
אפשר לאבחן כמה בעיות אפשריות בביצועים שקשורות לקודקודים באמצעות פרופיל של פריימים. בחלונית Commands אפשר לראות את כל קריאות הציור שהמשחק מבצע בפריים נתון, ואת מספר הפרימיטיבים שמצוירים לכל קריאת ציור. כך אפשר לקבל הערכה של המספר הכולל של הקודקודים שנשלחו בפריים בודד.
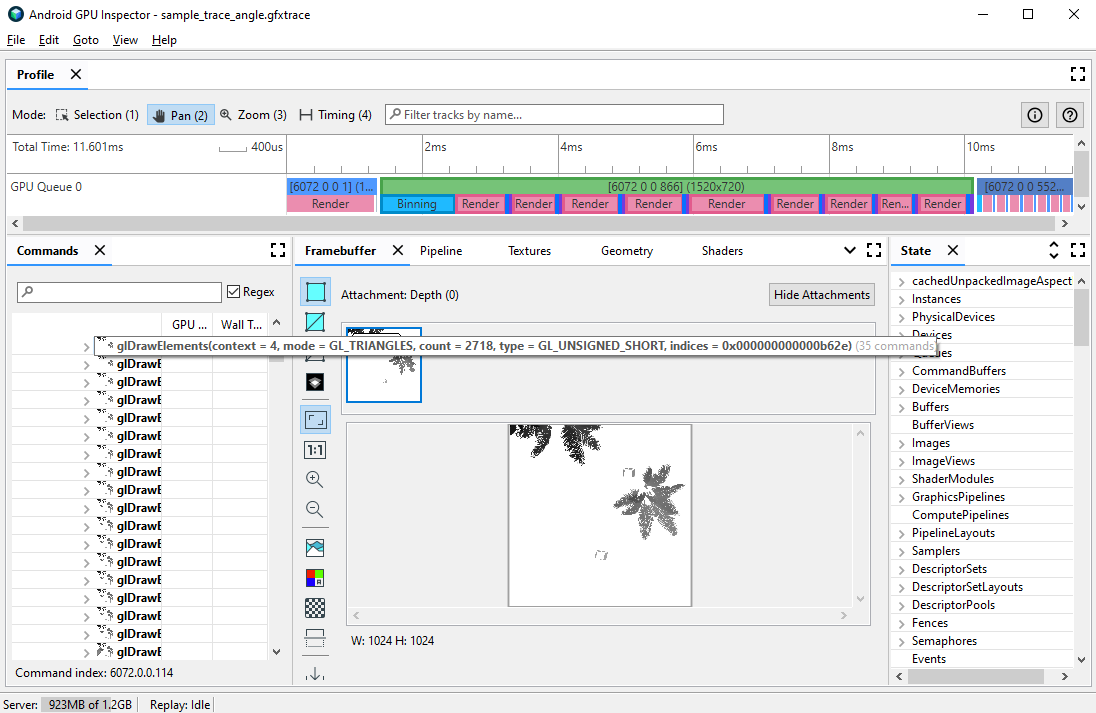
glDrawElements
דחיסת מאפיינים ב-Vertex
בעיה נפוצה במשחקים היא גודל ממוצע גדול של קודקודים. מספר גדול של קודקודים שנשלחים עם גודל קודקוד ממוצע גבוה מוביל לרוחב פס גדול של קריאת זיכרון קודקודים כשקוראים אותם על ידי ה-GPU.
כדי לראות את פורמט הקודקוד של קריאה מסוימת לציור, מבצעים את השלבים הבאים:
בוחרים קריאה לציור שמעניינת אתכם.
זה יכול להיות קריאה רגילה לציור של הסצנה, קריאה לציור עם מספר גדול של קודקודים, קריאה לציור של מודל מורכב של דמות או סוג אחר של קריאה לציור.
מנווטים לחלונית Pipeline ולוחצים על IA כדי להרכיב את הקלט. ההגדרה הזו מגדירה את פורמט הקודקודים של קודקודים שנכנסים ל-GPU.
מתבוננים בסדרה של מאפיינים ובפורמטים שלהם. לדוגמה,
R32G32B32_SFLOATהוא מספר נקודה צפה חתום בן 32 ביט עם 3 רכיבים.
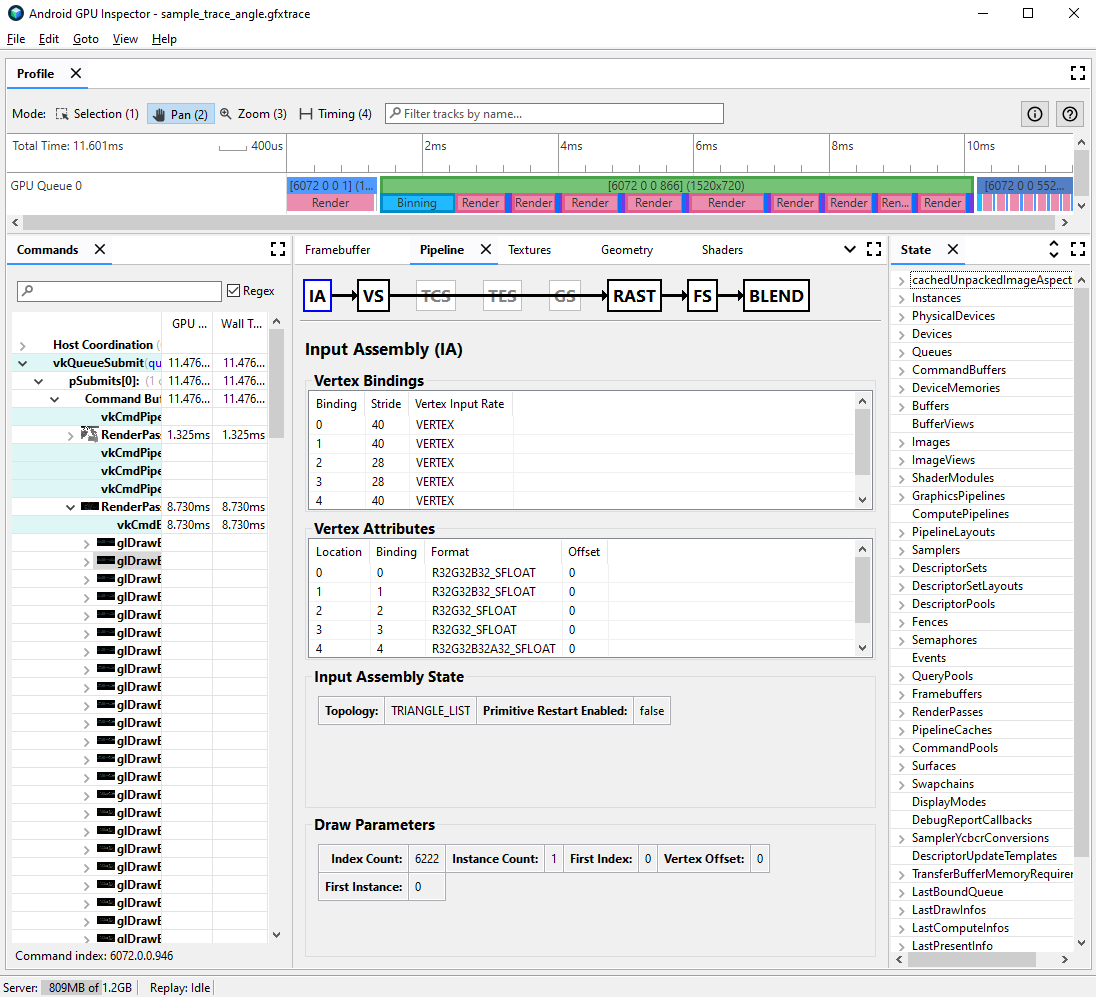
בדרך כלל, אפשר לדחוס מאפייני קודקודים עם צמצום מינימלי באיכות של המודלים שנוצרו. במיוחד, אנחנו ממליצים:
- דחיסת מיקום הקודקוד לנקודות צפות של 16 ביט בחצי דיוק
- דחיסת קואורדינטות של טקסטורת UV למספרים שלמים לא מסומנים של 16 ביט (ushort)
- דחיסת מרחב המשיק על ידי קידוד וקטורים נורמליים, וקטורי משיק ווקטורים בינורמליים באמצעות קווטרניונים
יכול להיות שגם מאפיינים אחרים שונים ייחשבו לסוגים עם דיוק נמוך יותר, בהתאם למקרה.
פיצול של זרם קודקודים
אפשר גם לבדוק אם זרמי מאפייני הקודקודים פוצלו בצורה מתאימה. בארכיטקטורות של רינדור מחולק למשבצות, כמו מעבדי GPU לניידים, המיקומים של הקודקודים משמשים קודם כל בשלב של מיון לתיבות כדי ליצור תיבות של פרימיטיבים שעוברים עיבוד בכל משבצת. אם מאפייני הקודקודים משולבים במאגר יחיד, כל נתוני הקודקודים נקראים למטמון לצורך סיווג, גם אם נעשה שימוש רק במיקומי הקודקודים.
כדי לצמצם את רוחב הפס של הזיכרון לקריאת קודקודים ולשפר את יעילות המטמון, וכך לצמצם את הזמן שמוקדש למעבר binning, צריך לפצל את נתוני הקודקוד לשני זרמים נפרדים, אחד למיקומי הקודקודים ואחד לכל שאר מאפייני הקודקודים.
כדי לבדוק אם מאפייני הקודקוד פוצלו בצורה מתאימה:
בוחרים קריאה לציור שמעניינת אתכם ורושמים את המספר שלה.
זה יכול להיות קריאה רגילה לציור של הסצנה, קריאה לציור עם מספר גדול של קודקודים, קריאה לציור של מודל מורכב של דמות או סוג אחר של קריאה לציור.
מנווטים לחלונית Pipeline ולוחצים על IA כדי להרכיב את הקלט. הפקודה הזו מגדירה את פורמט הקודקודים של קודקודים שנכנסים ל-GPU.
בודקים את הקישורים של מאפייני הקודקודים. בדרך כלל הם עולים באופן לינארי (0, 1, 2, 3 וכו'), אבל זה לא תמיד המצב. מיקום הקודקוד הוא בדרך כלל מאפיין הקודקוד הראשון שמופיע ברשימה.
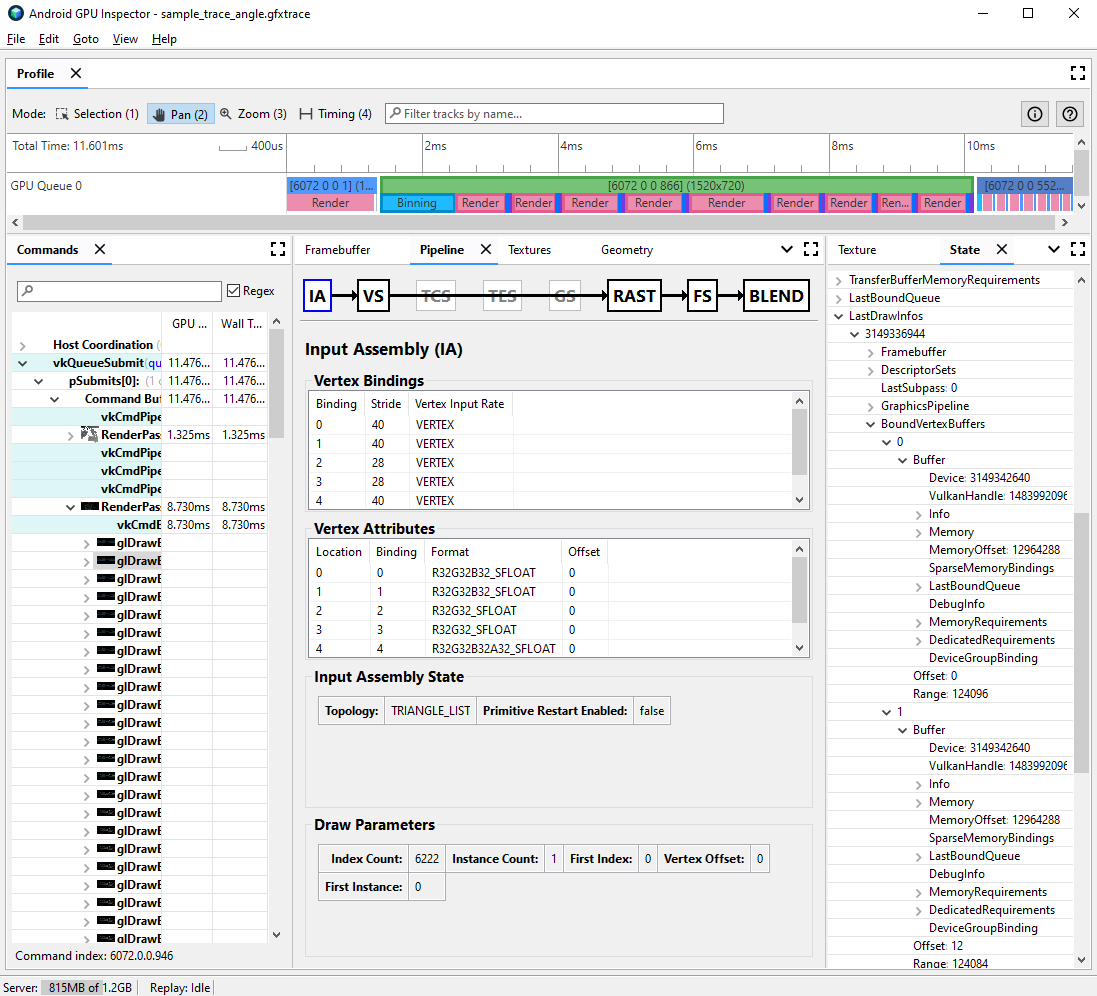
בחלונית State, מאתרים את
LastDrawInfosומרחיבים את מספר ההגרלה התואם. לאחר מכן, מרחיבים אתBoundVertexBuffersעבור קריאת הציור הזו.בודקים את מאגרי הקודקודים שנקשרו במהלך קריאת הציור שצוינה, עם אינדקסים שתואמים לקשירות של מאפייני הקודקודים מהשלבים הקודמים.
מרחיבים את ההתאמות של מאפייני הקודקוד של קריאת הציור, ומרחיבים את המאגרים.
שימו לב ל-
VulkanHandleעבור המאגרים, שמייצגים את הזיכרון הבסיסי שממנו מגיע מקור נתוני הקודקוד. אם הערכים שלVulkanHandleשונים, זה אומר שהמאפיינים מגיעים ממאגרי מידע שונים. אם ערכיVulkanHandleזהים אבל ההיסטים גדולים (לדוגמה, גדולים מ-100), יכול להיות שהמאפיינים עדיין מגיעים ממאגרי משנה שונים, אבל צריך לבדוק את זה לעומק.
לפרטים נוספים על פיצול של זרם קודקודים ועל פתרון הבעיה במנועי משחקים שונים, אפשר לעיין בפוסט בבלוג בנושא.