera z symbolem
precision precision-qualifier type, domyślnie używana jest pełna precyzja (highp). Sprawdź też deklaracje zmiennych. - Używanie
mediumpw przypadku danych wyjściowych shadera wierzchołków jest również preferowane z tych samych powodów, co opisane powyżej. Ma też tę zaletę, że zmniejsza przepustowość pamięci i potencjalnie wykorzystanie rejestrów tymczasowych potrzebnych do interpolacji.
- W miarę możliwości używaj modyfikatora precyzji
- Bufory jednolite: staraj się, aby rozmiar buforów jednolitych był jak najmniejszy (przy zachowaniu zasad wyrównania). Ułatwia to obliczenia w pamięci podręcznej i może umożliwić przenoszenie jednolitych danych do szybszych rejestrów w rdzeniu.
Usuń nieużywane dane wyjściowe shadera wierzchołków: jeśli w shaderze fragmentów znajdziesz nieużywane dane wyjściowe shadera wierzchołków, usuń je z shadera, aby zwolnić przepustowość pamięci i rejestry tymczasowe.
Przenieś obliczenia z shadera fragmentów do shadera wierzchołków: jeśli kod shadera fragmentów wykonuje obliczenia niezależne od stanu specyficznego dla fragmentu, który jest cieniowany (lub może być prawidłowo interpolowany), przeniesienie go do shadera wierzchołków jest idealnym rozwiązaniem. Dzieje się tak dlatego, że w większości aplikacji program cieniowania wierzchołków jest uruchamiany znacznie rzadziej niż program cieniowania fragmentów.